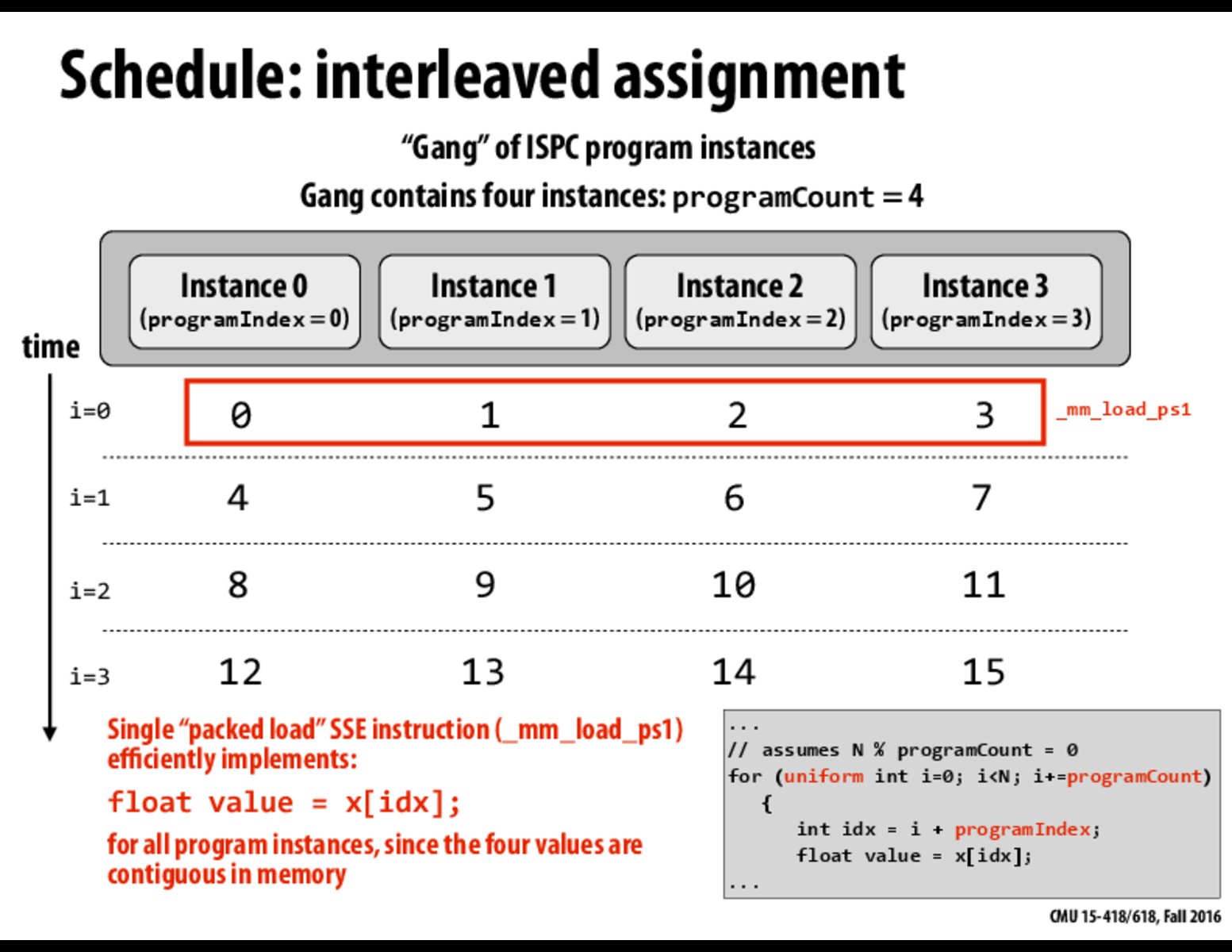
I'm still not quite sure I understand why the interleaved assignment is better than blocked assignment.
chrislee
In the interleaved assignment case, this means that for a given time i, the instances will just have to grab a contiguous chunk of data from the array.
If you read through the text in red on this slide and the next slide, it might make more sense.
TJ
In the time line, we have more cache coherent. As for each time unit, we are fetching the consecutive units of an array.
Besides, from HW 1 experience. There is one more benefit I can think of. If the array or matrix is a image. Then the consecutive pixels (units) are usually quite similar. That leads to a more balanced workload distribution among SIMD units. In this way, we might have more performance speedup.
wxt
It looks to me like the "uniform" keyword, in addition to incrementing i by programCount, is essential to make the four ISPC program instances run like a vector. Is this correct?
fire
I have similar experience with HW1 question 1 part4. For a picture or 2D matrix, it is very hard to have huge difference between speedup using SIMD and speedup with separate workload line by line. I think in real life, pictures that bear huge difference between consecutive lines are very rare. Therefore, SIMD might not have big advantage in these cases. But as Prof. Mowry mentioned, SIMD is somehow better than pthread parallelism in some way. We might experience this difference as the course go further.
I'm still not quite sure I understand why the interleaved assignment is better than blocked assignment.
In the interleaved assignment case, this means that for a given time i, the instances will just have to grab a contiguous chunk of data from the array.
If you read through the text in red on this slide and the next slide, it might make more sense.
In the time line, we have more cache coherent. As for each time unit, we are fetching the consecutive units of an array.
Besides, from HW 1 experience. There is one more benefit I can think of. If the array or matrix is a image. Then the consecutive pixels (units) are usually quite similar. That leads to a more balanced workload distribution among SIMD units. In this way, we might have more performance speedup.
It looks to me like the "uniform" keyword, in addition to incrementing i by programCount, is essential to make the four ISPC program instances run like a vector. Is this correct?
I have similar experience with HW1 question 1 part4. For a picture or 2D matrix, it is very hard to have huge difference between speedup using SIMD and speedup with separate workload line by line. I think in real life, pictures that bear huge difference between consecutive lines are very rare. Therefore, SIMD might not have big advantage in these cases. But as Prof. Mowry mentioned, SIMD is somehow better than pthread parallelism in some way. We might experience this difference as the course go further.