Due: Monday, October 23rd, 2017, 11:59 PM
Final Deadline: Wednesday, October 25th, 11:59 PM
Maximum Late Days: 2
Overview
The purpose of this assignment is to introduce you to parallel programming using MPI. You will solve the same problem as in assignment 3, but using the message passing model rather than a shared memory model.
Environment Setup
You will collect your numbers on the Latedays cluster. Please read the README file to learn about how to submit a job to latedays. The code will be run on Xeon Phi.
More information about running on Latedays can be found in the following link:
http://15418.courses.cs.cmu.edu/fall2016/article/7
You will ssh with the following:
ssh ANDREW_ID@latedays.andrew.cmu.edu
In order to add support for MPI compilation to the GHC machines, add the following to your ~/.cshrc:
setenv PATH $PATH\:/usr/lib64/openmpi/bin
or to your ~/.bashrc:
export PATH=$PATH:/usr/lib64/openmpi/bin
You'll notice that when you log in, you won't be in AFS. This is just fine, untar the starter code in the directory you're in right when you log in or a subdirectory that you create yourself.
Everything you need to know about how to run your code, how to use OpenMPI, and what is provided in the starter code is in the README! Download the starter code from Autolab.
Policy and Logistics
You will work in groups of two people in solving the problems for this assignment. Turn in a single writeup per group, indicating all group members. Any clarifications and revisions to the assignment will be posted on the class \assignments" web page, and also announced via our class Piazza web site.
To get started, download assignment4-handout.tar from Autolab (https://autolab.andrew.cmu.edu) to a directory accessible only to your team. Unpack the handout with:
> tar xzf assignment4-handout.tar.gz
Please make sure you read this document and README file before you start working on the assignment. The README explains how to build, test and handin the code
Introduction: VLSI Wire Routing
You will solve the same problem assignment from assignment 3. Please refer to assignment 3's handout for details of the problem. Input and output les are expected to be in the same format as in assignment 3. The problem should be solved parallelly by distributing the load among the cores available at your disposal. The communication between them will happen using the MPI to coordinate decisions and collectively arrive at an agreeable solution for wire placement.
Your goal is to optimize the performance of the simulated annealing algorithm described in assignment 3.
As a reminder, the algorithm is as follows:
for (iteration = 0; iteration < N_iters; iteration++) {
foreach wire {
with probability P {
select random wire route
} otherwise {
select best wire route
}
}
}
Note that best indicates the lowest cost path, where paths are restricted to having 0, 1, or 2 bends. Default values for Niters (5) and P (0.1) are specified in the starter code and do not need to change.
MPI
We are using the OpenMPI implementation of the MPI programming model. To get started with MPI, here are some websites you may find useful:
http://mpitutorial.com/ contains a brief introduction to MPI.
https://www.open-mpi.org/doc/v1.6/ contains the documentation for the MPI API.
https://www.citutor.org/ contains online courses for MPI and various other topics. Specifically, the Introduction to MPI is relevant. Registration is free.
The handout also provides an example MPI program sqrt3 that approximates sqrt(3).
Ok that was a lot of information! Do not get overwhelmed. It just takes some time to get onboard. For starters, go to the assignment folder in the handout. Read the README file which explains the structure and flow of the code. Peruse through the code and understand the control flow and data flow for all the processors and how they communicate. This is also a good way to familiarize yourself with the MPI constructs available at your disposal for communication. Like the structure of the sqrt program, you will have to do majority of the implementation in the compute function of the wire_route.c file. The number of wire routes, the number of processors and the current processor id are known. Use the algorithm described above to solve the problem statement at hand.
Performance metrics
Metric 1: Computation time
To measure the performance, the starter code measures and prints the total computation time for each MPI process. Each MPI process will print its computation time, and the program's running time is determined based on the maximum across each processes' computation time.
Metric 2: Max cost
We are also interested in the quality of the solution. The primary quality metric is the max cost in the cost array. In VLSI, this determines the number of layers needed to fabricate the chip, and has a large impact on cost.
Metric 3: Sum of squares cost metric
As a secondary quality metric, we are interested in the cost summed for each wire path. This is because the simulated annealing algorithm attempts to minimize this quantity. The metric is calculated as follows:
cost = 0
foreach wire {
cost += cost along wire route
}
Note that this is not the same as adding all the elements in the cost array. Rather, this is equivalent to summing the square (i.e., x * x) of each element in the cost array, hence the name sum of squares cost metric.
Performance analysis
You will be required to also submit a writeup of your findings. As there are many real-world factors that affect the performance of your code, it is important to be able to explain how your code changes a ect performance. For example, if a version of your program exhibits disappointing performance, we would like you to explain what is causing poor performance for that code. We would also like you to explain what you did to x the problem and improve performance. We are especially interested in hearing about the thought process that went into designing your program, and how it evolved over time based on your experiments.
Your report should include the following items:
- A detailed discussion of the design and rationale behind your approach to parallelizing the algorithm. Specifically try to address the following questions:
- What approaches have you taken to parallelize the algorithm?
- What information is communicated between MPI processes, and how does this affect performance? How does communication scale with the number of processes?
- If your implementation operates on stale (or partially stale) data, how does the degree of stale-ness a ect the quality of the solution?
- How does the problem size (in terms of grid size, number of wires, and length of wires) a ect performance?
- At high process counts, do you observe a drop-o in performance? If so, (and you may not) why do you think this might be the case?
- Why do you think your code is unable to achieve perfect speedup? (Is it workload imbalance? communication? synchronization? data movement? etc?)
- A plot of the computation time (metric 1) vs. the number of processors. Please generate separate graphs for 1 node and 2 nodes. Note that each node can run at most 24 processes.
- A plot of the max cost (metric 2) vs. the number of processors. Please explain your results and how it's affected by your design.
- A plot of the sum of squares cost metric (metric 3) vs. the number of processors. Please explain your results and how it's affected by your design.
- Division of e ort: Given that you worked in a group, please identify how you divided the work for this project and how the credit should be distributed among the group members (e.g., 50%-50%, 60%-40%, etc.).
Please include your writeup as writeup.pdf in the root directory of the assignment handout.
Grading
Your grade will be based on the report and the performance and correctness of your code. We will use the performance metrics as described in Section 4. We will run with the three inputs in the wire route/inputs directory of the handout, and we reserve the right to run additional inputs. For your reference, here are the performance metric numbers we obtained with our reference solution:
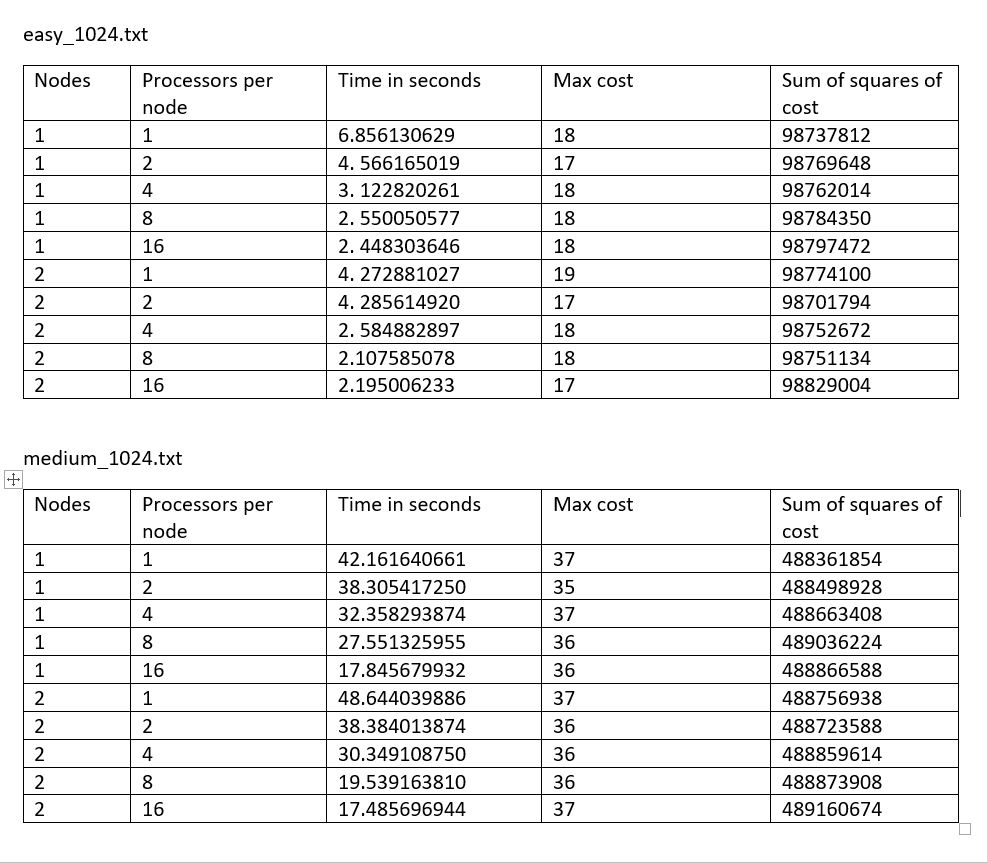
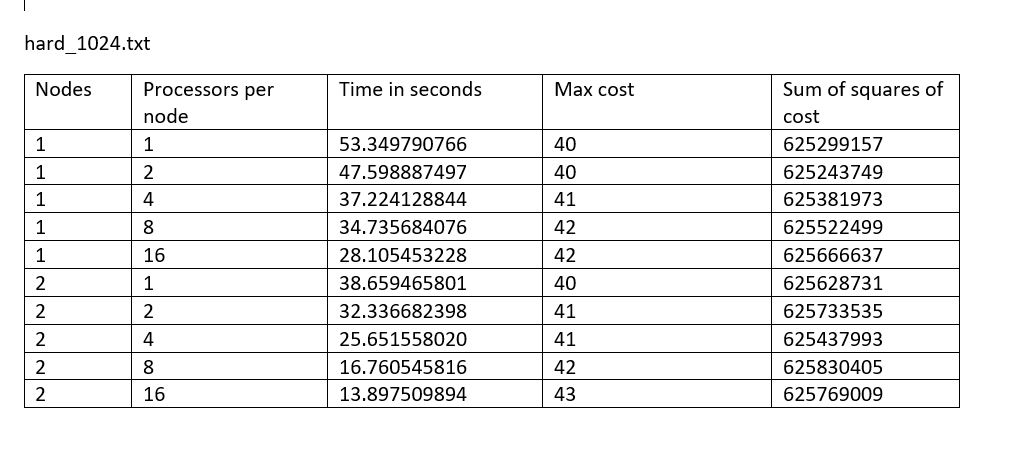
We expect your solution to not be much worse than this baseline solution. Since there is a trade off between the quality of the solution and the computation time, we don't expect your results to match up perfectly, and we are more interested in your thought process on parallelizing the algorithm and the trade offs you make in designing your solution.
Handin instructions
Please run make handin from the handout directory to generate the handin.tar le. It will require you have added your writeup.pdf to the directory. The Make le will run make clean as part of make handin, but please remove any other large les not removed by make clean. Only your code and writeup.pdf are required. Your code should be readable and well-documented. Submit your handin.tar to Autolab (https://autolab.andrew.cmu.edu).