In one sense, FPGAs and ASICs have significantly more parallelism than GPUs. They are just gates. So if you need 1 million adders, then you design that component. Usually, you think about implementing a computation efficiently, and then tiling that component (such as the added previously) until the space is used.
bpr
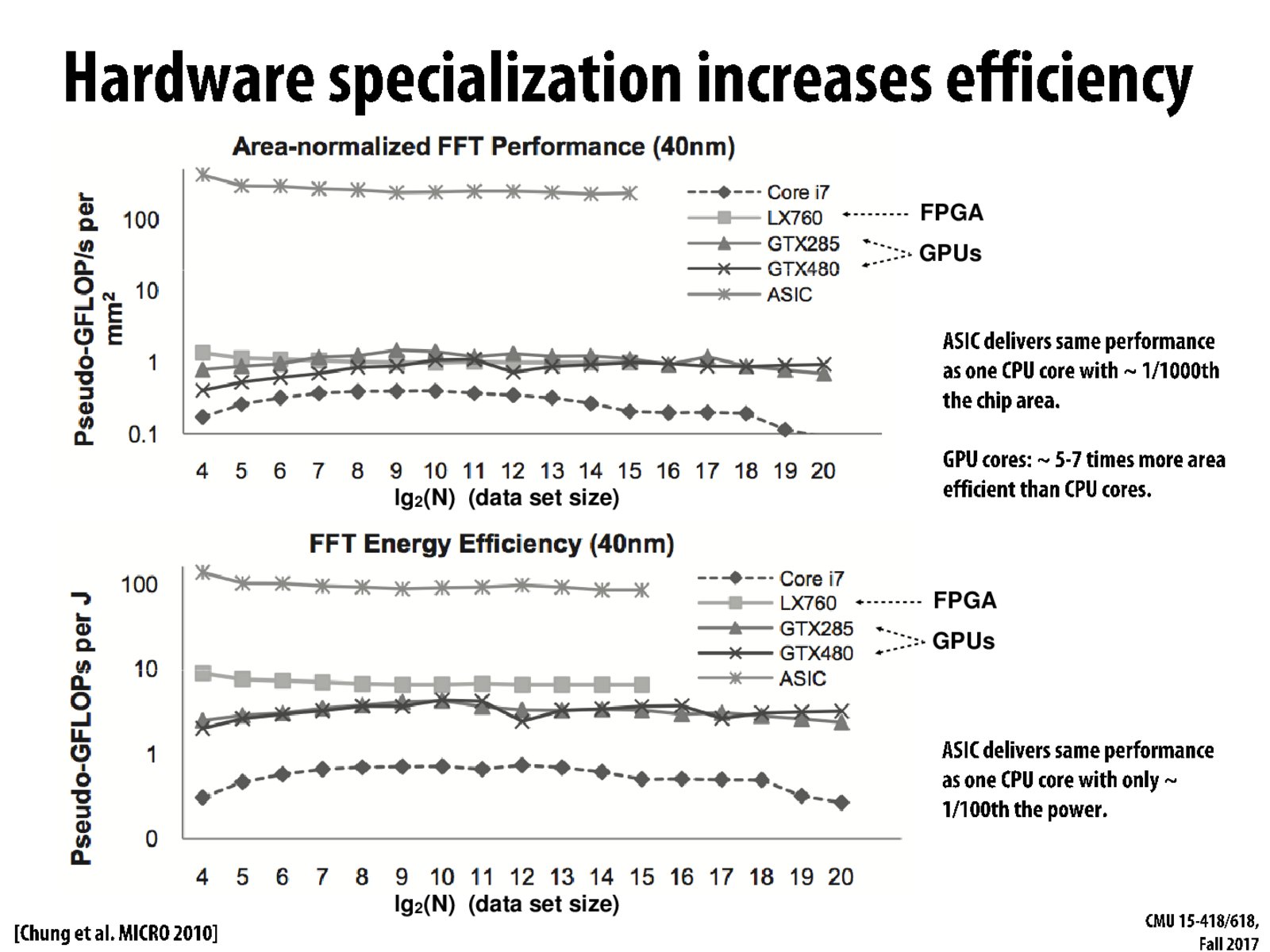
Without looking back at the paper, I suspect that the curves decline due to cache effects. As in, the larger working set reduces the arithmetic intensity, which lowers the GFLOPs.
In one sense, FPGAs and ASICs have significantly more parallelism than GPUs. They are just gates. So if you need 1 million adders, then you design that component. Usually, you think about implementing a computation efficiently, and then tiling that component (such as the added previously) until the space is used.
Without looking back at the paper, I suspect that the curves decline due to cache effects. As in, the larger working set reduces the arithmetic intensity, which lowers the GFLOPs.