Due: Friday April 5, 11:59PM EST
100 points total
Overview
In this assignment you will implement a parallel server that uses a pool of machines to respond to a stream of input requests. Your goal is to respond to all requests as quickly as possible. That is, to minimize your server's response time. However, because running many servers (one way to maintain high performance) can be costly, your server will have the capability to elastically adapt to variations in request stream load. A good implementation of your server will use more machines under times of high load (to minimize response time), and use fewer machines in times of low load (to minimize cost).
Basic Server Architecture
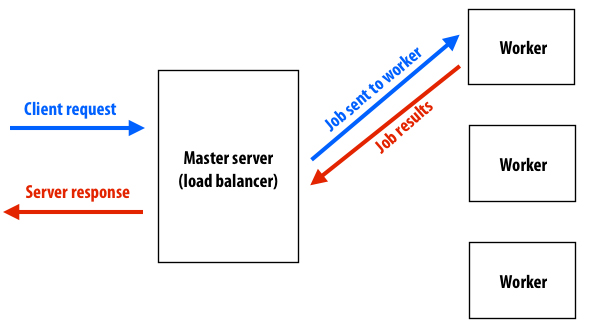
Your server will consist of a "master" node responsible for receiving all input requests, and a pool of "worker" nodes that perform the costly work of executing jobs triggered by client requests. Handling a request will behave as follows.
- The server's master node will receive a request from a client.
- The server's master node will select one or multiple worker nodes to carry out jobs related to the request, and send those jobs to these worker(s).
- The worker node performs the jobs it is assigned by the master, then reports job results back to the master.
- The master nodes collects results from worker(s), and then uses the result to respond to the original client request.
A simple diagram of this setup is shown below:
The Master
The master node is responsible for interpretting incoming requests and generating jobs for workers. In this assignment, the master is a single threaded process that works in an event-driven manner. That is, the master process will call two important functions when key events happen in the system. Your job is to implement both of these functions:
void handle_client_request(Client_handle client, const Request_msg& req);
void handle_worker_response(Worker_handle worker, const Response_msg& resp);
handle_client_request is called by the master whenever a new client request arrives at the web server. A request is provided to your code as a dictionary (a list of key-value pairs: see req.get_arg(key)). Your implementation will need to inspect the request and make decisions about how to service the request using worker nodes in the worker pool. client_handle is a unique identifier for this requestto your server. It is guaranteed to be unique for each call to handle_client_request.
The second function, handle_worker_response is called whenever a worker node reports results back to the master. The response of a worker consists of a tag and a string (see resp.get_tag() and resp.get_response()). The responding worker node is identified by worker_handle (each worker node is given a unique handle which your master learns about in handle_new_worker_online -- see "Elasticity" section below.).
In order to implement your master, you are provided the following library functions.
void send_client_response(Client_handle client, const Response_msg& resp);
void send_request_to_worker(Worker_handle worker, const Request_msg& req);
As you might expect send_client_response sends the provided response stream to the specified client. This client handle should match the client handle provided in the initial call to handle_client_request. send_request_to_worker sends the job described by the key-value pairs in the request object to a worker. Assuming that you have implemented your worker node code properly, the master, after calling send_request_to-_worker should expect to see a handle_worker_response event in the future.
The provided assignment starter code provides a bare-bones server implementation. It is commented in detail to help get you started.
The Worker
You are also responsible for implementing a worker node. To do so, you will implement two functions, that are called by a worker process.
void worker_node_init(const Request_msg& params);
void worker_handle_request(const Request_msg& req);
worker_node_init is an initialization function that gives your worker implementation the opportunity to setup required data structures, etc. worker_handle_request accepts as input a request object (e.g., a dictionary) describing a job. The worker must execute the job, and must send a response to the master. It will do so using the following two library functions.
void execute_work(const Request_msg& req, Response_msg& resp);
void worker_send_response(const Response_msg& resp);
execute_work is a black-box library function that interprets a request, executes the required work in a single thread of control and populates a response. Your worker code is then responsible for sending this response back to the master using worker_send_response.
At this point you may be wondering... since you gave me execute_work, what is there to do in the worker? In this assignment, your worker process will be executing on a machine with a dual-core CPU. Therefore, simply calling execute_work from within worker_handle_request will only use one of the two cores in the system! A good solutions to this assignment will need to effectively utilize all cores on all the worker nodes.
Elasticity
In addition to managing the assignment of request processing to worker nodes, your master node is also responsible for determining how many worker nodes should be used. To add elasticity to your web server, you will implement the following functions:
void master_node_init(int max_workers, int& tick_period);
void handle_tick();
void handle_new_worker_online(Worker_handle worker, int tag);
master_note_init allows to initialize your master implementation. The argument max_workers specificies the maximum number of worker nodes the master can use (requests beyond this limit will be denied). The system expects your code to provide a value for the argument tick_period, which is the time interval (in seconds) at which you'd like your function handle_tick to be called during server operation. handle_new_worker_online is called by the master process whenever a new worker node has booted as is ready to receive requests. (See below for details of how to request more worker nodes.)
Finally, your master implementation can request new worker nodes to be added to its pool (or request that worker nodes be removed from the pool) using:
void request_new_worker_node(const Request_msg& req);
void kill_worker_node(Worker_handle worker);
After calling request_new_worker_node, the system (at some point in the future) will notify your master that the new worker node is ready for requests by calling handle_new_worker_online. Booting a worker is not instantaneous. The requested worker node will not become available to your server for several seconds. In contrast, kill_worker_node will immediately kill a worker. The worker should not be sent further messages after this call, and any outstanding tasks assigned to the worker node are lost. THEREFORE, IT WOULD BE UNWISE TO KILL A WORKER NODE THAT HAS PENDING WORK.
The Incoming Request Stream
To drive your web server, we provide a request generator that plays back traces defined in the /tests subdirectory of the assignment starter code.
Your server must response correctly to three types of requests. As stated above, your worker nodes will use calls to the provided function execute_work to perform these tasks.
418wisdom: This request invokes the "418 oracle", a highly sophisticated, but secret algorithm that accepts as input an integer and uses it to generate a response that conveys great wisdom about how to succeed in 418. Given the sophistication of this algorithm, it is highly CPU intensive.
mostviewed: This request accepts as input two arguments that define a date range and searches a copy of the 15-418 website logs for the most viewed page between those two dates. This request is heavily disk intensive.
countprimes: This request accepts an integer argument n and returns the number of primes up to n. It is CPU intensive. It runtime is also highly variable depending on the value of n. Smaller values of n result in cheaper requests.
compareprimes: This request accepts as input four arguments: n1, n2, n3, n4. It responds with the string "There are more primes in the first range" if there are more primes in the range n1-n2. Otherwise, it responds with "There are more primes in the first range". This request is unique in that your server will need to craft a response from four invocations of the library function execute_work (For more detail, see function execute_compareprimes in src/myserver/worker.cpp). For all other requests your code can simply forward the response produced by execute_work back to the client.
Running a test server on the GHC machines
Performance tuning and grading for this assignment will be performed by running your server on multiple in Amazon's Elastic Computer Cloud (EC2). However, for convenience and simpler testing you are able to run your entire server (both the master and any worker nodes) on a single machine in the GHC clusters. (We recommend the GHC 3000 machines (ghc27-50.ghc.andrew.cmu.edu) since these machines have six cores, and thus can easily handle running the testing harness, your master process, and two multi-threaded worker processes on a single box.
From the asst4 starter code root directory, build the code and run a simple test using the following command:
./run.sh 1 tests/hello418.txt
This will drive the server using a request stream defined in tests/hello418.txt. (The server in the starter code supports only one outstanding request and uses one worker node.) The request stream defined by tests/hello418.txt contains two requests to the 418 oracle, spaced out by 2 seconds. The test file, shown below, contains a list of requests, the expected server response, and the time at which the request is issued during the test (relative to the test start time).
{"time": 0, "work": "cmd=418wisdom;x=1", "resp": "OMG, 418 is so gr8!"}
{"time": 2000, "work": "cmd=418wisdom;x=11", "resp": "If all else fails... buy Kayvon donuts"}
{"time": 4000, "work": "cmd=lastrequest", "resp": "ack" }
You will see the following output:
Waiting for server to initialize...
**** Initializing worker: my worker 0 ****
Server ready, beginning trace...
Request 0: req: "cmd=418wisdom;x=1", resp: "OMG, 418 is so gr8!", latency: 1407 ms
Request 1: req: "cmd=418wisdom;x=11", resp: "If all else fails... buy Kayvon donuts", latency: 1367 ms
Request 2: req: "cmd=lastrequest", resp: "ack", latency: 0 ms
--- Results Summary ---
[0] Request: cmd=418wisdom;x=1, success: YES, latency: 1370
[1] Request: cmd=418wisdom;x=11, success: YES, latency: 1370
*** The results are correct! ***
Avg request latency: 1370.35 ms
Total test time: 3.37 sec
Workers booted: 1
Compute used: 3.40 sec
No grading harness for this test
The test script produces a convienient report about the correctness and latency of each response from your server. Other request streams for testing are provided in the /tests directory of the assignment starter code. Tests used for assignment grading will also produce a report giving your grade for the test.
Getting Started
The assignment 4 starter code is available at: /afs/cs/academic/class/15418-s13/assignments/asst4.tgz
- The code you will edit in this assignment is in the directory
src/myserverin the assignment tarball. You may change anything you wish in the starter code in this directory, but you should not change any other code. We recommend that you begin by skimming through the provided starter code insrc/myserver/master.cppandsrc/myserver/worker.cpp. - Next, we recommend you improve your server implementation so that it correctly handles all the request streams located in the
tests/directory. The starter code does not provide correct results for these tests. - Once you have a correct server, then consider how to improve the server's performance. Ideas might include using more workers or parallelism within a worker node.
- At this point it is time to begin understanding the behavior of the traces. Understanding your workloads will be very important in this assignment.
Assignment Rules
Although we offer you significant flexibility to implement this assignment however you choose, there are a number of rules we would like you to abide by in order to maintain the intended spirit of the assignment:
- If you wish to take advantage of multi-core parallelism in this assigment you are to use pthreads. (Recall your use of threads for the web proxy assignment in 15-213.)
- We ask that you do not spawn multiple threads of control in your master node implementation. We'd like you to stay with the single-threaded, event-based design of the system. You are more than welcome, and in fact encouraged (see point one above), to spawn threads to enable parallel execution in your worker implementations.
- You may only call
execute_workfrom worker nodes. That is, you should think of the master node as a load balancer that is primarily responsible for scheduling/distributing work associated with client requests and potentially combining results from various worker nodes. The "heavy lifting" to service requests should be performed by workers. Implementing caching logic within the master node (and/or the worker nodes) is acceptable. - Yes, there are faster ways to compute primes. Please use the implementation in
execute_work.
Running your server in a multi-machine configuration on Amazon AWS
Details on how to run your server in a 4-worker configuration on Amazon are here.
Grading
This assignment is worth 100 points. The assignment writeup is worth 20 points. The remaining 80 points depend on the correctness and performance of your server. While the correctness of your server will be tested using traces not provided to you, the performance of your server will be graded using these six traces in the assignment tarball:
tests/grading_compareprimes.txt (13 points)
tests/grading_nonuniform1.txt (15 points)
tests/grading_nonuniform2.txt (13 points)
tests/grading_nonuniform3.txt (13 points)
tests/grading_burst.txt (13 points)
tests/grading_random.txt (13 points)
For each test, 3 points are awarded for a correct solution (You receive 0 points for the test is your server returns incorrect results). The remaining 10 points (12 in the case of grading_nonuniform1.txt) depend on your server's performance. A detailed explanation of how each test is graded for is output with your score by the test script itself. For most tests, your goal is to keep response time under a specified threshold while minimizing the number of server's used.
Hand-in Instructions
Hand-in directories have been created at:
/afs/cs.cmu.edu/academic/class/15418-s13/handin/asst4/<ANDREW ID>/
Remember: You need to execute aklog cs.cmu.edu to avoid permission issues.
- Please submit your writeup as pdf file named
writeup.pdf. Note - while you must hand in your code, your writeup should include a description of your final algorithm and experimentation that is sufficiently detailed so that we are convinced you know how it works and so that we do not have to read your source code to understand what you did. - Please submit the contents of your
src/myserverdirectory inhandin.tar.gz. Unlike previous assignments, you are to ONLY submit the contents of this directory.
Hints and Tips
- When running on Amazon, your worker nodes will be running on dual-core CPUs. When developing and testing on the GHC machines you mind want to keep in mind the capabilities of the Amazon systems.
- In the 'src/asst4include/tools/' directory we have provided you a thread-safe shared work queue (see
work_queue.h) and an accurate timer (seecycle_timer.h). You are not required to use any of this functionality but it may be helpful to you. - There may be opportunities for caching in this assignment.
- Achieving the highest performance will require some thought about the best assignment of jobs to worker nodes.
- Parallelism across requests is one obvious axis of parallelism in this assignment. Are there any other opportunities for parallelism?
- The costs of communication between server nodes is likely not significant in this assignment. We have specifically designed the client requests to require substantial amounts of processing, rendering communication overheads largely insignificant.