Locks
Busy Waiting ("Spinning") and Blocking
Busy waiting, or spinning, refers to the situation where one thread's resources are utilized solely in checking for a particular condition to be through (in a while loop). Both compute time and power are wasted here since we do not actually require the processor to be running this check. In fact, spinning is more preferable to blocking primarily for performance reasons. A common blocking example is a pthread mutex lock; blocking, as in this example, refers to assigning the thread to some queue if it does not have access to the lock and then removing one of the threads from this queue as soon as lock is made available. The OS is involved in providing access to a particular thread and as a result, we have a strain on performance (which is not the case in spinning).
Implementation
To get started, here is a simple, but incorrect implementation:
lock: ld R0, mem[addr] // load word into R0
cmp R0, #0 // if 0, store 1
bnz lock // else, try again
st mem[addr], #1
unlock: st mem[addr], #0
The following trace demonstrates the problem with this lock
Time Thread 0 Thread 1
0 val = *lock
1 val = *lock
2 if (val == 0)
3 if (val == 0)
4 *lock = 1
5 *lock = 1
The main problem occurs because of the interleaved execution of the threads. Both threads check whether the lock is free in an interleaved manner, and both "obtain" the lock.
Test and Set lock
The Test and Set instruction (ts) atomically loads the given memory address and sets the value at the memory address to be one. We can now write a test-and-set lock as follows:
lock: ts R0, mem[addr] // load word into R0
bnz R0, #0 // if 0, lock obtained
unlock: st mem[addr], #0 // store 0 to address
In the simple but incorrect lock, the main problem was that there was a gap between obtaining the lock and updating the lock's status. The test-and-set instruction allows the thread to atomically obtain the lock and update its status. Therefore, a thread reads in a zero if and only if the lock is available, and the thread reas in a one if and only if the lock is unavailable.
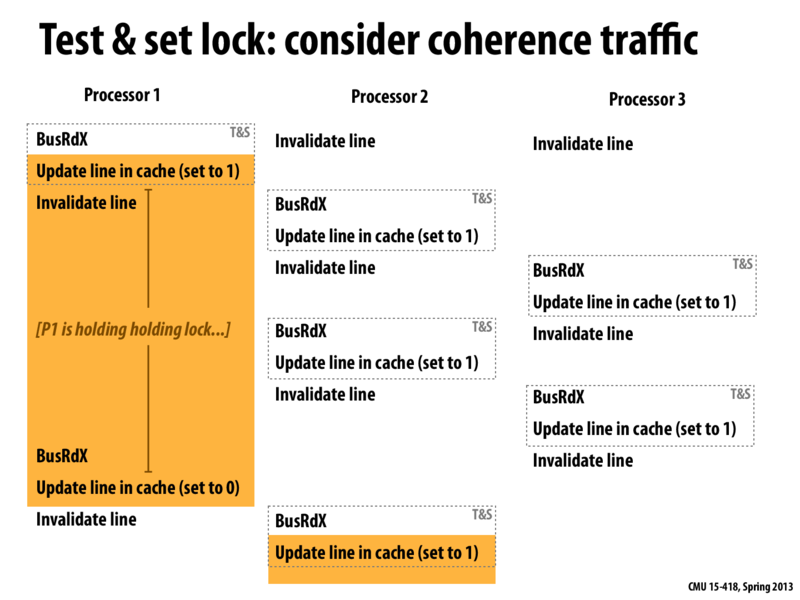
Now that we have a correct implementation, we can consider performance. The above diagram shows three processors all contending for the same lock. The Y-axis is time. Each processor is performing a test and set lock. In this case, processor 1 gets access to the lock first. Now, all other processors invalidate their cache lines according to coherance protocol. Processors 2 and 3 will keep executing test and set to try and again access to the lock. Every time processor 2 or 3 executes test and set, it askes for exclusive access to the memory address, grabs that cache line (which forces everyone else to drop it), writes a 1, and reads that another processor already has the lock. This processes repeats over and over again, until the first processor gives up the lock.
Test and Test and Set Lock
In the Test and Test and Set Lock, we test the lock just by reading the memory until it becomes free. Then we attempt to take the lock by executing test and set. The Test and Test and Set lock is an improvement on the Test and Set lock because reading from memory ("while (*lock != 0)") does not require exclusive access on the cache. Thus there is almost no bus contention when the lock is taken. We only have bus contention when the lock becomes free. When this occurs, some number of threads will attempt to execute a test and set instruction and one will get it.
void Lock(volatile int *lock) {
while (1) {
while (*lock != 0);
if (test and set(*lock) == 0)
return;
}
}
void Unlock(volatile int *lock) {
*lock = 0;
}
The following diagram describes the bus contention for a Test and Test and Set Lock:
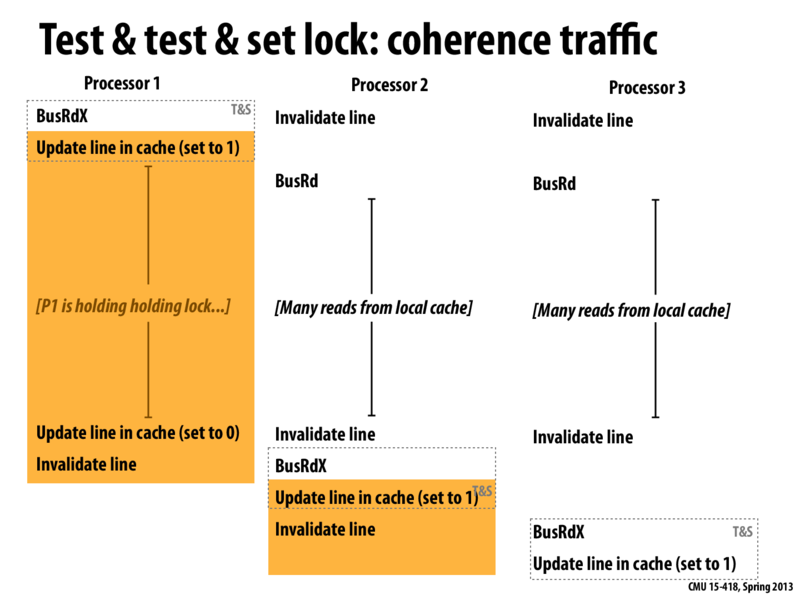
We begin with Processor 1 aquiring the lock. P1 issues a BusRdX to gain exclusive access to the lock, runs a test and set instruction, and aquires the lock. Then P2 and P3 attempt to aquire the lock. They both execute BusRd as they are stuck in the
while (*lock != 0);line of the lock. When the lock becomes free, both P1 and P2 will have the line in their cache invalidated (since P1 writes to the lock), then they will both issue BusRdX to execute the test and set instruction.
They key here is that reading the lock reads from the processor's local cache This results in much lower bus contention than the simple test and set lock.
Characteristics of the Test and Test and Set Lock
- Higher latency than test and set in uncontended case (extra test) When aquiring the lock, we will perform an extra test before aquiring the lock (in contrast with the test and set lock). So when the lock is free, it will take an extra instruction to take the lock. Thus higher latency.
- Lower bus traffic
Let P be the number of processors waiting on the lock. When the lock becomes
free, all of them will try to gain access to the lock:
- O(P) invalidations (of cache lines)
- O(P^2) traffic This is still less traffic than the test and set lock though since we only get this cost when the lock becomes free. The test and set lock has this cost at all times.
- More scalable As the number of processors waiting on the lock increases, the penalty due to bus contention becomes more of a problem. Since test and test and set locks result in lower overall bus traffic, they are more scalable.
- Storage cost unchanged Both test and set and test and test and set locks only use an integer.
Questions:
- Explain the idea of busy waiting and why blocking may be preferable.
- Explain two instances where blocking might actually be preferable to busy waiting.
- Differentiate between the Test and Set Lock and the Test and Test and Set Lock.
 xs33
xs33A Test and Set Lock sets the memory address every iteration in the loop until the lock is free while a Test and Test and Set Lock only reads the memory address in every iteration until the lock is free.
This comment was marked helpful 0 times.
- Is there a method or methods of locking that get better performace than Test and Test and Set lock? What do these methods sacrifice in order to improve perforamce.
 snkulkar
snkulkarTicket Lock can have better performance than Test & Test & Set Lock, but it has a tradeoff of higher latency and higher storage costs.
This comment was marked helpful 0 times.
Blocking might be more preferable to busy waiting if the processor's resources are needed to complete other tasks while the one process is waiting for a resource to become available and if scheduling overhead is low compared to the expected wait time.
This comment was marked helpful 0 times.