The FAWN project implements a distributed hash table which uses a cluster of "wimpy" computers to increase energy efficiency while still maintaining non-wimpy service.
Problems Motivating FAWN:
The IO gap: CPUs on server machines can process lookup requests much faster than disks can provide the actual data to satisfy the processed requests. This leads to SAXPY-style stalls where CPUs waste energy idly waiting for data to come in from IO devices.
Non-linear CPU power consumption vs speed: As discussed in the first lecture, the exhaustion of simple speedup techniques for CPUs means that ever smaller gains in CPU speed come at the cost of ever larger power consumption. This is different from the previous point: even when not idling, brawny CPUs are less energy efficient than wimps.
Non-linear CPU power scaling vs speed: It would be ideal if CPUs could simply scale down when idling. However, modern CPUs can't actually do this linearly. Additionally, even if CPU down-scaling were linear or better, fast CPUs need nonscalable components like big motherboards and big memory in order to saturate them. As a result, the FAWN paper reports that a CPU at 20% speed still requires 50% power.
FAWN Solution
FAWN attempts to address these inefficiencies by "balancing" CPU speed against IO throughput. It services requests using machines with weak CPUs which should only process requests about as fast as the IO bottleneck can provide the data. This increases efficiency by reducing idle waste and by providing the super-linear "scale-down" of wimpy CPUs compared to brawny ones.
One way to think of this is that, at the cost of extra total overhead work, a FAWN system breaks up sequential IO work into parallel IO work.
FAWN Architecture
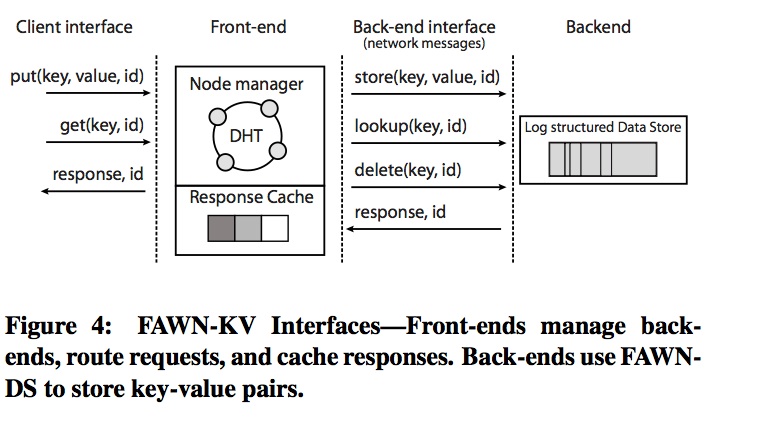
FAWN maps keys to values in a distributed fashion. It has a familiar (P4) two-layer design:
FAWN-DS (Data Store) is the lower layer, which runs in parallel on many worker nodes. A FAWN-DS node contains the actual key-value data pairs for some subset of the total keys which the system manages.
FAWN-KV (Key Value) is the top level interface which services client requests. A FAWN-KV node keeps track of which DS nodes hold the data for which keys, and provides work-balancing, caching, and, theoretically, scaling. The algorithm may run on a single master node or it may run in parallel on multiple nodes at the cost of extra work in maintaining a coherent picture of the system topology. The original paper found that a KV:DS ratio of 1:80 was ideal.
Each DS node is composed of a weak processor, a limited amount of RAM, and 4GB of flash storage.
FAWN-KV Details
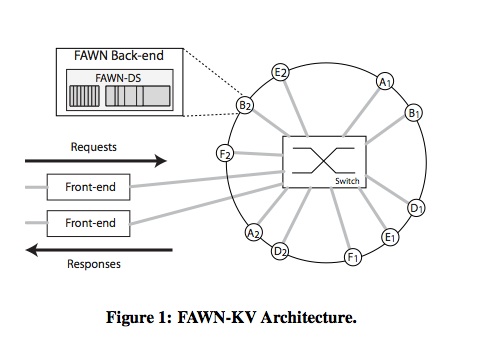
Where the entire system maps keys to values, FAWN-KV internally maintains a sub-mapping of DS nodes to ranges of keys. It uses a variant of a peer-to-peer distributed hash table algorithm called CHORD to do this. The idea is such: it arranges the space of all possible keys in a imaginary circle (so circle[KEY_MAX + 1] == circle[KEY_MIN]) and places nodes at various points on the circle. The range of keys represented by the arc of the circle from node A to node B is the set of keys to which node A is mapped.
The benefit of non-P2P CHORD over a simple hash table is unclear (comments, anyone?). Without talking to Dave or looking at code, we think that it would allow guaranteed O(1) addition of deletion of nodes as well as guaranteed O(n) space if it were implemented as a linked list.
FAWN's implementers experimented with using non-wimpy KV nodes. Specifically, they found that 100% wimpy clusters would get crushed when some keys in the key-value store were significantly more popular than others. This was a problem because key-value stores are very commonly used on applications like social networks, where most traffic is requesting a small number of very popular pieces of information. Regardless of the hash function chosen, a small number of nodes would be hit extremely hard, while others idled. This led to poor throughput, since the system was bottlenecked by the intentionally wimpy processors on each of the nodes.
The solution was to move to a tiered, heterogeneous architecture. The project added a single, powerful computer that acted as a load balancer and large cache. This worked well because the adversarial behavior that hit the wimpy nodes hard was trivially easy to cache (since a few popular items are being accessed most).
FAWN-DS Details
Each DS implements a subset of the complete global mapping of keys to to values. Special care had to be taken in choosing algorithms, because flash memory is generally poor at small random writes. However, there are advantages to flash which offset this. Flash memory is much faster at random reads than magnetic hard drives and significantly more energy effecient.
The datastore is a log-structured key-value store, and is designed to work well on flash. All writes to the datastore occur sequentially, since random writes are slow on flash. This is accomplished by keeping an in-DRAM hash table, mapping keys to an offset in the append-only log on flash.
Each entry in the in-DRAM hash table stores a fragment of the key, the size of the data, and a pointer to the data item on flash. No actual data is stored in memory, so as a result each bucket in DRAM is only about 6 bytes big. To access a key in the system, we first take a 15-bit fragment of the large key, and find the right bucket on the right wimpy node's in-DRAM hash table. Then we go through each of the buckets that match (there could be more than one match because cuckoo hashing might require some searching), and find the right entry. Then we can just read the data off of flash storage using the pointer into flash provided by the hash table.
To insert a new data item, FAWN will simply append to the in-memory hash table, and add the new data item to flash in the same manner. If the same key is inserted with different value, FAWN simply writes over the old entry in the hashtable, and leaves the old data item in flash, to be garbage-collected later. To delete the system simply invalidates a hash table entry, and again leaves the data in flash for cleanup later.
Finally, there is the compact operation, which acts as the garbage collector of the log system. When nodes split their datastore, compact operates by going over the log structure of a data store and invalidating keys which fall outside the range of the nodes key values.
The algorithm behind consistent hashing between nodes is known as Cuckoo hashing, an O(1) hashing scheme that has high utilization. Each object hashed has k different slots it can be in, determined by k different hash functions. Typical refinements to this include having b buckets per slot. By using k=2 and b=4, known as 2-4 cuckoo hashing, 95% utilization of the table is achieved. Additionally, by sizing buckets so that 4 buckets fit into a line cache, extra performance is gained.
In the case of 2-4 cuckoo, lookup is done by calculating the two possible keys from the two hash functions and then looking in all the buckets within the slots assigned to those two keys. Insertion is a bit more complex. If one of the buckets in the two slots is empty, the new item is placed within the free bucket. However, if all the buckets from the two slots are full, then one of the items in these buckets is selected and it is kicked out of the slot and inserted into the slot corresponding to it's other hash function that doesn't map to the slot the algorithm is trying to insert into.
FAWN DS uses a variant of Cuckoo hashing called optimistic Cuckoo hashing. This variant is a concurrent hashing solution, requiring no mutex to access the table. Accomplishing this changed how items were hashed. In the original implementation, insertion required moving items in a bucket until each item moved down one spot. By just searching a bucket instead and placing items in the next open spot, reads are able to happen with writes.
Results
In 2008 FAWN was found to be 6x more power-efficient than traditional systems. FAWN-like systems are now actually found in data centers.
FAWN is an example of an application where multiple classes of processors needed to be used to take the most advantage of all of the processors. This draws parallels with SOCs found on mobile devices, where power requirements necessitate a large number of small, highly-specialized processors to perform with low power.
Follow-up questions
- Why would a large number of caches on the wimpy nodes not be as effective as one large cache in the front-end?
- Can you come up with a key distribution that would be difficult to cache and still hit only hit a few wimpy nodes hard?
- What sort of applications would do better if all nodes in the system had powerful processors/lots of memory (in terms of requests/joule)?
- Discuss the tradeoffs in throughput and communication you would need to make when choosing between an extremely large, WIMPy system and a smaller, heterogeneous cluster.
- Why is using flash (this is different and much slower than SSDs) a better idea than using normal magnetic hard drives in this instance?
- Why does FAWN try to increase I/O bandwidth and not improve latency? Is one approach potentially more profitable than the other?