Overview
Lecture 13 introduced the following:
- Basics about memory consistency and its difference between memory coherence.
- Four memory operations ordering constraints.
- Several memory consistency models.
In order to write correct and efficient program in a parallel system, it is important for the programmers to understand how memory behaves with respects to different memory operations from multiple processors. More precisely, each memory operation should reflect the changes by the last memory operation. In a uni-processor system, the idea of the "last" memory operation is intuitively follow the order of the memory operations appeared in the program. However, when different programs reside and run on different processors, the notion of orders appear in the programs become blurred as the orders between programs are hard to define. This situation give the raise to this lecture's discussion regarding to memory consistency and various memory consistency models.
We will mainly explain the reasoning behind relaxed consistency and compare and contrast from of the tradeoffs between different models.
What is Consistency
Sequential Consistency
Consistency refers to the order processors read and write memory. Consistency is important as it guarantees intuitive and expected program behavior. The most intuitive model is the sequential consistency model, which ensures the total ordering of reads and writes. This means all memory operations must complete according to how they were issued (this model is also sometimes called the Von Neumann model). The easiest way to implement this model is to serialize all memory accesses. However, memory reads and writes can take prohibitly long time, so this model can easily bocome the bottleneck of the system.
Relaxed Consistency
This is mitigated by relaxed consistency. In this model, certain orderings are violated, but memory utilization can be greatly improved. Different models of relaxed consistency allows different violations, which results in different programming pitfalls.
Models of Relaxed Consistency
Total Store Ordering
This memory consistency model relaxed the write-read constraint. The write does not need to be finished before read to a given location takes place. More intuitively, this model allows the read operation to take place before the write finishes and thus allowing read operations to bypass pending write operations took place before them. However, the Bold(write operations) need to be completely in order as in the sequential consistency model. Imagine the memory has a buffer for all the pending write operations and these write exit the buffer in a FIFO order.
Problem:
When P1 issues a write, the read operations issued by P2 may not see that the data is already changed by a write operation from P1. In this case, P1 sees the changes by its write operation earlier than P2. Therefore, synchronization is required for reading data in the shared memory.
Processor Consistency
Processor Consistency (PC) is a lot similar to TSO described above. The difference between the TSO and PC is that TSO will not allow any processor to see the changes of a write unless the write is seen by all the processor. PC allows any processor to see the change before the write is seen by all the processor. PC is a more relaxed consistency model than TSO.
Partial Consistency
Partial Store Ordering (PSO) is a more relaxed memory consistency model compare to the Total Store Ordering (TSO). PSO is essentially TSO with one additional relaxation to the consistency: PSO only guarantees writes to the same location is in order whereas writes to different memory location may not be in order at all. The processor may rearrange writes so that a sequence of write to memory system may not be in their original order.
Comparing the Models
TSO VS PC
To make the difference between TSO and PC memory consistency model more clear to the reader, here is an example:
Consider the following 2 programs in the lecture slides. Assume both program all value is initialized to 0.
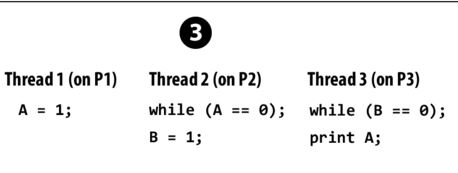
In the above program, the TSO will match the output of the sequencial consistency model wheres the PC will not.
TSO: Thread 2 will not exit the while loop before thread 1 write A to be 1. Thread 2 will only exit the loop after the write by thread 1 is observed by both thread 2 and 3. Same goes for write B to be 1. Therefore, the print A will guaranteed to print 1.
PC: After thread 1 set A to be 1, thread 2 can exit the loop and set B to be 1. In PC, it is possible that thread 3 will not see A updated to be 1 but instead observed that B is updated to be 1. In this situation, the print A will print 0.

In this program, both TSO and PC will not match the output of the sequencial consistency model. For both TSO and PC, the read from the print statement can happen in any order as the read can be out of order for both model.
Hardware VS Software implementation and Performance
Sequential Consistency:
This is the simplest model to implement for both hardware and software. For software, the programmer does not have to worry about out of order instruction and each instruction will be executed the exact order as the program order. For hardware, all instruction can be simply put into an FIFO queue and each instruction will guarantee the order. This model is the most intuitive model compared to the rest of relaxed consistency model.
On the other hand, as discussed above, the sequential consistency model has a great potential to be optimized if the some constraints can be relaxed. This model is perform the worst compare to the rest of relaxed consistency model.
Relaxed Consistency Model (TSO, PC, and PSO):
The relaxed consistency model require extra effort from both the hardware designer and programmer to ensure the correctness of the program. Extra synchronization techniques such as locks and memory barriers are required to be put in place to help ensure correctess.
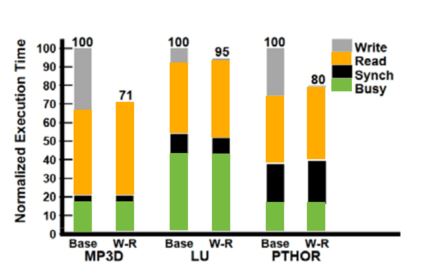
On the other hand, while increasing difficulties to implement, these models provide performance increases. As indicated in the graph below, the write latency is almost hidden compared to the sequencial model.