Barriers
A barrier is a method to implement synchronization. Synchronization ensures that concurrently executing threads or processes do not execute specific portions of the program at the same time. When a barrier is inserted at a specific point in a program for a group of threads [processes], any thread [process] must stop at this point and cannot proceed until all other threads [processes] reach this barrier.
Barrier Implementation

Above is an example of an implementation of a barrier from lecture 18, slide 23. Upon entering the barrier, each processor must first obtain the lock protecting the counters and the flag. arrive_counter is a count of how many processors have entered the barrier and leave_counter is a count of how many processors have exited the barrier after finishes. flag is set to 0 when the barrier is in effect and 1 otherwise.
A processor entering the barrier first checks if arrive_counter is 0. If so, this means that it is the first processor entering the barrier. It then needs to check if the leave_counter is equal to P. If it is, we know that no other threads are in the barrier so we can mark the barrier as being in effect by setting the flag to 0. If leave_counter is not P, we release the lock and loop until it is equal to P. This is because if leave_counter is less than P, it must be the case at least one processor is still in a previous barrier. If we did not ensure all processors had left the previous barrier with leave_counter, it would be possible to have deadlock since the processor in the previous barrier could continue looping on while(b->flag == 0); and never leave the previous barrier if we reset the flag to 0 before it notices the previous barrier ended. In that case arrive_counter would never equal P since the processor from the previous barrier would not increment it. In lecture 18, slide 22 you can see an incorrect barrier implementation that has this problem.
Once we know no processors are in a previous barrier, we can set the flag. Then we increment arrive_counter since we have arrived in the new barrier.
If we are the last arriver (i.e. arrived == p), we reset the arrive_counter is 0 and set the leave_counter to 1 since we are leaving the barrier. Additionally we set the flag to 1 to indicate the barrier is over. If we are not the last processor, we loop until the last arriver sets the flag to 1 and then atomically increment leave_counter so we correctly count how many processors have left the barrier.
Sense Reversal
An important detail about barrier implementations is that because they use counters to track the number of processors or threads which have arrived at the barrier, they must be reset after all of the processors or threads leave.
In the aforementioned centralized barrier, there are two places in the code where the processors potentially have to busy-wait for other threads in the barrier. The following centralized barrier implementation incorporates sense reversal, an optimization which incorporates a local variable to each processor which allows the terminal state of one exit from the barrier to act as the initial state for a subsequent entry.
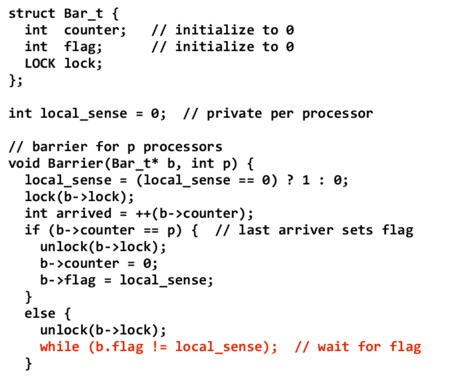
There are a number of differences between this and the previous implementation. First, note that the barrier structure has a single counter, as opposed to an arrive counter and a leave counter. Also, a local_sense variable is introduced. This variable is private to each processor and is initialized to 0 (the initial value is irrelevant, but it is important that each processor has the same initial value for the variable). local_sense is used in the barrier function to check whether all of the processors have arrived at the barrier, and can only take one of two values (0 or 1).
The barrier is implemented as follows. When a processor enters a barrier, the value of local_sense is set to 1 if the previous value was 0, and 0 if the previous value was 1. The processor then increments the counter in the barrier, and checks if all of the processors have arrived at the barrier. In the case that all processors have not yet arrived, the processor spins on the condition that the flag field of the barrier is not equal to the private local_sense variable. Otherwise, if the processor is the last processor to arrive at the barrier, the counter is reset to 0, and the flag is set to local_sense. At this point, the other processors will exit their while loops.
Sense reversal is correct and does not deadlock in the case of even and odd numbered barriers (e.g. some processors enter a second barrier while others are still leaving the first one), because the exit condition (b.flag != local_sense) for two consecutive barriers will be different (0 in one, and 1 in the other).
Thus, this optimization reduced the number of processors spinning, and reduces the number of accesses to the shared barrier variable.
Combining Trees
One problem with a centralized barrier is that there is high contention for the barrier. This is illustrated in the following figure (left):
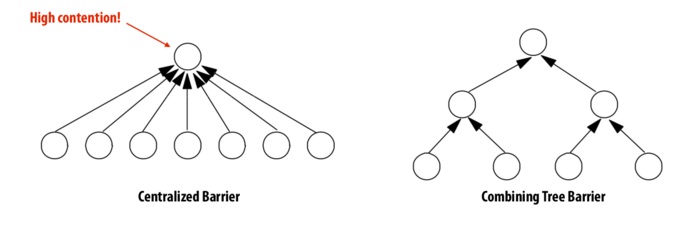
We see that in this case, contention causes O(P) latency where, P is the number of processes. One way to remedy this problem is to use Combining Trees (right), which better exploit parallelism in interconnect topologies. When a process arrives at a barrier, it performs an atomicIncr() operation on it's parent's counter until the process recurses to the root. In order to release, each parent, beginning from the root, will notify it's children. The latency in this case is O(lg(P)).
Questions
- Can there exist a scenario where the processors are either entering or exiting three different barriers?
- Name an example scenario where you might use a barrier.
- What are some specific examples of interconnect topologies that would allow for the use of Combining Trees?
- Would the barrier implementation given in this article have any issues in a non-sequentially consistent memory system?