Since locks are bad due to high contention, the system first devotes some time to coloring the graph to find which nodes can be done in parallel. This is especially applicable in the domain that this language is built for (makes sense) because often the meshes are not dynamic (like the wings of a plane for example). Thus doing the calculation once initially can drastically speedup any number of iterations after the fact.
This comment was marked helpful 0 times.
kayvonf
To be more precise:
Rather than attempt a solution that used fine-grained synchronization to ensure atomicity of updates to shared edge or shared vertex values, this solution performs extra computation up front to compute subsets of the graph than can safely be computed in parallel without any fine-gained synchronization. Of course, there is still synchronization: there will be a barrier between the phases of parallel computation (each phases operates on nodes with the same color). If the extra work of the graph coloring computation is less than the cost of fine-grained synchronization (certainly the case on the modern GPU platforms Liszt targeted), then this is a better way to organize the parallel computation.
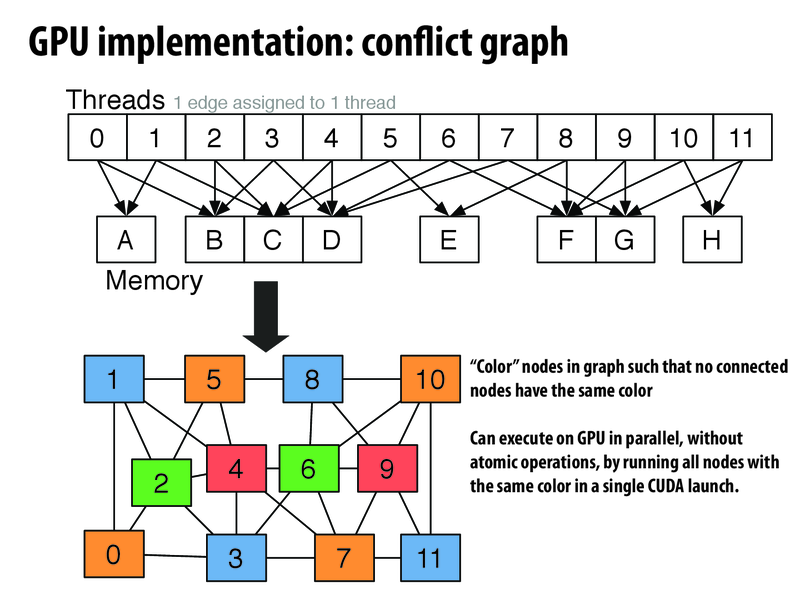
Since locks are bad due to high contention, the system first devotes some time to coloring the graph to find which nodes can be done in parallel. This is especially applicable in the domain that this language is built for (makes sense) because often the meshes are not dynamic (like the wings of a plane for example). Thus doing the calculation once initially can drastically speedup any number of iterations after the fact.
This comment was marked helpful 0 times.
To be more precise:
Rather than attempt a solution that used fine-grained synchronization to ensure atomicity of updates to shared edge or shared vertex values, this solution performs extra computation up front to compute subsets of the graph than can safely be computed in parallel without any fine-gained synchronization. Of course, there is still synchronization: there will be a barrier between the phases of parallel computation (each phases operates on nodes with the same color). If the extra work of the graph coloring computation is less than the cost of fine-grained synchronization (certainly the case on the modern GPU platforms Liszt targeted), then this is a better way to organize the parallel computation.
This comment was marked helpful 0 times.