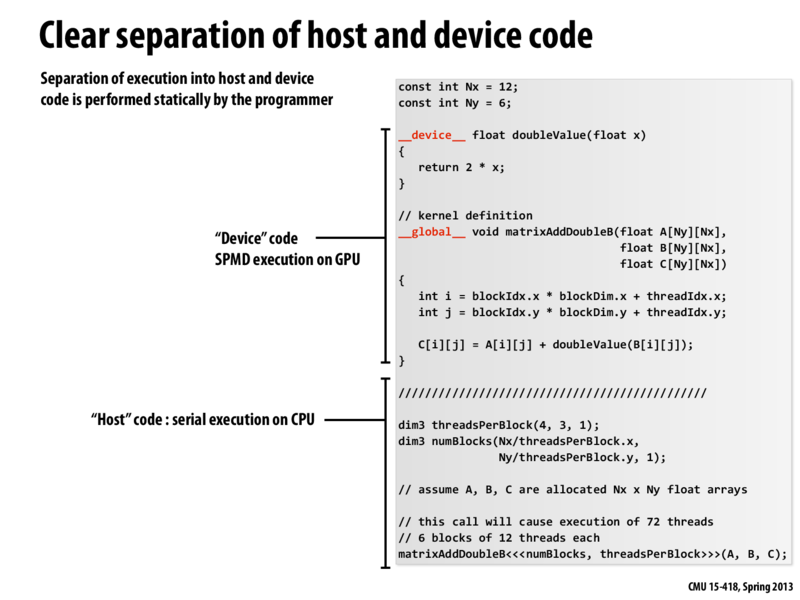
Question: Does the "Host" code and the "Device" code run on separate address spaces? For the saxpy part of assignment 2, I tried to run the code without having done a cudaMemcpy which immediately segfaults which would seem to suggest so.
This comment was marked helpful 0 times.
kayvonf
Yes, you should consider host addresses and device addresses to reside in different address spaces.
I don't believe your code should SEGFAULT provided the device global memory accessed by the CUDA threads is properly allocated. Leaving out the cudaMemcpy should simply skip the transfer of data from the host to the device address spaces. Can you re-check? (And we can potentially take the discussion over the Piazza if there are issues.)
This comment was marked helpful 0 times.
bottie
A summary about the CUDA function declarations:
Executed on
Only callable from
__device__ float DeviceFunction()
device
device
__global__ void KernelFunction()
device
host
__host__ float HostFunction()
host
host
the kernel function is the function that really launch the parallel execution.
Note: a kernel function must return void.
I think this will help to understand the host and device code run in different space address.
This comment was marked helpful 3 times.
sfackler
A function declared without any of __device__, __global__ and __host__ is equivalent to that function declared with only __host__.
This comment was marked helpful 0 times.
jcmacdon
It is also interesting to note that __global__ functions can now be called from the device on devices that have compute capability 3.x (according to the CUDA C Programming Guide).
This comment was marked helpful 0 times.
xs33
Question: Is it bad style to call malloc from a Cuda kernel? Are there any situations where calling malloc would even be encouraged?
This comment was marked helpful 0 times.
kfc9001
@xs33 I'd imagine it would be bad. All the threads in a single warp would start executing malloc in lockstep. However, if you're talking about a device specific malloc that allocates memory out of each thread's local storage, that might be more feasible.
The safer way to do this would obviously be to malloc each thread's storage up front, and then parcel it out to each thread as it runs.
This comment was marked helpful 0 times.
aawright
If you want to write a function that is accessible on both host and device (you might do this for a function like max) you can do this by adding both __host__ and __device__ to the function declaration.
Question: Does the "Host" code and the "Device" code run on separate address spaces? For the saxpy part of assignment 2, I tried to run the code without having done a cudaMemcpy which immediately segfaults which would seem to suggest so.
This comment was marked helpful 0 times.
Yes, you should consider host addresses and device addresses to reside in different address spaces.
I don't believe your code should SEGFAULT provided the device global memory accessed by the CUDA threads is properly allocated. Leaving out the
cudaMemcpyshould simply skip the transfer of data from the host to the device address spaces. Can you re-check? (And we can potentially take the discussion over the Piazza if there are issues.)This comment was marked helpful 0 times.
A summary about the CUDA function declarations:
the kernel function is the function that really launch the parallel execution. Note: a kernel function must return void.
I think this will help to understand the host and device code run in different space address.
This comment was marked helpful 3 times.
A function declared without any of
__device__,__global__and__host__is equivalent to that function declared with only__host__.This comment was marked helpful 0 times.
It is also interesting to note that
__global__functions can now be called from the device on devices that have compute capability 3.x (according to the CUDA C Programming Guide).This comment was marked helpful 0 times.
Question: Is it bad style to call malloc from a Cuda kernel? Are there any situations where calling malloc would even be encouraged?
This comment was marked helpful 0 times.
@xs33 I'd imagine it would be bad. All the threads in a single warp would start executing malloc in lockstep. However, if you're talking about a device specific malloc that allocates memory out of each thread's local storage, that might be more feasible.
The safer way to do this would obviously be to malloc each thread's storage up front, and then parcel it out to each thread as it runs.
This comment was marked helpful 0 times.
If you want to write a function that is accessible on both host and device (you might do this for a function like
max) you can do this by adding both__host__and__device__to the function declaration.This comment was marked helpful 0 times.