This slide gives a big-picture overview of the process for turning a problem into a parallel program.
The decomposition step involves breaking the problem into independent subproblems. More subproblems will increase your maximum potential to parallelize the computation. At this stage, the division of work is based on the constraints of the problem, not yet focusing on the implementation and hardware.
The assignment step involves mapping these subproblems to an abstraction in the program. Examples of this include pthreads, ispc tasks, and CUDA blocks/threads.
The orchestration step involves using some method of communication between tasks. We have discussed shared memory and message passing as options for doing this. As we have seen, communication can lead to tasks waiting to access shared memory or to receive a message, so poorly implemented communication can severely detract from the performance of a program.
Finally, the parallel program is mapped to the hardware it is run on. This varies based on details such as the number of cores, the width of the lane for SIMD execution, and the CUDA warp size. Depending on the method chosen, the programmer may have little control over this step.
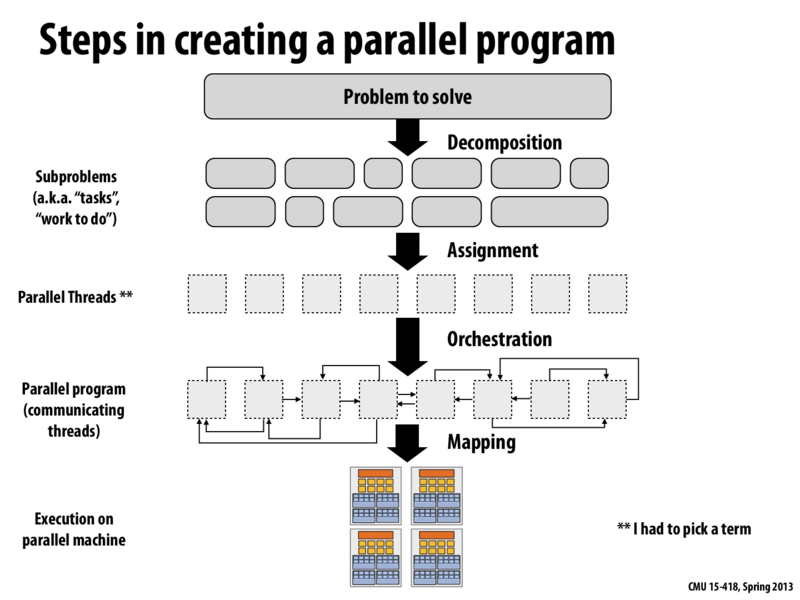
This slide gives a big-picture overview of the process for turning a problem into a parallel program.
The decomposition step involves breaking the problem into independent subproblems. More subproblems will increase your maximum potential to parallelize the computation. At this stage, the division of work is based on the constraints of the problem, not yet focusing on the implementation and hardware.
The assignment step involves mapping these subproblems to an abstraction in the program. Examples of this include pthreads, ispc tasks, and CUDA blocks/threads.
The orchestration step involves using some method of communication between tasks. We have discussed shared memory and message passing as options for doing this. As we have seen, communication can lead to tasks waiting to access shared memory or to receive a message, so poorly implemented communication can severely detract from the performance of a program.
Finally, the parallel program is mapped to the hardware it is run on. This varies based on details such as the number of cores, the width of the lane for SIMD execution, and the CUDA warp size. Depending on the method chosen, the programmer may have little control over this step.
This comment was marked helpful 0 times.