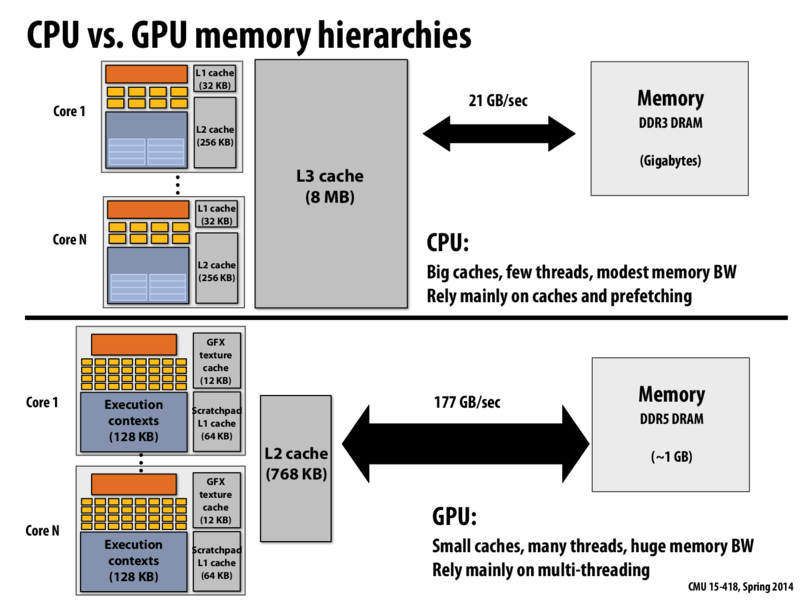
768 = 2^8 * 3. Is there any reason why L2 is that big for GPU or is it just an Empirical result?
This comment was marked helpful 0 times.
rbcarlso
I know some NVIDIA GPUs have 768 KB L2 caches, but I don't know why NVIDIA picked that. I would imagine it's because they intended to minimize the cache size in order to make as much room as possible for cores/ALUs etc. 768 may be the magic number they found that provides physical space on the chip, meets their minimum requirements for memory usage, and works out with powers of two.
This comment was marked helpful 0 times.
kayvonf
Chip architects make decisions by running experiments are real workloads. I suspect that benchmarks showed the for many GPU workloads larger caches had decreasing benefits, and that chip area was better used, as @rbariso suggests, for adding other capabilities.
Question: What mechanisms do GPUs use to avoid performance problems that might arise if a CPU-style processor was attached to such a small last-level cache?
This comment was marked helpful 0 times.
putthatcookiedown
GPU program working sets are typically much larger than CPUs. This is why it makes sense for CPUs to have a large cache and the GPU a small one; the CPU can usually fit the working set into its last level cache whereas this is usually unrealistic for a GPU. GPUs get around this by having massive memory bandwidth. They may not be able to store everything in their cache, but they can access memory fairly easily. Because CPUs have large caches, less die area is spent on a high throughput memory controller. However if a CPU were to be hooked up to a GPU memory system, reasonable performance could probably still be expected due to the massive memory bandwidth, though perhaps not as good as with the typical CPU cache architecture.
This comment was marked helpful 0 times.
kayvonf
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.
wcrichto
The implications depend on the extent to which a reduction in input size correlates to a reduction in latency. For example, if our PCIe bus runs at 16 GB/s, then every transfer to memory could (absent other data) potentially take a full second, but we can run 16B transfers simultaneously. At best, we could run a single transfer in 1/16B seconds. Given that GPUs probably have an average workload equal to the number of pixels in a screen (roughly 1024^2 = 1MB of data), this means it would optimally take 1M / 16B = 1 / 16K, or 16K transfers per second. Since most GPU applications only require at most 60 frames per second, I'd say we're doing pretty well for ourselves even with a bandwidth of 16 GB/S (or worse).
Granted, this is assuming optimal conditions and an average workload. I'm not sure of other use cases for which this might have more dire implications.
768 = 2^8 * 3. Is there any reason why L2 is that big for GPU or is it just an Empirical result?
This comment was marked helpful 0 times.
I know some NVIDIA GPUs have 768 KB L2 caches, but I don't know why NVIDIA picked that. I would imagine it's because they intended to minimize the cache size in order to make as much room as possible for cores/ALUs etc. 768 may be the magic number they found that provides physical space on the chip, meets their minimum requirements for memory usage, and works out with powers of two.
This comment was marked helpful 0 times.
Chip architects make decisions by running experiments are real workloads. I suspect that benchmarks showed the for many GPU workloads larger caches had decreasing benefits, and that chip area was better used, as @rbariso suggests, for adding other capabilities.
Question: What mechanisms do GPUs use to avoid performance problems that might arise if a CPU-style processor was attached to such a small last-level cache?
This comment was marked helpful 0 times.
GPU program working sets are typically much larger than CPUs. This is why it makes sense for CPUs to have a large cache and the GPU a small one; the CPU can usually fit the working set into its last level cache whereas this is usually unrealistic for a GPU. GPUs get around this by having massive memory bandwidth. They may not be able to store everything in their cache, but they can access memory fairly easily. Because CPUs have large caches, less die area is spent on a high throughput memory controller. However if a CPU were to be hooked up to a GPU memory system, reasonable performance could probably still be expected due to the massive memory bandwidth, though perhaps not as good as with the typical CPU cache architecture.
This comment was marked helpful 0 times.
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.
The implications depend on the extent to which a reduction in input size correlates to a reduction in latency. For example, if our PCIe bus runs at 16 GB/s, then every transfer to memory could (absent other data) potentially take a full second, but we can run 16B transfers simultaneously. At best, we could run a single transfer in 1/16B seconds. Given that GPUs probably have an average workload equal to the number of pixels in a screen (roughly 1024^2 = 1MB of data), this means it would optimally take 1M / 16B = 1 / 16K, or 16K transfers per second. Since most GPU applications only require at most 60 frames per second, I'd say we're doing pretty well for ourselves even with a bandwidth of 16 GB/S (or worse).
Granted, this is assuming optimal conditions and an average workload. I'm not sure of other use cases for which this might have more dire implications.
This comment was marked helpful 0 times.