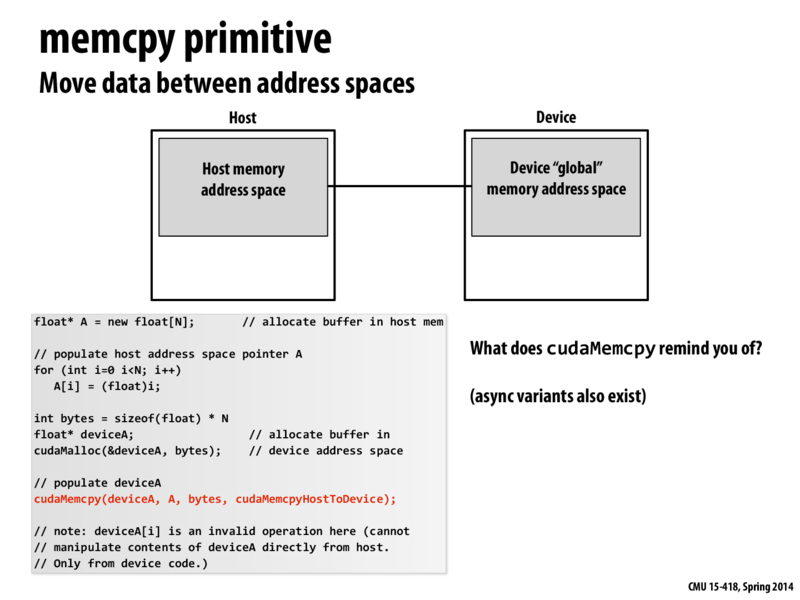
deviceA acts as a handle. The address space of the GPU is (in this example) separate from the CPU's address space, and for this reason, deviceA is a reference.
There is no real reason that deviceA is a float * -- Kayvon mentioned in class that it could have been typedef'd to a more distinguishable type.
This comment was marked helpful 0 times.
kkz
If we were to copy memory from device to host, would we use something along the lines of "cudaMemcpyDeviceToHost" as the 4th param of "cudaMemcpy"?
edit: It indeed looks like we do :)
This comment was marked helpful 0 times.
analysiser
@kkz
I think one of the caveats is "cudaMemcpyDeviceToDevice", if you want to copy from one device address space to another. It seems if the fourth enum value is wrong there would be a segment fault in runtime.
This comment was marked helpful 0 times.
LilWaynesFather
In lecture there was some explanation of why this implementation of cudaMalloc is very "forward looking" but I'm still not completely sure I understand. So the reason why cudaMalloc returns a float* (a pointer pretty much) is that it expects that in the future there will be global shared address space between the cpu (host) and gpu (device). Then we would actually be passing in a pointer for some address in memory. However, since that hasn't happened, the pointer acts like a handle that is used to by cudaMemcpy to copy the message to. The pointer can't actually be accessed like an actual pointer by the host.
cudaMemcpyDefault Default based unified virtual address space
Also, note that cudaMemcpy's first parameter is always destination pointer and second argument is source pointer. It is easy to overlook the fact!
This comment was marked helpful 0 times.
arjunh
It should be noted memory allocated with cudaMalloc can only be 'dereferenced' or 'set' in a kernel function or with a call to cudaMemcpy. Remember that cudaMalloc allocates memory on the device, which is different from the host memory. So, you can't dereference device memory when on the CPU side (host side).
(source: personal mistake; trying to set the last element of the array after the upsweep phase in scan to 0 outside the kernel function/without using cudaMemcpy. This yields a seg-fault, which can be confusing if the distinction between host memory and device memory is not clear).
This comment was marked helpful 1 times.
arjunh
Also, note that the signature for cudaMalloc is cudaError_t cudaMalloc(void **devPtr, size_t size). The reason for using a void** instead of a void* (as you might expect from using malloc/calloc) is that all CUDA functions return an error-code explaining why it failed (if it did). A full explanation is given here
If this is confusing, it's because it is; the same thread mentions that a far better API design would have simply added another argument to the function as a sort of 'error-code storage argument' (quite similar to the int* status argument in the waitpid function, which can be probed to see what caused the process to terminate).
This comment was marked helpful 1 times.
Q_Q
I was on anandtech and I saw that AMD has recently released "HSA," which allows for their integrated CPU and GPU on the same chip to share exactly the same address space, just like Kayvon said. Obviously it's faster to have the GPU and CPU share the same address space because copies aren't required, but also pointed out in what I read was that structures with pointers in them (like linked lists or trees) need to have their pointers rewritten when they get copied to another address space. With one address space that isn't necessary!
deviceAacts as a handle. The address space of the GPU is (in this example) separate from the CPU's address space, and for this reason,deviceAis a reference.There is no real reason that
deviceAis afloat *-- Kayvon mentioned in class that it could have been typedef'd to a more distinguishable type.This comment was marked helpful 0 times.
If we were to copy memory from device to host, would we use something along the lines of "cudaMemcpyDeviceToHost" as the 4th param of "cudaMemcpy"?
edit: It indeed looks like we do :)
This comment was marked helpful 0 times.
@kkz
I think one of the caveats is "cudaMemcpyDeviceToDevice", if you want to copy from one device address space to another. It seems if the fourth enum value is wrong there would be a segment fault in runtime.
This comment was marked helpful 0 times.
In lecture there was some explanation of why this implementation of cudaMalloc is very "forward looking" but I'm still not completely sure I understand. So the reason why cudaMalloc returns a float* (a pointer pretty much) is that it expects that in the future there will be global shared address space between the cpu (host) and gpu (device). Then we would actually be passing in a pointer for some address in memory. However, since that hasn't happened, the pointer acts like a handle that is used to by cudaMemcpy to copy the message to. The pointer can't actually be accessed like an actual pointer by the host.
This comment was marked helpful 0 times.
@kkz Yes that's right and CUDA library doc about cudaMemcpy tells you what other values you can use for 4th parameters.
There are
cudaMemcpyHostToHost Host -> Host
cudaMemcpyHostToDevice Host -> Device
cudaMemcpyDeviceToHost Device -> Host
cudaMemcpyDeviceToDevice Device -> Device
cudaMemcpyDefault Default based unified virtual address space
Also, note that cudaMemcpy's first parameter is always destination pointer and second argument is source pointer. It is easy to overlook the fact!
This comment was marked helpful 0 times.
It should be noted memory allocated with
cudaMalloccan only be 'dereferenced' or 'set' in a kernel function or with a call tocudaMemcpy. Remember thatcudaMallocallocates memory on the device, which is different from the host memory. So, you can't dereference device memory when on the CPU side (host side).(source: personal mistake; trying to set the last element of the array after the upsweep phase in scan to 0 outside the kernel function/without using
cudaMemcpy. This yields a seg-fault, which can be confusing if the distinction between host memory and device memory is not clear).This comment was marked helpful 1 times.
Also, note that the signature for
cudaMallociscudaError_t cudaMalloc(void **devPtr, size_t size). The reason for using avoid**instead of avoid*(as you might expect from usingmalloc/calloc) is that all CUDA functions return an error-code explaining why it failed (if it did). A full explanation is given hereIf this is confusing, it's because it is; the same thread mentions that a far better API design would have simply added another argument to the function as a sort of 'error-code storage argument' (quite similar to the
int* statusargument in thewaitpidfunction, which can be probed to see what caused the process to terminate).This comment was marked helpful 1 times.
I was on anandtech and I saw that AMD has recently released "HSA," which allows for their integrated CPU and GPU on the same chip to share exactly the same address space, just like Kayvon said. Obviously it's faster to have the GPU and CPU share the same address space because copies aren't required, but also pointed out in what I read was that structures with pointers in them (like linked lists or trees) need to have their pointers rewritten when they get copied to another address space. With one address space that isn't necessary!
This comment was marked helpful 0 times.