In this diagram for every access in the DRAM, the entire row is copied to the row buffer. Hence to optimize this memory controllers first reorganize the pending requests before servicing them. One way to reorganize is to service the requests that need data from the row currently in the row buffer.
This can also lead to the problem of starvation for some access patterns as some requests may never be served because of the rearrangement.
This comment was marked helpful 0 times.
spilledmilk
I believe it was discussed during lecture that starvation would be very unlikely because DRAM requests occur only if a memory request misses the last level cache, and therefore, subsequent accesses to the same area of memory would be cached.
Given 8 DRAM chips and striped memory storage, a cache line would take $64 / 8 = 8~\text{bytes}$ in each chip, and because a row of the chip has $2048~\text{bits} = 256~\text{bytes}$, a row could be responsible for a maximum of $256 / 8 = 32~\text{cache lines}$. Therefore, in the worst case, some memory access could be delayed by 32 accesses, and most likely not much more than that because none of those 32 cache lines are likely to get evicted from the last level cache in the time it takes to read in all 32.
This comment was marked helpful 0 times.
bxb
Although unlikely it is possible to have starvation due to unfairness in the DRAM controller. This example was given in the first lecture of Professor Mutlu's 18447 course: given two threads running similar for loops reading/writing two large arrays, differing only in the sequential vs. random access of the arrays, the thread with the sequential access will be prioritized due to its high row buffer locality.
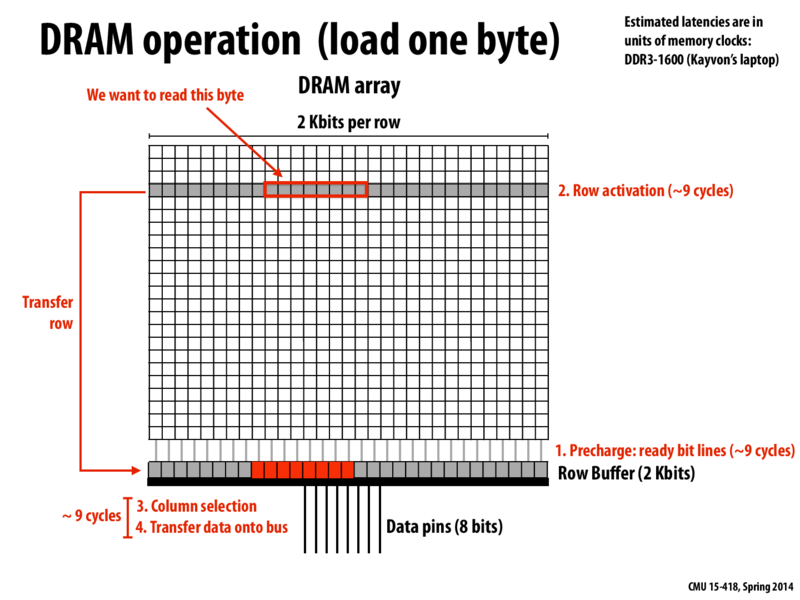
In this diagram for every access in the DRAM, the entire row is copied to the row buffer. Hence to optimize this memory controllers first reorganize the pending requests before servicing them. One way to reorganize is to service the requests that need data from the row currently in the row buffer.
This can also lead to the problem of starvation for some access patterns as some requests may never be served because of the rearrangement.
This comment was marked helpful 0 times.
I believe it was discussed during lecture that starvation would be very unlikely because DRAM requests occur only if a memory request misses the last level cache, and therefore, subsequent accesses to the same area of memory would be cached.
Given 8 DRAM chips and striped memory storage, a cache line would take $64 / 8 = 8~\text{bytes}$ in each chip, and because a row of the chip has $2048~\text{bits} = 256~\text{bytes}$, a row could be responsible for a maximum of $256 / 8 = 32~\text{cache lines}$. Therefore, in the worst case, some memory access could be delayed by 32 accesses, and most likely not much more than that because none of those 32 cache lines are likely to get evicted from the last level cache in the time it takes to read in all 32.
This comment was marked helpful 0 times.
Although unlikely it is possible to have starvation due to unfairness in the DRAM controller. This example was given in the first lecture of Professor Mutlu's 18447 course: given two threads running similar for loops reading/writing two large arrays, differing only in the sequential vs. random access of the arrays, the thread with the sequential access will be prioritized due to its high row buffer locality.
This comment was marked helpful 0 times.