Interesting quote from lecture which summarizes this slide really well --
"We aren't just adding more processors, we are adding more cache memory".
In between 8 - 16 processors, the working set of the grid solver fits within cache memory of each processor. This minimizes the number of cache misses, and these misses all happen in parallel. By avoiding these memory misses, we get "superlinear" speedup.
This comment was marked helpful 1 times.
asinha
Because the working set of the grid solver fits within the cache memory, the number of cache misses is minimized. However, for this to occur the data must have excellent spatial locality in the cache such that it's all excellently packed and accessed so that we don't need to retrieve from the cache often. This situation is a rare occurrence which is why super-linear, while possible, is pretty rare as well.
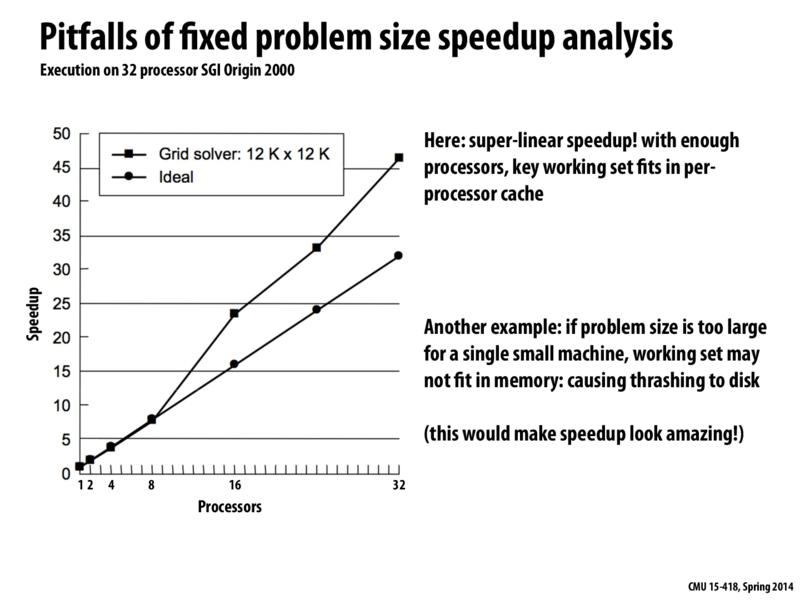
Interesting quote from lecture which summarizes this slide really well --
"We aren't just adding more processors, we are adding more cache memory".
In between 8 - 16 processors, the working set of the grid solver fits within cache memory of each processor. This minimizes the number of cache misses, and these misses all happen in parallel. By avoiding these memory misses, we get "superlinear" speedup.
This comment was marked helpful 1 times.
Because the working set of the grid solver fits within the cache memory, the number of cache misses is minimized. However, for this to occur the data must have excellent spatial locality in the cache such that it's all excellently packed and accessed so that we don't need to retrieve from the cache often. This situation is a rare occurrence which is why super-linear, while possible, is pretty rare as well.
This comment was marked helpful 0 times.