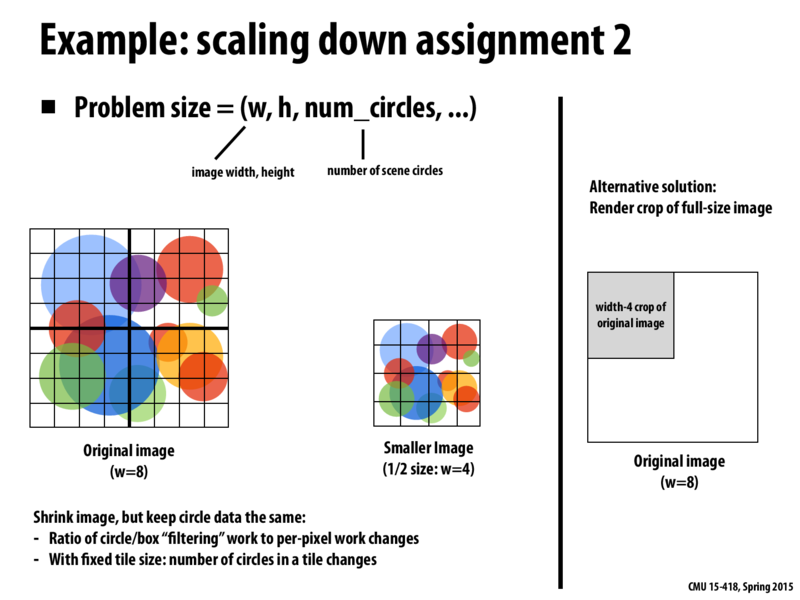
Why does the alternative on the right help us? Are you suggesting that we compute 1/4 of the pixels, but choose a "cropped" section so to have a representative distribution and density of circles?
cube
@lament Yes. Only computing $\frac{1}{4}$ of the picture means that the computation will finish noticeably quicker.
This, at the very least, makes it faster to see if something will work.
The reason you can't just make a shrunken image is because it fundamentally alters things like number of overlapping circles per circle, etc. so it might not be representative of what your original picture will render like.
On the other hand, cropping won't change ratios, but you need to make sure to pick a representative part of the picture to crop.
jezimmer
It seems to me like the idea behind preferring a cropped image over a scaled image is that a cropped one is a better representative of a "random sample." This begs the question, can we just take a random sample, i.e., randomly selecting $\frac{n^2}{4}$ of the $n^2$ pixels.
Some immediate implications of this for the problem at hand:
- You lose basically any sense of locality
- You get a better "representative part" of the image if selecting that part would be otherwise difficult.
- You don't suffer from the reduced overlaps that scaling the problem down gives.
Granted this is still a tradeoff, but if it's hard to scale an arbitrary problem down to a cropped image, it might be interesting to see if choosing pixels randomly helps out.
srw
@jezimmer, I think the idea of a random sample vs a deterministic subset is linked very closely to the idea of dependency. When we talk about taking a uniformly random sample, such as in a statistical survey, we assume that the elements in our sample can be considered independently. For instance, here we could safely consider a random sample of the circles, as those are independent of each other. However, due to cache locality and blocking, pixels are VERY dependent on their neighbors, esp. if you implement assignment 2 well. :P
We already discussed that an excellent way to solve problems on a grid is to create a solution for a fixed block size, and then view that image as a grid of blocks. These blocks are mostly independent, so it's probably okay to consider random subset of them. Then we can decide to take a cropped image (deterministically choose the upper left blocks) or a random sampling of blocks. Since input is generally pretty random anyway, it's probably fine to just take the crop. However, if you were worried about the distribution being biased, you'd definitely want to choose random samples by blocks rather than pixels.
parallelfifths
To reiterate and clarify points made by @cube and @srw, both scaling and cropping will have different drawbacks. If you scale, the ratio of the circle overlap measured in pixels changes, so we have potentially created more dependencies than the original data set had and are thus changing the amount of synchronization free, parallelizable work. If you crop, your overlap ratio of circles will stay the same, but you might risk choosing an unrepresentative section of the image. For example, imagine rendering an image where there is a high density of circles in the lower right and a low density of circles everywhere else. If we choose to test our algorithm on the top left upper quadrant of the image, our test will not be an accurate representation of the time it takes to computer 1/4 of the full image. However, we can avoid this unevenly distributed data problem by computing on several, randomly chosen cropped regions, and thus the drawbacks of cropping are easier to overcome than those of scaling.
admintio42
knowing how to scale down the problem was critical for assignment 2. Too many circles and too many pixels.
Why does the alternative on the right help us? Are you suggesting that we compute 1/4 of the pixels, but choose a "cropped" section so to have a representative distribution and density of circles?
@lament Yes. Only computing $\frac{1}{4}$ of the picture means that the computation will finish noticeably quicker. This, at the very least, makes it faster to see if something will work.
The reason you can't just make a shrunken image is because it fundamentally alters things like number of overlapping circles per circle, etc. so it might not be representative of what your original picture will render like.
On the other hand, cropping won't change ratios, but you need to make sure to pick a representative part of the picture to crop.
It seems to me like the idea behind preferring a cropped image over a scaled image is that a cropped one is a better representative of a "random sample." This begs the question, can we just take a random sample, i.e., randomly selecting $\frac{n^2}{4}$ of the $n^2$ pixels.
Some immediate implications of this for the problem at hand: - You lose basically any sense of locality - You get a better "representative part" of the image if selecting that part would be otherwise difficult. - You don't suffer from the reduced overlaps that scaling the problem down gives.
Granted this is still a tradeoff, but if it's hard to scale an arbitrary problem down to a cropped image, it might be interesting to see if choosing pixels randomly helps out.
@jezimmer, I think the idea of a random sample vs a deterministic subset is linked very closely to the idea of dependency. When we talk about taking a uniformly random sample, such as in a statistical survey, we assume that the elements in our sample can be considered independently. For instance, here we could safely consider a random sample of the circles, as those are independent of each other. However, due to cache locality and blocking, pixels are VERY dependent on their neighbors, esp. if you implement assignment 2 well. :P
We already discussed that an excellent way to solve problems on a grid is to create a solution for a fixed block size, and then view that image as a grid of blocks. These blocks are mostly independent, so it's probably okay to consider random subset of them. Then we can decide to take a cropped image (deterministically choose the upper left blocks) or a random sampling of blocks. Since input is generally pretty random anyway, it's probably fine to just take the crop. However, if you were worried about the distribution being biased, you'd definitely want to choose random samples by blocks rather than pixels.
To reiterate and clarify points made by @cube and @srw, both scaling and cropping will have different drawbacks. If you scale, the ratio of the circle overlap measured in pixels changes, so we have potentially created more dependencies than the original data set had and are thus changing the amount of synchronization free, parallelizable work. If you crop, your overlap ratio of circles will stay the same, but you might risk choosing an unrepresentative section of the image. For example, imagine rendering an image where there is a high density of circles in the lower right and a low density of circles everywhere else. If we choose to test our algorithm on the top left upper quadrant of the image, our test will not be an accurate representation of the time it takes to computer 1/4 of the full image. However, we can avoid this unevenly distributed data problem by computing on several, randomly chosen cropped regions, and thus the drawbacks of cropping are easier to overcome than those of scaling.
knowing how to scale down the problem was critical for assignment 2. Too many circles and too many pixels.