Consider this scheduler in the situation described on slide 36, and assume every execution context is able to hold 4 blocks/tasks. Then even if we schedule the long task first, it will not reduce the "slop", right?
kayvonf
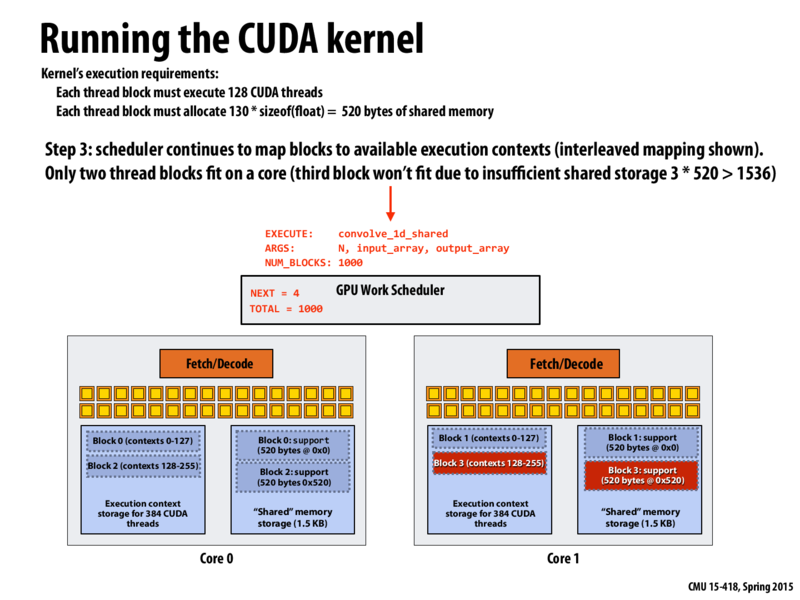
Question: The slide says three thread blocks won't "fit on a core due to insufficient storage". What did I mean by this?
HLAHat
Well, there's enough room to store another block of 128 threads, but since the programmer specified 520 bytes for each block, the system must ensure that there is enough space in the shared memory for that amount of data. In this case, the shared memory is not large enough to allocate 520 more bytes. So the insufficient storage is just the lack of shared memory space.
kayvonf
Question: good answer @HLAHat. So here's a question for everyone. How is the experience of programming with CUDA shared memory the same and/or different than programming a system with a traditional data cache?
aznshodan
Using CUDA shared memory is similar to traditional data cache in a sense that access to data that have been stored/cached is faster than accessing global memory. The difference is that cache is implemented in hardware so the programmer has no control of what to cache and what not to cache. CUDA shared memory on the other hand can be accessed by programmers and, in fact, programmer is responsible for using allocating shared memory and storing data to shared memory(preferably data that are used repeatedly to minimize memory latency).
Consider this scheduler in the situation described on slide 36, and assume every execution context is able to hold 4 blocks/tasks. Then even if we schedule the long task first, it will not reduce the "slop", right?
Question: The slide says three thread blocks won't "fit on a core due to insufficient storage". What did I mean by this?
Well, there's enough room to store another block of 128 threads, but since the programmer specified 520 bytes for each block, the system must ensure that there is enough space in the shared memory for that amount of data. In this case, the shared memory is not large enough to allocate 520 more bytes. So the insufficient storage is just the lack of shared memory space.
Question: good answer @HLAHat. So here's a question for everyone. How is the experience of programming with CUDA shared memory the same and/or different than programming a system with a traditional data cache?
Using CUDA shared memory is similar to traditional data cache in a sense that access to data that have been stored/cached is faster than accessing global memory. The difference is that cache is implemented in hardware so the programmer has no control of what to cache and what not to cache. CUDA shared memory on the other hand can be accessed by programmers and, in fact, programmer is responsible for using allocating shared memory and storing data to shared memory(preferably data that are used repeatedly to minimize memory latency).