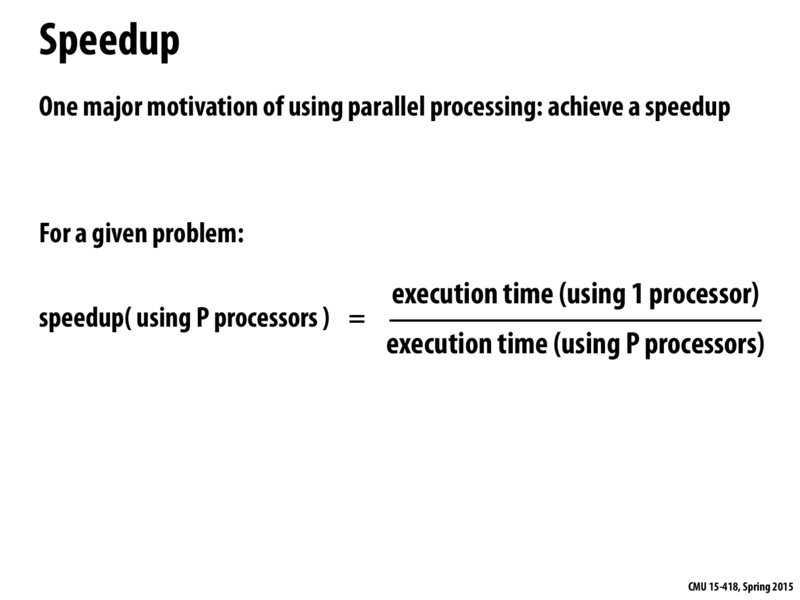
Are we using the same algorithm on both systems, or the fastest algorithm on both systems?
If we had the central number location in a serial adding system, it would be slow to fetch each number, making the parallel speedup artificially greater
How do you make up for algorithmic differences during this comparison? Do you have to make sure the programs have the same worst-case without considering span?
cube
@rflood It's possible I'm misinterpreting your first question, but I don't think it would make a lot of sense to use the same algorithm on both systems, because it would only use 1 processor, in order to be able to run with 1 processor. It would run the same regardless of the number of processors.
EDIT: I guess that you can use the same algorithm by differing the thread assignment, so that invalidates what I said above, like @arjunh says below.
okahn
Kayvon made an off-hand comment that speed-up on P processors could be greater than P. What circumstances could that happen in? It seems that on most real systems, you could always interleave work and finish in ~1/P time.
bwf
@okahn One factor that could allow a speedup of greater than P is the use of the cache in a parallel program. Depending on the system the program is running on, accesses to memory outside of cache could be very expensive. Using more processors could increase the total amount of cache available(or have the same size cache available for a smaller problem) and allow the smaller parallel programs to drop the cost of some cache misses.
The wikipedia(http://en.wikipedia.org/wiki/Speedup#Super_linear_speedup) page on speedup gives some examples of when a speed up of greater than P can occur.
arjunh
@cube It depends on how threads are assigned to the cores. In a multi-processor system, the threads will be assigned to different cores, whereas in a single-processor system, the threads will have to context-switch on the same core. So, you can use the same algorithm on either system and make a comparison.
arjunh
@bwf Good example; another example could be in the case of search problems. Suppose you have to search a range S for a certain value x. In some cases (where x is slightly above the middle of the range), you can obtain a super-linear speedup by assigning one thread to search the first half and the other thread to search the second half.
As a result, you'll find x more than twice as fast had you just used a single thread. It's a data-dependent example, but it comes up, nevertheless.
funkysenior15
@okahn @bwf
Consider a problem which has overlapping sub-problems (when viewed recursively). Would the "cache effect" describe this situation correctly, wherein solutions to sub-problems computed by one processor would be cached, making it unnecessary for other processors to even perform the computation? Would it result in super-linear speedups?
wtwood
@arjun, we still haven't answered @rflood's question.
How do we calculate the speed-up for an algorithm? Should we compare the execution time of the same (or equivalent) algorithm on 1 processor and P processors, or should we take the best single-processor algorithm and compare it to our P processor algorithm?
For example, consider the problem of adding the integers from 1 to N.
Suppose you're currently using the sequential solution which runs a for-loop for i from 1 to N, and adds i to a sum.
Suppose this algorithm takes exactly N seconds to run.
Your parallel algorithm, for P processors, splits the numbers into chunks of size N/P, and lets each processor compute the partial sum of a chunk, then adds all the partial sums together.
If we suppose this algorithm takes exactly N/P seconds to run, then it appears that we have achieved a speed-up of P, which is awesome!
However, there is another algorithm for computing the sum of 1 through N. Specifically, there is a closed form for this sum. Suppose that you can compute the closed form in 1 second for any value of N.
If we compare our parallel algorithm to computing the closed form, then we've achieved a "speed-up" of P/N (which will be less than 1), which is really bad.
In general, the best sequential algorithm and the best parallel algorithm may approach the problem in two completely different ways. As such, when computing speed-up should we use the best-possible sequential algorithm, or should we use the sequential algorithm which most closely resembles our parallel algorithm?
arjunh
@wtwood Good point; I think the key idea is that, for most examples in this class, the asymptotic complexities of the serial/parallel algorithms that we'll consider will be in the same big-oh class. In your example, we have a linear-time algorithm (add up all the numbers), which can only improve by a constant factor if we use multiple processors to add the numbers in parallel, and a constant-time algorithm (use a closed form), which naturally can't be reasonably parallelized at all.
In this context, I'm not sure what we can say is the 'best parallel algorithm', since the best algorithm just uses a closed form. There's no need to use multiple processors in this case. The bottom-line is that we must make sure that we're making fair comparisons when studying the speedup we get by using multiple processors (ie the work involved should be in the same big-oh class).
I think a better example would be prefix-sum. Both parallel and serial implementations do O(n) work, but the serial algorithm has O(n) span, while our parallel implementation has O(log(n)) span (using the 'up' and 'down' pass approach that you saw in 15-210; this slide from last semester provides a quick overview ).
Now, this comparison is a much fairer one; both algorithms do the same amount of work, but the parallel algorithm has a much better span! We can thus expect a reasonable speedup with our parallel algorithm, since we can execute its sub-parts on different processors.
Of course, there's much more that can contribute to performance of parallel algorithms than just span. We'll take a look at communication, workload distribution, memory usage, etc. All of these things can under the category of 'constants' that we normally discard while analyzing complexity, but they are crucially important for optimizing actual performance.
Parallel algorithms can be affected (either favorably or adversely) by these architectural considerations. But, as always, we must get the work complexity of our parallel algorithm right to start with!
So, to quickly answer the original question; we view speedup as the relative improvement in executing a specific task, but we should keep the work complexity of the two tasks to be more or else the same. Of course, there can be a difference in span (which is what we should try to exploit first).
bwf
@funkysenior15 I don't that would count as the cache effect. What you're talking about is memoizing in dynamic programming. I think the "cache effect" means is that by using more processors and working on smaller problems, your working set will remain in levels of the cache that are quicker to access. For example, suppose you divide a problem of size N into subproblems with a working set of size N/P and our l1 cache has a size of N/P. In this instance we would never have to go to more costly areas of memory to access(l2, l3, main memory) outside of our initial load. However, when running on a single processor we could have to fetch from main memory multiple times which can be costly.
In this scenario we could achieve a speedup of greater than P since we can calculate the smaller subproblems faster since they are smaller, and we do not need to access the more costly parts of memory.
Assume on 1 Processor, we have N work to plus some cost C for memory fetches.
In the parallel version, we could solve each chunk of work in N/P and have a much smaller cost C.
rmuthoo
Does speedup (absolute value) for a parallel execution of a task never needs to account for the communication and ordering overhead to bring together the data from different cores (in same or distributed system environment)? It should increase as we increase the number of cores.
ananyak
@rflood I think we should compare the fastest parallel code on P processors with the fastest serial code on 1 processor. We want to know how much of a benefit we can get by using P processors (compared to 1 processor).
For example, suppose that the fastest serial code for some problem instance takes 10s to run. The fastest parallel program takes 100s to run on 1 core, and 1s to run on 100 cores. If a company is evaluating whether to change from the serial version to the parallel version on 100 cores (comparing costs, for example), they will look at this as a 10x speedup (not 100x speedup).
ananyak
@Arjun I think your search problem example in the 6th post is valid but subtle. You probably wouldn't see super linear speedups with 2 cores. I could write a serial program which alternates between searching the 1st half of the array and the 2nd half of the array. So if the array is [1,5,3,4,9,0] and we are searching for 9, the serial program could search 1 then 4 then 5 then 9. Then the parallel program would achieve linear (as opposed to superlinear) speedup. The only case when there could be a superlinear speedup with 2 cores is when the system has a direct mapped cache, and the two halves of the array happen to be in the same cache set (unlikely).
However, if you have many cores then there might be a superlinear speedup in certain cases because of the cache effect. So I think your example really boils down to the cache effect.
A question: what happens if we increase the number of processors, but we don't increase the amount of RAM or cache? Is it still possible to achieve superlinear speedups? My intuition is that under these constraints, superlinear speedups are not possible. A single processor can simply simulate what a multi-processor system is doing (eg. alternating between the halves of the array in Arjun's example).
Are we using the same algorithm on both systems, or the fastest algorithm on both systems?
If we had the central number location in a serial adding system, it would be slow to fetch each number, making the parallel speedup artificially greater
How do you make up for algorithmic differences during this comparison? Do you have to make sure the programs have the same worst-case without considering span?
@rflood It's possible I'm misinterpreting your first question, but I don't think it would make a lot of sense to use the same algorithm on both systems, because it would only use 1 processor, in order to be able to run with 1 processor. It would run the same regardless of the number of processors.
EDIT: I guess that you can use the same algorithm by differing the thread assignment, so that invalidates what I said above, like @arjunh says below.
Kayvon made an off-hand comment that speed-up on P processors could be greater than P. What circumstances could that happen in? It seems that on most real systems, you could always interleave work and finish in ~1/P time.
@okahn One factor that could allow a speedup of greater than P is the use of the cache in a parallel program. Depending on the system the program is running on, accesses to memory outside of cache could be very expensive. Using more processors could increase the total amount of cache available(or have the same size cache available for a smaller problem) and allow the smaller parallel programs to drop the cost of some cache misses.
The wikipedia(http://en.wikipedia.org/wiki/Speedup#Super_linear_speedup) page on speedup gives some examples of when a speed up of greater than P can occur.
@cube It depends on how threads are assigned to the cores. In a multi-processor system, the threads will be assigned to different cores, whereas in a single-processor system, the threads will have to context-switch on the same core. So, you can use the same algorithm on either system and make a comparison.
@bwf Good example; another example could be in the case of search problems. Suppose you have to search a range S for a certain value x. In some cases (where x is slightly above the middle of the range), you can obtain a super-linear speedup by assigning one thread to search the first half and the other thread to search the second half.
As a result, you'll find x more than twice as fast had you just used a single thread. It's a data-dependent example, but it comes up, nevertheless.
@okahn @bwf Consider a problem which has overlapping sub-problems (when viewed recursively). Would the "cache effect" describe this situation correctly, wherein solutions to sub-problems computed by one processor would be cached, making it unnecessary for other processors to even perform the computation? Would it result in super-linear speedups?
@arjun, we still haven't answered @rflood's question. How do we calculate the speed-up for an algorithm? Should we compare the execution time of the same (or equivalent) algorithm on 1 processor and P processors, or should we take the best single-processor algorithm and compare it to our P processor algorithm?
For example, consider the problem of adding the integers from 1 to N. Suppose you're currently using the sequential solution which runs a for-loop for i from 1 to N, and adds i to a sum. Suppose this algorithm takes exactly N seconds to run.
Your parallel algorithm, for P processors, splits the numbers into chunks of size N/P, and lets each processor compute the partial sum of a chunk, then adds all the partial sums together. If we suppose this algorithm takes exactly N/P seconds to run, then it appears that we have achieved a speed-up of P, which is awesome!
However, there is another algorithm for computing the sum of 1 through N. Specifically, there is a closed form for this sum. Suppose that you can compute the closed form in 1 second for any value of N.
If we compare our parallel algorithm to computing the closed form, then we've achieved a "speed-up" of P/N (which will be less than 1), which is really bad.
In general, the best sequential algorithm and the best parallel algorithm may approach the problem in two completely different ways. As such, when computing speed-up should we use the best-possible sequential algorithm, or should we use the sequential algorithm which most closely resembles our parallel algorithm?
@wtwood Good point; I think the key idea is that, for most examples in this class, the asymptotic complexities of the serial/parallel algorithms that we'll consider will be in the same big-oh class. In your example, we have a linear-time algorithm (add up all the numbers), which can only improve by a constant factor if we use multiple processors to add the numbers in parallel, and a constant-time algorithm (use a closed form), which naturally can't be reasonably parallelized at all.
In this context, I'm not sure what we can say is the 'best parallel algorithm', since the best algorithm just uses a closed form. There's no need to use multiple processors in this case. The bottom-line is that we must make sure that we're making fair comparisons when studying the speedup we get by using multiple processors (ie the work involved should be in the same big-oh class).
I think a better example would be prefix-sum. Both parallel and serial implementations do O(n) work, but the serial algorithm has O(n) span, while our parallel implementation has O(log(n)) span (using the 'up' and 'down' pass approach that you saw in 15-210; this slide from last semester provides a quick overview ).
Now, this comparison is a much fairer one; both algorithms do the same amount of work, but the parallel algorithm has a much better span! We can thus expect a reasonable speedup with our parallel algorithm, since we can execute its sub-parts on different processors.
Of course, there's much more that can contribute to performance of parallel algorithms than just span. We'll take a look at communication, workload distribution, memory usage, etc. All of these things can under the category of 'constants' that we normally discard while analyzing complexity, but they are crucially important for optimizing actual performance.
Parallel algorithms can be affected (either favorably or adversely) by these architectural considerations. But, as always, we must get the work complexity of our parallel algorithm right to start with!
So, to quickly answer the original question; we view speedup as the relative improvement in executing a specific task, but we should keep the work complexity of the two tasks to be more or else the same. Of course, there can be a difference in span (which is what we should try to exploit first).
@funkysenior15 I don't that would count as the cache effect. What you're talking about is memoizing in dynamic programming. I think the "cache effect" means is that by using more processors and working on smaller problems, your working set will remain in levels of the cache that are quicker to access. For example, suppose you divide a problem of size N into subproblems with a working set of size N/P and our l1 cache has a size of N/P. In this instance we would never have to go to more costly areas of memory to access(l2, l3, main memory) outside of our initial load. However, when running on a single processor we could have to fetch from main memory multiple times which can be costly.
In this scenario we could achieve a speedup of greater than P since we can calculate the smaller subproblems faster since they are smaller, and we do not need to access the more costly parts of memory.
Assume on 1 Processor, we have N work to plus some cost C for memory fetches. In the parallel version, we could solve each chunk of work in N/P and have a much smaller cost C.
Does speedup (absolute value) for a parallel execution of a task never needs to account for the communication and ordering overhead to bring together the data from different cores (in same or distributed system environment)? It should increase as we increase the number of cores.
@rflood I think we should compare the fastest parallel code on P processors with the fastest serial code on 1 processor. We want to know how much of a benefit we can get by using P processors (compared to 1 processor).
For example, suppose that the fastest serial code for some problem instance takes 10s to run. The fastest parallel program takes 100s to run on 1 core, and 1s to run on 100 cores. If a company is evaluating whether to change from the serial version to the parallel version on 100 cores (comparing costs, for example), they will look at this as a 10x speedup (not 100x speedup).
@Arjun I think your search problem example in the 6th post is valid but subtle. You probably wouldn't see super linear speedups with 2 cores. I could write a serial program which alternates between searching the 1st half of the array and the 2nd half of the array. So if the array is [1,5,3,4,9,0] and we are searching for 9, the serial program could search 1 then 4 then 5 then 9. Then the parallel program would achieve linear (as opposed to superlinear) speedup. The only case when there could be a superlinear speedup with 2 cores is when the system has a direct mapped cache, and the two halves of the array happen to be in the same cache set (unlikely).
However, if you have many cores then there might be a superlinear speedup in certain cases because of the cache effect. So I think your example really boils down to the cache effect.
A question: what happens if we increase the number of processors, but we don't increase the amount of RAM or cache? Is it still possible to achieve superlinear speedups? My intuition is that under these constraints, superlinear speedups are not possible. A single processor can simply simulate what a multi-processor system is doing (eg. alternating between the halves of the array in Arjun's example).