In this case, if we didnt allocate the 520 bytes of shared memory per block, would we not be able to run, say, 3 blocks at once?
This would be a overall 1.5x speedup, but I guess this would be overshadowed by the speedup we get from allocating and using shared memory. Is there a way to know of the speedup tradeoff like this before hand? Or will we have to figure it out from going thru the datasheet of the GPU?
Allerrors
@enuitt If we didn't need to allocate 520 bytes shared memory, then each core can fit 3 blocks (128 * 3 threads). However, I don't understand how 1.5x speedup comes from. If you mean the general case, I think that would be 2x speedup since we have 2 cores here. If you mean the convolution computation that utilizes the shared memory, I think that would be 3x speedup because we save 3 times load instructions.
MaxFlowMinCut
What happens if a block's memory can't fit on a core? For example, if the user decided to execute blocks with 384 CUDA threads and caused each block to allocate 390 x sizeof(float) > 1.5 KB of shared memory, then how would the GPU block scheduler resolve this? Would it just put the block on the core and perform lengthy memory lookups from shared memory on a cache miss?
kayvonf
@MaxFlowMinCut. The program you suggest would fail to compile since it would attempt to statically declare a shared memory allocation that is larger than the maximum shared memory size.
randomthread
The above comment seems to entail that when compiling we must compile for a specific GPU since different GPUs have different amounts of shared memory. If this is the case then how do we write portable code?
kayvonf
@randomthread. That is correct. Technically in CUDA you do not write code to a particular GPU, you write code to a particular CUDA compute capability. This is one of the pitfalls of a programming model that features software-managed on-chip storage.
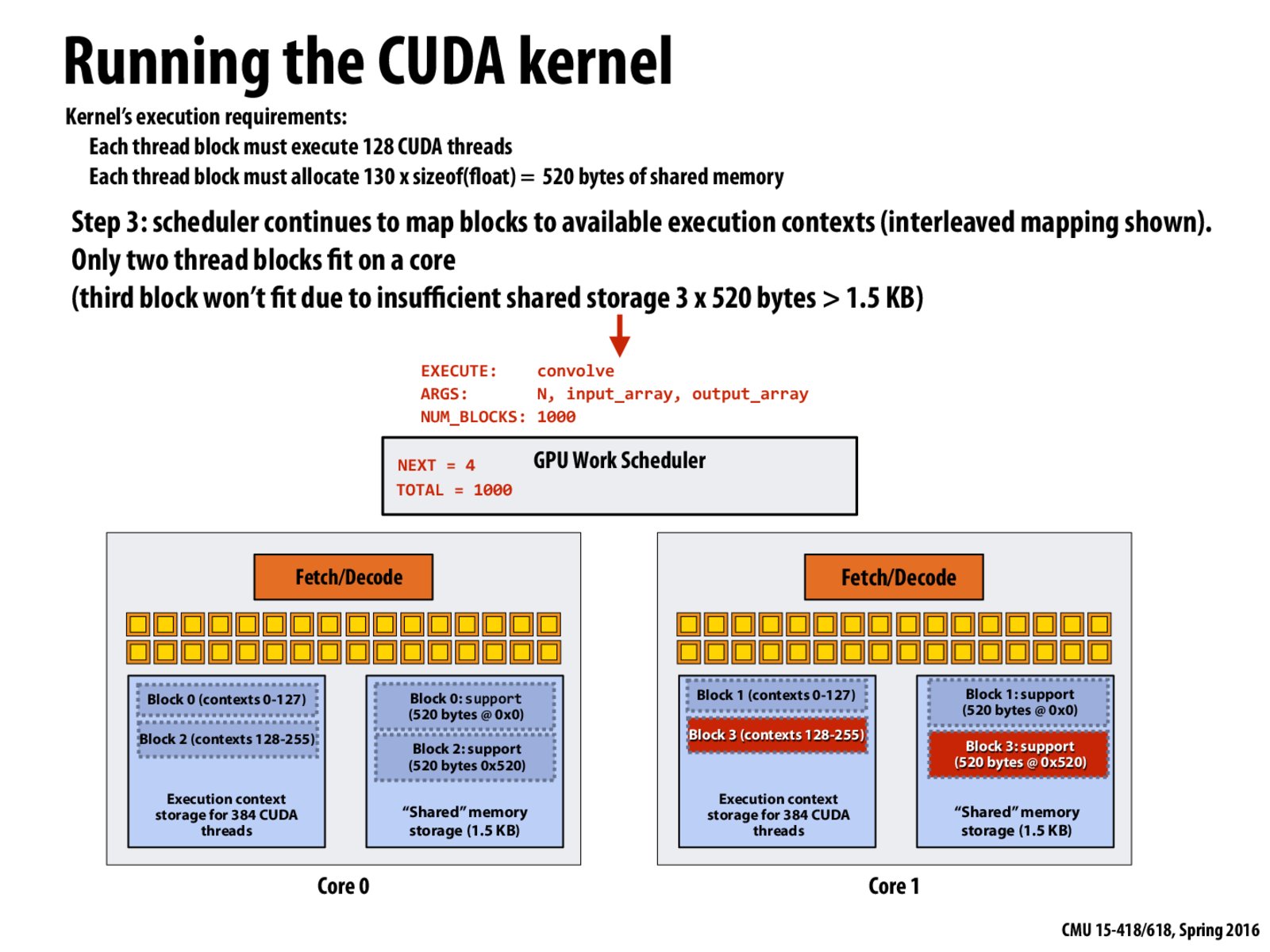
How does the scheduler know that the thread block will require 520 bytes of memory? Is it just from static analysis?
By using the keyword shared you can tell the GPU to allocate shared memory for that block
@thomasts in addition to what @Rx said
Check
Slide 47
for an example usage of shared
In this case, if we didnt allocate the 520 bytes of shared memory per block, would we not be able to run, say, 3 blocks at once?
This would be a overall 1.5x speedup, but I guess this would be overshadowed by the speedup we get from allocating and using shared memory. Is there a way to know of the speedup tradeoff like this before hand? Or will we have to figure it out from going thru the datasheet of the GPU?
@enuitt If we didn't need to allocate 520 bytes shared memory, then each core can fit 3 blocks (128 * 3 threads). However, I don't understand how 1.5x speedup comes from. If you mean the general case, I think that would be 2x speedup since we have 2 cores here. If you mean the convolution computation that utilizes the shared memory, I think that would be 3x speedup because we save 3 times load instructions.
What happens if a block's memory can't fit on a core? For example, if the user decided to execute blocks with 384 CUDA threads and caused each block to allocate
390 x sizeof(float) > 1.5 KBof shared memory, then how would the GPU block scheduler resolve this? Would it just put the block on the core and perform lengthy memory lookups from shared memory on a cache miss?@MaxFlowMinCut. The program you suggest would fail to compile since it would attempt to statically declare a shared memory allocation that is larger than the maximum shared memory size.
The above comment seems to entail that when compiling we must compile for a specific GPU since different GPUs have different amounts of shared memory. If this is the case then how do we write portable code?
@randomthread. That is correct. Technically in CUDA you do not write code to a particular GPU, you write code to a particular CUDA compute capability. This is one of the pitfalls of a programming model that features software-managed on-chip storage.