If we have multiple channels, we can have separated filters for each channel, but we can also have shared filters for all the channels. After convolution, we can then combine these convoluted results (either separated filters or shared filters) by using pooling techniques.
srb
ReLU layers apply the function max(0, x) at each node. Pooling layers are for down-sampling.
Levy
@srb
Not actually. While a common function for ReLU is max(0, x), many other non-linear functions apply, too. E.g. a differentiable approximation of max
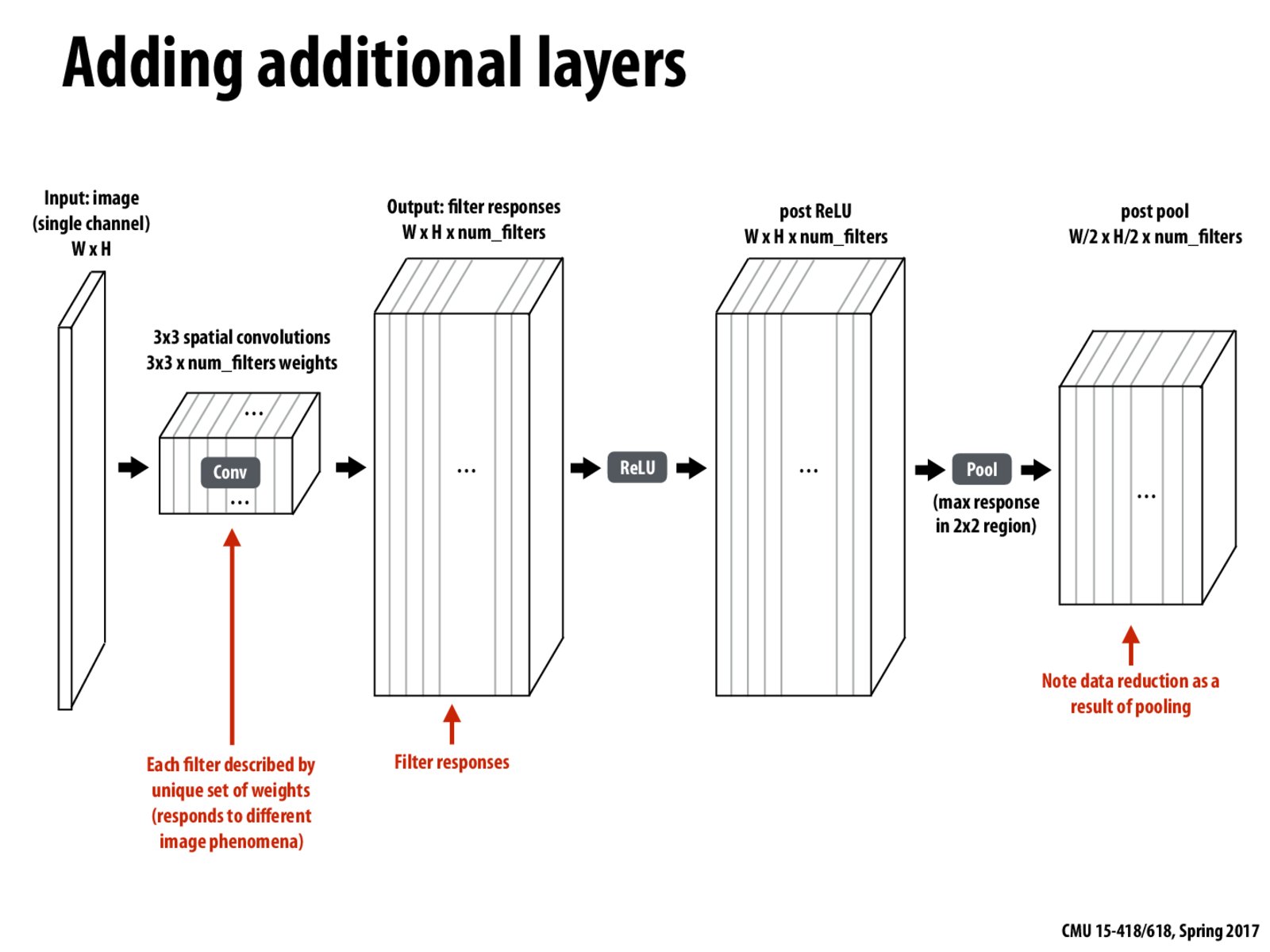
If we have multiple channels, we can have separated filters for each channel, but we can also have shared filters for all the channels. After convolution, we can then combine these convoluted results (either separated filters or shared filters) by using pooling techniques.
ReLU layers apply the function max(0, x) at each node. Pooling layers are for down-sampling.
@srb Not actually. While a common function for ReLU is
max(0, x), many other non-linear functions apply, too. E.g. a differentiable approximation of max