Can the following code run in parallel on this core?(same "mul" instruction but different address)
int a[4];
int b[4] = {0,1,2,3};
int c[4] = {4,3,2,1};
for(int i = 0; i < 4; i++) {
a[i] = b[i] * c[i];
}
Kaharjan
@LuCheng In my understanding SIMD could run using 4 ALUs. Specifically, in 2 clocks (assume loading takes one clock time) b,c values (all for value as vector) would be loaded to registers then 4 ALUs calculate mul . then write 4 values to c. So there would be only one execution context.
kayvonf
@LuCheng: There are two points I want to make:
Point 1:
The answer to your question is it will not. You have written C code that most modern compiles like g++ or clang would compile to regular "scalar" instructions. On a modern CPU, the only way to execute in a SIMD manner is for the instruction stream to have explicit SIMD instructions in it. For example, one of the following would need to happen.
Hope that G++ automatically vectorized the for look, removing the loop and turning it into a single 4-wide vector instruction. (This is not a transformation that a C compiler can do other than in the most simple cases.
Rewrite your program in an SPMD style language with a compiler that generates SIMD output (like ISPC)
Rewrite your program in vector intrinsics, like this:
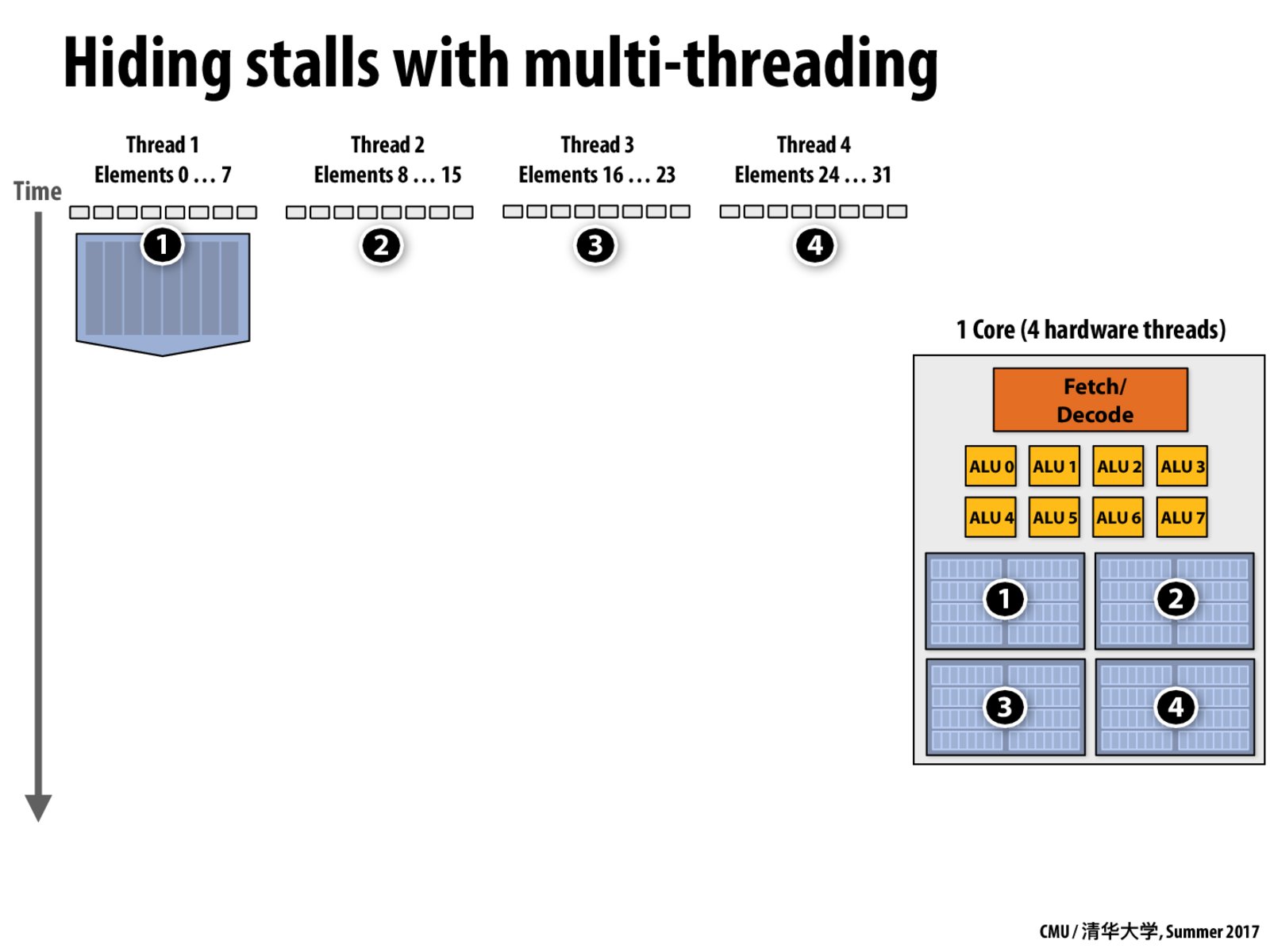
I am worried that since you asked this question on this slide, you might be confusing the concepts of SIMD execution, and hardware-multithreading. This slide is illustrating how if a core is able to maintain state for 4 different instruction streams (in other words, maintain 4 different execution contexts), it is possible to avoid stalls by immediately switching to another instruction stream when the current instruction stream would otherwise stall.
The choice of illustrating four execution contexts here is unrelated to 4-wide SIMD execution. Adding 4-wide SIMD processing capability modifies the execution capabilities of the core to perform four times more math operations in a single clock. When we are talking about multi-threading, we are not changing the number of operations that the core can perform at once. Instead, we are adding the ability to store multiple threads worth of state in the core in order to give the core the ability to use its existing execution resources more efficiently by hiding what would otherwise be processor stalls.
Kaharjan
@kayvonf
In above vector intrinsics, how many clocks to load, calculate and store? (assuming loading, calculating and storing take one clock time)
In my view loading value of a and b takes two clocks, calculating takes one clock and storing is also takes one clock, am I right?
kayvonf
Let's ignore memory latency (say its 0) and assume all ops take 1 cycle. Then the code below:
LOAD
LOAD
MULT
STORE
Would require four clocks. In practice, there are more complex issues in play in a real processor (pipeline, etc.) but 4 cycles is the correct answer given what we've talked about in class so far.
Can the following code run in parallel on this core?(same "mul" instruction but different address)
@LuCheng In my understanding SIMD could run using 4 ALUs. Specifically, in 2 clocks (assume loading takes one clock time) b,c values (all for value as vector) would be loaded to registers then 4 ALUs calculate mul . then write 4 values to c. So there would be only one execution context.
@LuCheng: There are two points I want to make:
Point 1:
The answer to your question is it will not. You have written C code that most modern compiles like g++ or clang would compile to regular "scalar" instructions. On a modern CPU, the only way to execute in a SIMD manner is for the instruction stream to have explicit SIMD instructions in it. For example, one of the following would need to happen.
Rewrite your program in vector intrinsics, like this:
__mm256 a_vec = _mm256_mul_ps( _mm256_load_ps(&b, _mm256_load_ps(&c); _mm256_store_ps(a, a_vec);
Point 2:
I am worried that since you asked this question on this slide, you might be confusing the concepts of SIMD execution, and hardware-multithreading. This slide is illustrating how if a core is able to maintain state for 4 different instruction streams (in other words, maintain 4 different execution contexts), it is possible to avoid stalls by immediately switching to another instruction stream when the current instruction stream would otherwise stall.
The choice of illustrating four execution contexts here is unrelated to 4-wide SIMD execution. Adding 4-wide SIMD processing capability modifies the execution capabilities of the core to perform four times more math operations in a single clock. When we are talking about multi-threading, we are not changing the number of operations that the core can perform at once. Instead, we are adding the ability to store multiple threads worth of state in the core in order to give the core the ability to use its existing execution resources more efficiently by hiding what would otherwise be processor stalls.
@kayvonf In above vector intrinsics, how many clocks to load, calculate and store? (assuming loading, calculating and storing take one clock time)
In my view loading value of a and b takes two clocks, calculating takes one clock and storing is also takes one clock, am I right?
Let's ignore memory latency (say its 0) and assume all ops take 1 cycle. Then the code below:
LOAD LOAD MULT STORE
Would require four clocks. In practice, there are more complex issues in play in a real processor (pipeline, etc.) but 4 cycles is the correct answer given what we've talked about in class so far.