Hello, I am confused about how the concurrency should be calculated for a core with superscalar, SIMD and hardware multi-threading enabled. In this slide, I think the concurrency is 4(superscalar) * 32(simd) * 64(multi-threading) = 8192 though up to 4 * 32 = 128 elements can be processed simultaneously. Why is the answer 2048?
It seems that the concurrency has no relation with superscalar or the degree of SMT(4 here)?
kayvonf
Your thinking is on the right track, but here is a clarification.
Each "core" of the GPU is able to maintain state of 64 execution contexts (64 "hardware threads" = 64 "independent instruction streams").
Each of those threads executes 32-SIMD instructions, so that's 32 unique data elements processed by each hardware thread. This means that 64 x 32 = 2048 data elements are assigned to threads that are running concurrently on the core. I say concurrently because not all 64 of these threads can be executed exactly at the same time. Only 4 of these threads can be run in any one clock, so only 4 x 32 = 128 data elements can be processed simultaneously. (Notice there are only 4 x 32 = 128 ALUs in this picture.)
This picture not does illustrate superscalar execution. The core is choosing 4 different threads to run simultaneously and running one instruction from each of those threads. It is not superscalar because the core is not finding independent instructions within any one single thread.
Precisely, this core is performing interleaved multi-threading because it is able to maintain state for 64 threads, and only execute a subset of those threads (4) each clock. (It interleaves execution of the 64 threads onto the core's ALUs).
It is also performing simultaneous multi-threading because it is in fact running multiple threads simultaneously (4 of them).
If you look at the extra slides at the end of the lecture, there are further examples of the difference between interleaved and simultaneous multi-threading.
To be 100% precise, there is superscalar execution in this picture as well, but we did not talk about it in class. If you look at the picture there is a second fetch/decode unit shown that is grayed out. The core can actually select 4 threads to run, and then us 2-way superscalar execution to run two instructions from that thread if one instruction is a mathematical instruction running on the yellow ALUs and the other instruction is a LD/ST instruction that uses different units that I did not draw in the picture.
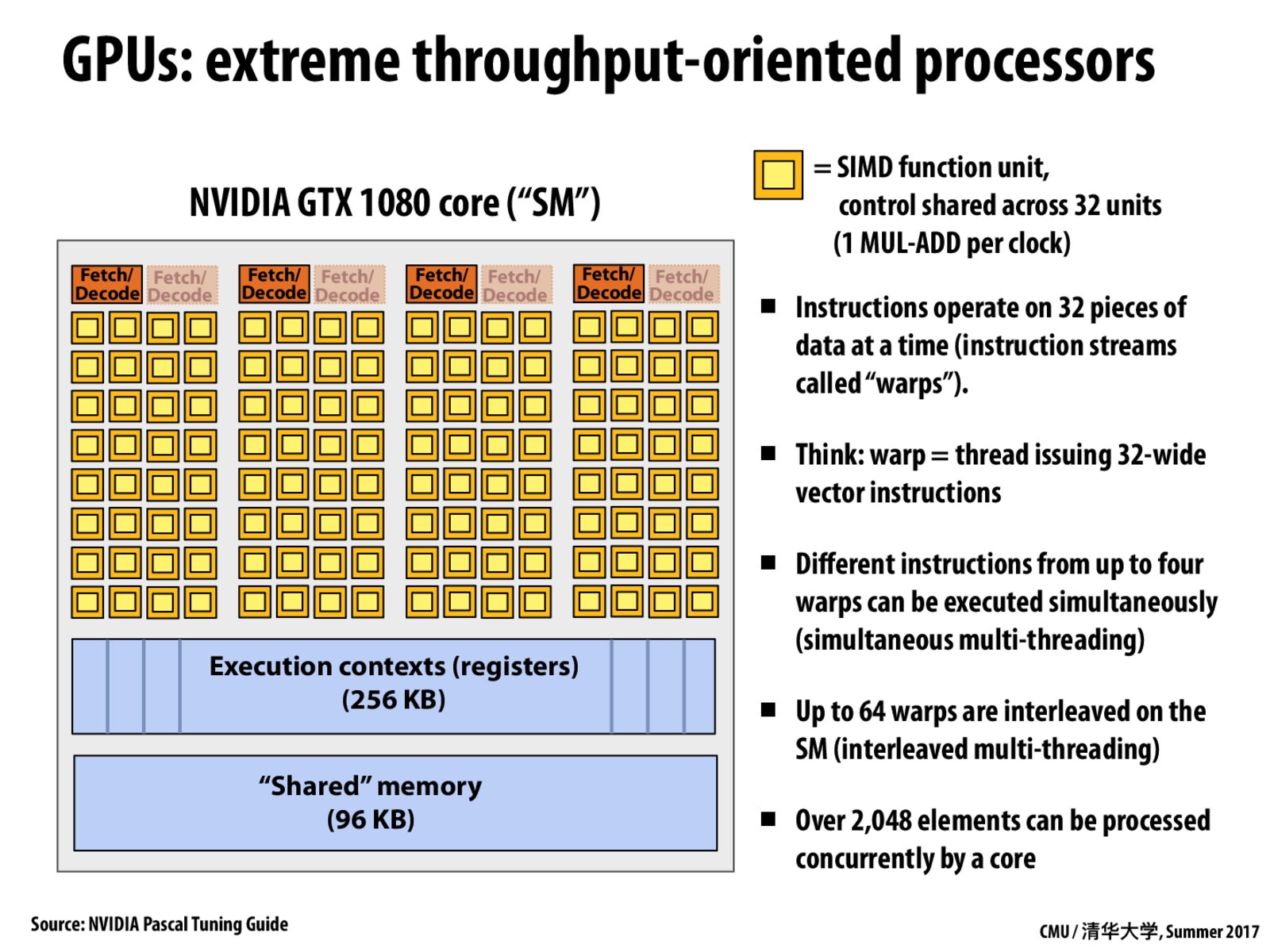
Hello, I am confused about how the concurrency should be calculated for a core with superscalar, SIMD and hardware multi-threading enabled. In this slide, I think the concurrency is 4(superscalar) * 32(simd) * 64(multi-threading) = 8192 though up to 4 * 32 = 128 elements can be processed simultaneously. Why is the answer 2048?
It seems that the concurrency has no relation with superscalar or the degree of SMT(4 here)?
Your thinking is on the right track, but here is a clarification.
Each "core" of the GPU is able to maintain state of 64 execution contexts (64 "hardware threads" = 64 "independent instruction streams").
Each of those threads executes 32-SIMD instructions, so that's 32 unique data elements processed by each hardware thread. This means that 64 x 32 = 2048 data elements are assigned to threads that are running concurrently on the core. I say concurrently because not all 64 of these threads can be executed exactly at the same time. Only 4 of these threads can be run in any one clock, so only 4 x 32 = 128 data elements can be processed simultaneously. (Notice there are only 4 x 32 = 128 ALUs in this picture.)
This picture not does illustrate superscalar execution. The core is choosing 4 different threads to run simultaneously and running one instruction from each of those threads. It is not superscalar because the core is not finding independent instructions within any one single thread.
Precisely, this core is performing interleaved multi-threading because it is able to maintain state for 64 threads, and only execute a subset of those threads (4) each clock. (It interleaves execution of the 64 threads onto the core's ALUs).
It is also performing simultaneous multi-threading because it is in fact running multiple threads simultaneously (4 of them).
If you look at the extra slides at the end of the lecture, there are further examples of the difference between interleaved and simultaneous multi-threading.
To be 100% precise, there is superscalar execution in this picture as well, but we did not talk about it in class. If you look at the picture there is a second fetch/decode unit shown that is grayed out. The core can actually select 4 threads to run, and then us 2-way superscalar execution to run two instructions from that thread if one instruction is a mathematical instruction running on the yellow ALUs and the other instruction is a LD/ST instruction that uses different units that I did not draw in the picture.
Thanks. It is clear to me now.