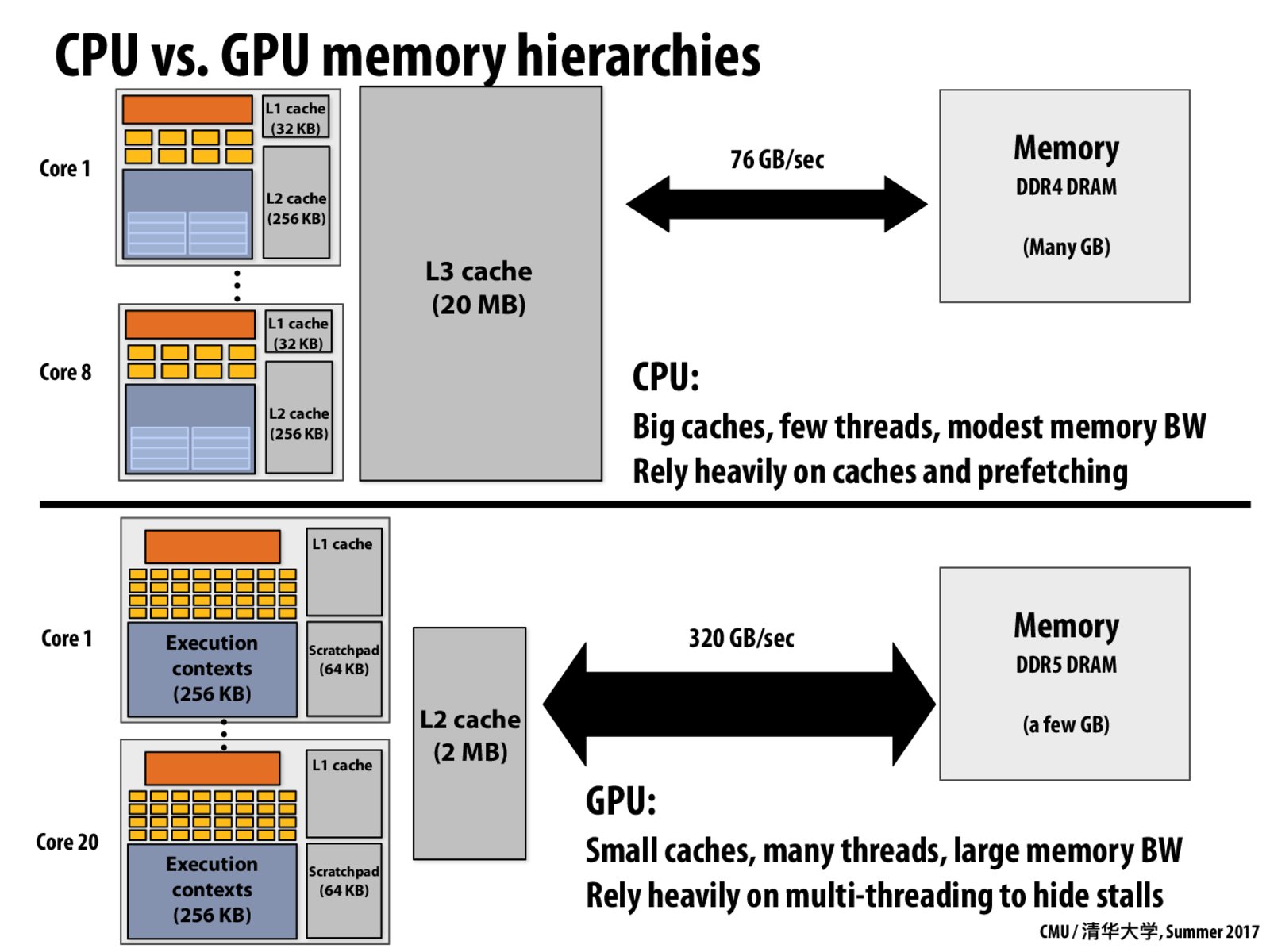
Question: Why do you think GPU architects design chips with smaller caches, while CPU architects typically create designs with large caches?
Kaharjan
GPU originally intend to process graphics need to access data quickly, so need to smaller caches to hide memory latency.
ann
because the graphic processing instruction streams contain more bandwidth-consuming memory-related instructions such as load/store while CPUs have more arithmetic operations? and large quantities of different pixels are not suited for cache utilization?
kayvonf
The answer to this question can really help understand the different between trying to build a computer than minimizes latency vs. one that maximizes throughput.
In many CPU applications, the goal of the application is to provide a fast response to the user on a single task. Think of applications like many of the apps on your phone, Microsoft Word, spreadsheets, etc. Therefore, a major goal of CPU design is to run a single instruction stream quickly. Ideas like [superscalar execution(http://15418.courses.cs.cmu.edu/tsinghua2017/lecture/whyparallelism/slide_047) are one way to improve the performance of a single instruction stream. Another way is to reduce the latency of memory access by adding caches. For many applications, bigger caches allows more memory accesses to be handled by the cache (larger caches reduce the number of cache misses). So on CPUs you see designs with only a few cores, and big caches. These designs are good when:
Programs have a lot of data reuse (access the same data multiple times)
There is not "other parallel work to do", so the only way to reduce stalls due to memory access is to __reduce memory latency with caches___, not hie memory latency by doing something else while waiting on memory to return the requested data.
In contrast, even though GPUs run many types of programs, GPUs are still designed for running real time graphics program. Those programs must proceed millions of pixels and vertices, so there are always many tasks to work on. As a result, rather than attempt to reduce latency by adding large caches to the GPU, GPU designers take advantage of the fact that most GPU workloads have large amounts of parallelism and use hardware multi-threading to hide latency. Since latency can be hidden, then big caches are not necessary to keep memory access times low.
So in summary: GPUs assume that the workload is very parallel and there are many subproblems to do (there's always something else to do in the event of a stall). Because of this assumption architects have prioritized latency latency via multi-threading over latency reduction via caching. CPUs assume the workload is not, and since a CPU cannot assume there are many other things to do in case of a stall, CPU designs attempt to eliminate or reduce the length of the stat via caching.
Question: Given the explanation above, give one reason why the GPU features higher memory bandwidth than the CPU.
Question: Why do you think GPU architects design chips with smaller caches, while CPU architects typically create designs with large caches?
GPU originally intend to process graphics need to access data quickly, so need to smaller caches to hide memory latency.
because the graphic processing instruction streams contain more bandwidth-consuming memory-related instructions such as load/store while CPUs have more arithmetic operations? and large quantities of different pixels are not suited for cache utilization?
The answer to this question can really help understand the different between trying to build a computer than minimizes latency vs. one that maximizes throughput.
In many CPU applications, the goal of the application is to provide a fast response to the user on a single task. Think of applications like many of the apps on your phone, Microsoft Word, spreadsheets, etc. Therefore, a major goal of CPU design is to run a single instruction stream quickly. Ideas like [superscalar execution(http://15418.courses.cs.cmu.edu/tsinghua2017/lecture/whyparallelism/slide_047) are one way to improve the performance of a single instruction stream. Another way is to reduce the latency of memory access by adding caches. For many applications, bigger caches allows more memory accesses to be handled by the cache (larger caches reduce the number of cache misses). So on CPUs you see designs with only a few cores, and big caches. These designs are good when:
In contrast, even though GPUs run many types of programs, GPUs are still designed for running real time graphics program. Those programs must proceed millions of pixels and vertices, so there are always many tasks to work on. As a result, rather than attempt to reduce latency by adding large caches to the GPU, GPU designers take advantage of the fact that most GPU workloads have large amounts of parallelism and use hardware multi-threading to hide latency. Since latency can be hidden, then big caches are not necessary to keep memory access times low.
So in summary: GPUs assume that the workload is very parallel and there are many subproblems to do (there's always something else to do in the event of a stall). Because of this assumption architects have prioritized latency latency via multi-threading over latency reduction via caching. CPUs assume the workload is not, and since a CPU cannot assume there are many other things to do in case of a stall, CPU designs attempt to eliminate or reduce the length of the stat via caching.
Question: Given the explanation above, give one reason why the GPU features higher memory bandwidth than the CPU.
because of many multi-threading