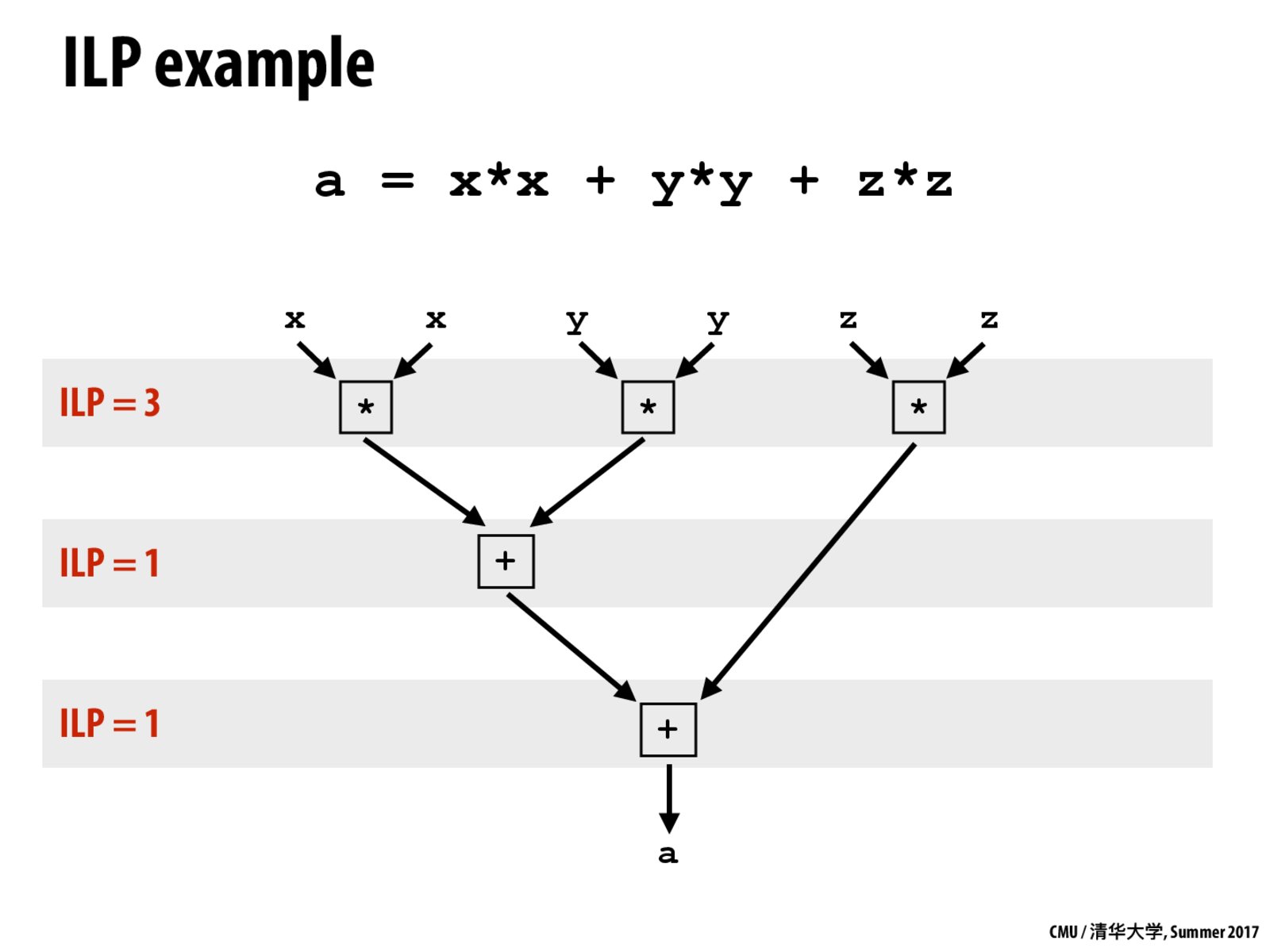
Question: Can someone describe to me what "ILP = 1" means on this slide?
Kaharjan
ILP=1 is one instruction is executed at one clock. ILP=3 is three instructions are executed at one clock.
kayvonf
@Kaharjan.
Good. But I'd like to be even more precise.
This "program" contains five instructions. So on a processor that does not support superscalar execution, the program would take five clocks to complete.
Instruction level parallelism (ILP) is a property of a program (in other words, the property of the instruction stream). In this program, there are three multiply instructions that are independent and therefore can be executed in parallel. Then there is an instruction (add) that depends on the results of those, and a final add that further depends on the first add.
That is what is being drawn here is potential parallelism that a processor core with support for superscalar execution may be able to take advantage of to run the instruction stream faster.
How much parallel work is actually done depends on the design of the processor.
A processor core that has support for 3-wide superscalar execution (We often say "3-way" to means it can run three instructions per clock) could use all three of its execution units to run the three multiply instructions in parallel. However, it could only use one of its three execution units in the next two clocks to perform the adds. Therefore the processor runs at 100% efficiency in clock 1. And 33% efficiency in clocks 2 and 3.
A different processor that only had support for two-wide superscalar execution (such as this one in the next lecture) could execute 2 of the 3 multiples in clock 1 (100% efficiency). Then execute the third multiply and the first add in clock 2 (100% efficiency). And finally execute the final add in clock 3 (50% efficiency).
Note that for this program, a 3-way superscalar processor that can execute 3 instructions per clock and a 2-way superscalar processor that can execute 2 instructions per clock would both execute this five instruction program in 3 clocks.
Since we can assume the 3-way superscalar processor is expensive to build because it uses more hardware, but it only gives the same performance as the cheaper 2-way superscalar processor, this is another example of why the graph on this slide flattens out. Sometimes a program just doesn't have enough instruction level parallelism to make full use of all the execution resources a processor core has!
limin
I have two question: 1)Do we have any method to acquire the hardware parallel parameter when I run my program, such as the degree of hardware parallelism and the utilization of the hardware resources? 2)If we manually write assembly code, how to write efficient code that could make full use of the ILP except from SIMD? Thanks~~
kayvonf
@limin:
(1) Yes you would read the processor's instruction manual which may describe what combinations of instructions can issue in parallel. For Intel processors, that is this document:
(2) It depends on the instruction set architecture (ISA) of the processor you are writing a program for. On x86, most of the parallelism is found automatically by the hardware. But on a VLIW system or on ARM, where dynamic logic for discovering parallelism is limited, generating the right instruction sequence could be helpful to performance.
Question: Can someone describe to me what "ILP = 1" means on this slide?
ILP=1 is one instruction is executed at one clock. ILP=3 is three instructions are executed at one clock.
@Kaharjan.
Good. But I'd like to be even more precise.
This "program" contains five instructions. So on a processor that does not support superscalar execution, the program would take five clocks to complete.
Instruction level parallelism (ILP) is a property of a program (in other words, the property of the instruction stream). In this program, there are three multiply instructions that are independent and therefore can be executed in parallel. Then there is an instruction (add) that depends on the results of those, and a final add that further depends on the first add.
That is what is being drawn here is potential parallelism that a processor core with support for superscalar execution may be able to take advantage of to run the instruction stream faster.
How much parallel work is actually done depends on the design of the processor.
A processor core that has support for 3-wide superscalar execution (We often say "3-way" to means it can run three instructions per clock) could use all three of its execution units to run the three multiply instructions in parallel. However, it could only use one of its three execution units in the next two clocks to perform the adds. Therefore the processor runs at 100% efficiency in clock 1. And 33% efficiency in clocks 2 and 3.
A different processor that only had support for two-wide superscalar execution (such as this one in the next lecture) could execute 2 of the 3 multiples in clock 1 (100% efficiency). Then execute the third multiply and the first add in clock 2 (100% efficiency). And finally execute the final add in clock 3 (50% efficiency).
Note that for this program, a 3-way superscalar processor that can execute 3 instructions per clock and a 2-way superscalar processor that can execute 2 instructions per clock would both execute this five instruction program in 3 clocks.
Since we can assume the 3-way superscalar processor is expensive to build because it uses more hardware, but it only gives the same performance as the cheaper 2-way superscalar processor, this is another example of why the graph on this slide flattens out. Sometimes a program just doesn't have enough instruction level parallelism to make full use of all the execution resources a processor core has!
I have two question: 1)Do we have any method to acquire the hardware parallel parameter when I run my program, such as the degree of hardware parallelism and the utilization of the hardware resources? 2)If we manually write assembly code, how to write efficient code that could make full use of the ILP except from SIMD? Thanks~~
@limin:
(1) Yes you would read the processor's instruction manual which may describe what combinations of instructions can issue in parallel. For Intel processors, that is this document:
https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf
(2) It depends on the instruction set architecture (ISA) of the processor you are writing a program for. On x86, most of the parallelism is found automatically by the hardware. But on a VLIW system or on ARM, where dynamic logic for discovering parallelism is limited, generating the right instruction sequence could be helpful to performance.