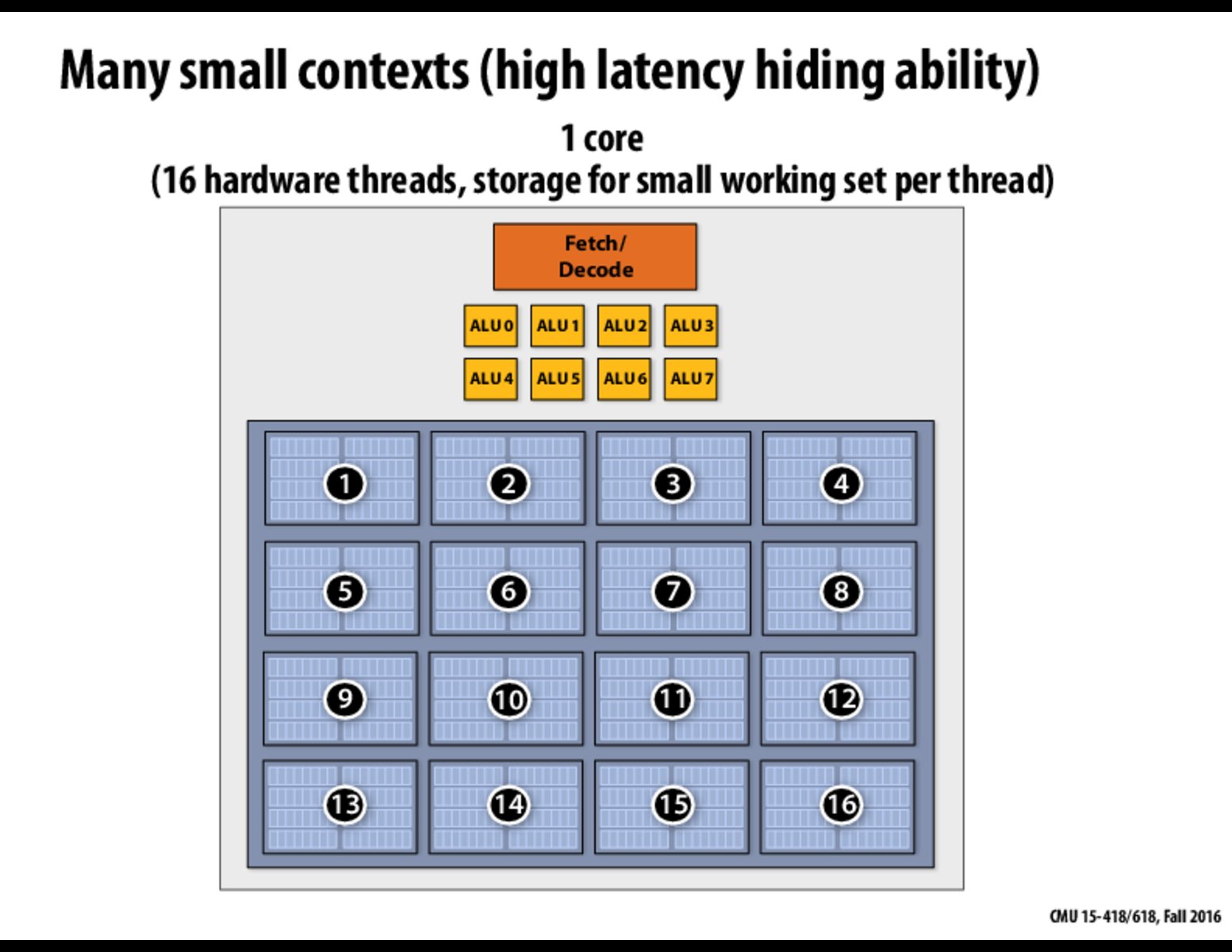
Can I understand this picture like this? --> The above architecture can hide MORE latency because it has a lot of execution context units to store them. But each has LOWER store ability. The next slide shows a different case: high LESS latency; HIGHER store ability.
What are the scenarios of using those two cases?
Which one corresponds to CPU, which one corresponds to GPU?
Question:
Can I understand this picture like this? --> The above architecture can hide MORE latency because it has a lot of execution context units to store them. But each has LOWER store ability. The next slide shows a different case: high LESS latency; HIGHER store ability.
What are the scenarios of using those two cases?
Which one corresponds to CPU, which one corresponds to GPU?