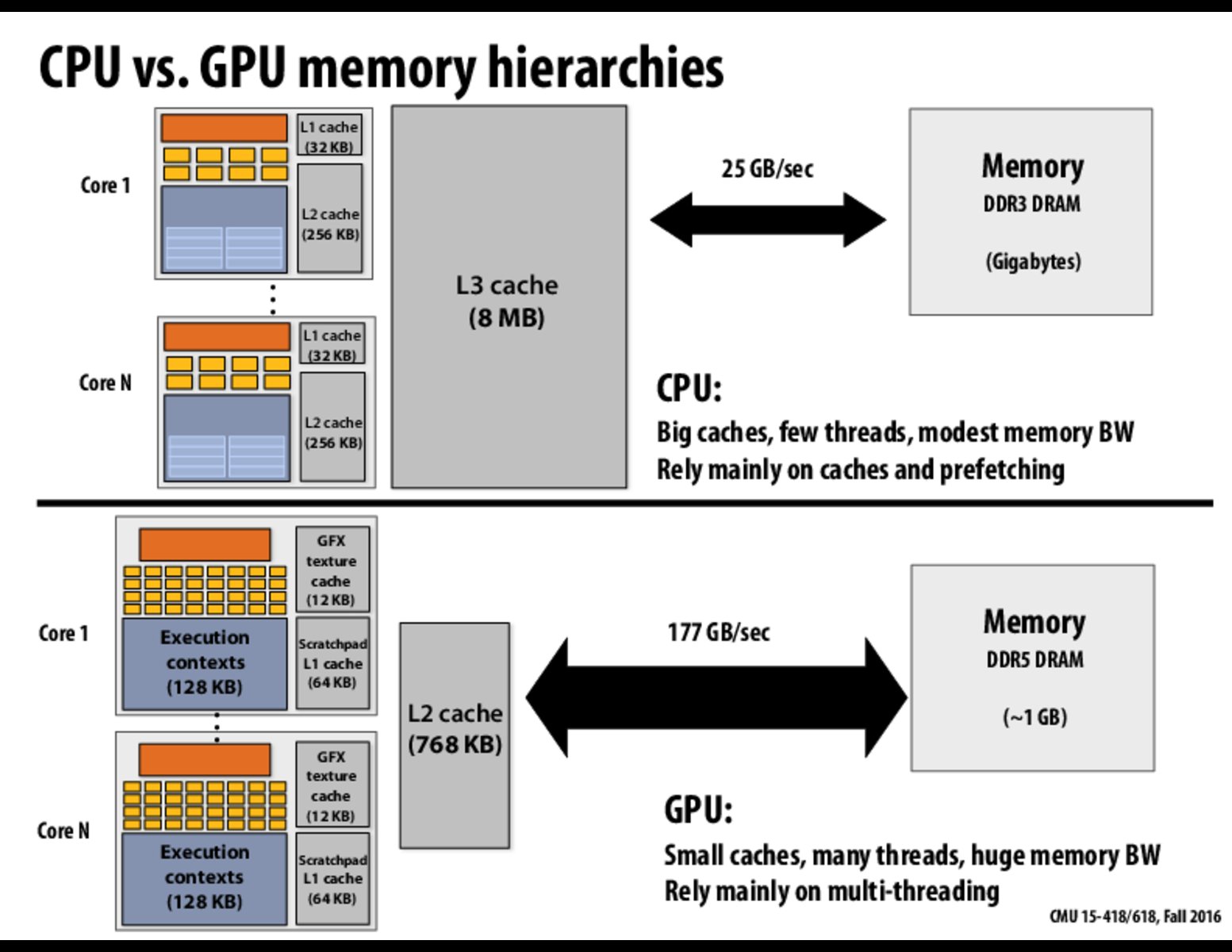
Is it more useful for the cores to have their own caches or for them to share a cache? The arguments I can think for each side are that if they have their own cache, cache accessing would be faster since there would not have to be any sort of locking mechanism for writing to the cache where only one core can write to avoid race conditions. On the other hand having them share a cache would help increase cache hits if the cores are operating on the same data.
In the thumbnail it seems that there is a bit of both happening.
bpr
@mpcomplete, Computer architects (and lawyers) will tell you "It depends". Nathan Beckmann[1] will be joining the faculty here in January and is one of many who are researching how the hardware can support partitioning cache space and redistributing the data.
It is not "locking" that causes the trouble, but rather cache conflicts and evictions. If two cores are using the same cache for different purposes, then their accesses can cause the data for the other core to be evicted.
[1] http://people.csail.mit.edu/beckmann/
gogogo
What type of eviction schemes would best suit a small amount of threads? What about a large amount of threads? Would there be cache eviction schemes that would benefit CPU's very well but not GPU's as much and vice versa?
Edit: rather than # of threads frequency of memory accesses?
bpr
@gogogo, It is not about the quantity of threads, but rather what each thread is doing: frequency of memory accesses and size of working set.
nba16235
What's the formal definition of bandwidth? My understanding is that bandwidth equals the transfer data amount / time. Does the compiler provide any tool for programmer to measure the bandwidth?
Iamme
In light of Lecture 7 on CUDA programming, I'm a little confused about why the CPU and GPU play such different and non-symmetric roles. It seems like, based on the depictions above, they should have the same general capabilities, even if one is better at certain tasks than the other and vice versa.
Can someone explain the differences a bit further and in the context of CUDA programming?
hanzhoul
So in this figure, is L2 cache the place where shared memory stored? If so, can we assume that shared memory in a thread block is slower to access than those threads' individual local memory?
bpr
@hanzhoul, the L2 is an actual, HW-managed cache. The scratchpad L1 cache in this image is the shared memory that is explicitly managed by the CUDA code.
Is it more useful for the cores to have their own caches or for them to share a cache? The arguments I can think for each side are that if they have their own cache, cache accessing would be faster since there would not have to be any sort of locking mechanism for writing to the cache where only one core can write to avoid race conditions. On the other hand having them share a cache would help increase cache hits if the cores are operating on the same data.
In the thumbnail it seems that there is a bit of both happening.
@mpcomplete, Computer architects (and lawyers) will tell you "It depends". Nathan Beckmann[1] will be joining the faculty here in January and is one of many who are researching how the hardware can support partitioning cache space and redistributing the data.
It is not "locking" that causes the trouble, but rather cache conflicts and evictions. If two cores are using the same cache for different purposes, then their accesses can cause the data for the other core to be evicted.
[1] http://people.csail.mit.edu/beckmann/
What type of eviction schemes would best suit a small amount of threads? What about a large amount of threads? Would there be cache eviction schemes that would benefit CPU's very well but not GPU's as much and vice versa?
Edit: rather than # of threads frequency of memory accesses?
@gogogo, It is not about the quantity of threads, but rather what each thread is doing: frequency of memory accesses and size of working set.
What's the formal definition of bandwidth? My understanding is that bandwidth equals the transfer data amount / time. Does the compiler provide any tool for programmer to measure the bandwidth?
In light of Lecture 7 on CUDA programming, I'm a little confused about why the CPU and GPU play such different and non-symmetric roles. It seems like, based on the depictions above, they should have the same general capabilities, even if one is better at certain tasks than the other and vice versa. Can someone explain the differences a bit further and in the context of CUDA programming?
So in this figure, is L2 cache the place where shared memory stored? If so, can we assume that shared memory in a thread block is slower to access than those threads' individual local memory?
@hanzhoul, the L2 is an actual, HW-managed cache. The scratchpad L1 cache in this image is the shared memory that is explicitly managed by the CUDA code.