There is a similar facet of CUDA programming called "pinned memory", where the device is allowed to read and write memory directly to host memory via the DMA without involvement of the CPU.
taoy1
@tclarke So how does CUDA solve this problem? They mark pinned memory as not-cachable as well?
tclarke
Yes, the CPU is not allowed to hold in the cache any memory that is marked pinned. The GPU is allowed to get the data directly from host RAM.
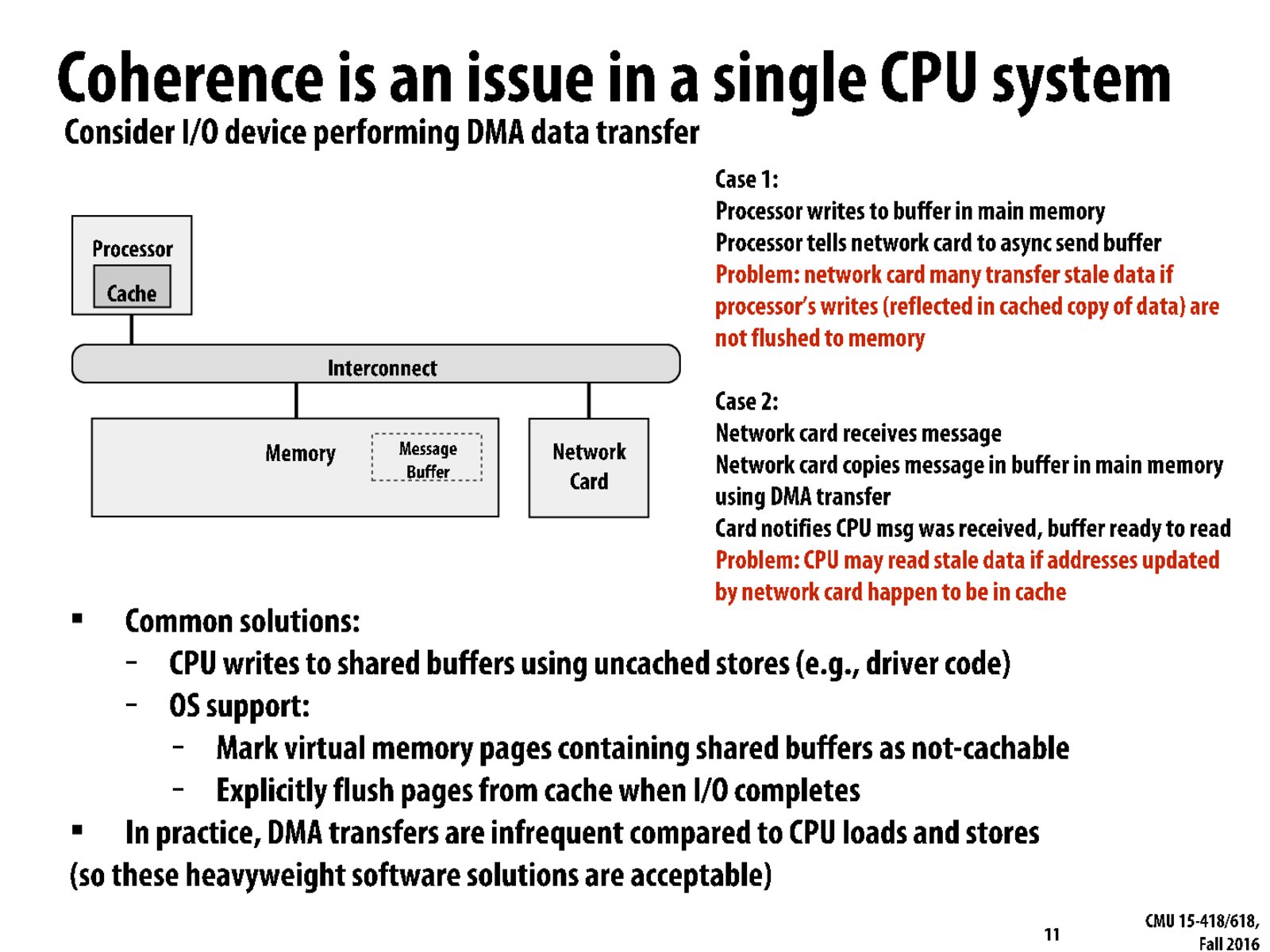
There is a similar facet of CUDA programming called "pinned memory", where the device is allowed to read and write memory directly to host memory via the DMA without involvement of the CPU.
@tclarke So how does CUDA solve this problem? They mark pinned memory as not-cachable as well?
Yes, the CPU is not allowed to hold in the cache any memory that is marked pinned. The GPU is allowed to get the data directly from host RAM.