So if what I took from lecture was correct, this is sort of like our cost array from assignment 4 (at least how I did it). There is a tradeoff where your local copy of parameters being updated with the latest version results in higher quality, but in this case the quality tradeoff isn't worth the overhead of transmitting all of the parameter values?
EggyLv999
Yep, that is correct. With the way that SGD works anyway, it's not a very exact process, and isn't actually guaranteed to converge due to the random ordering of the training examples. This tradeoff would likely make little to no difference to accuracy but a huge one to performance-- and we can always slow down the learning rate or try to make it more accurate as we reach the end of the training phase to get more accuracy later.
nba16235
Just to add on EggyLv999's excellent comment, given a large amount of data, SGD and GD are equivalent to each other when reaching the optimum. The difference is that GD is deterministic while SGD is not, which means if you run GD many times you'll get the same result but given different orders of the training set, you may get different intermediate results from SGD.
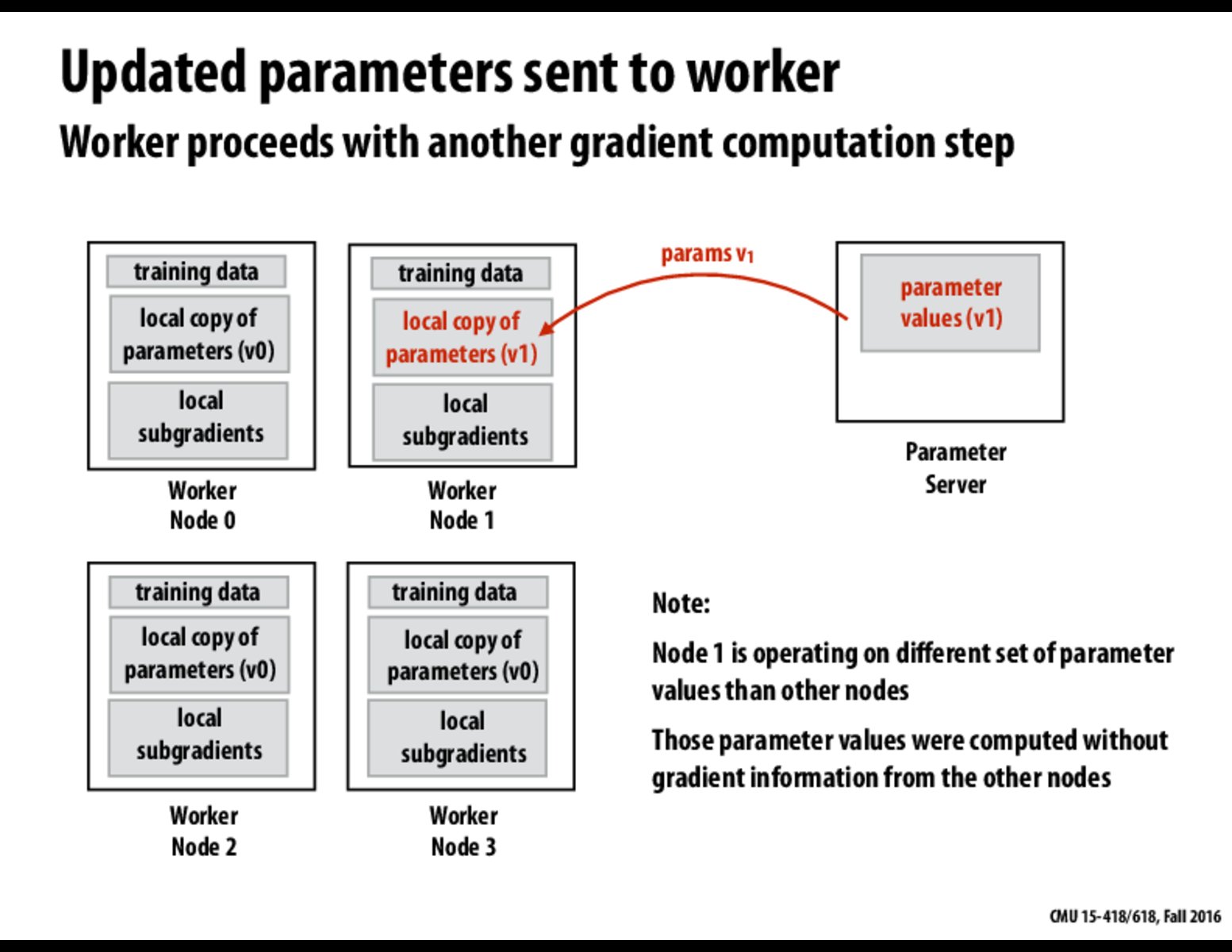
So if what I took from lecture was correct, this is sort of like our cost array from assignment 4 (at least how I did it). There is a tradeoff where your local copy of parameters being updated with the latest version results in higher quality, but in this case the quality tradeoff isn't worth the overhead of transmitting all of the parameter values?
Yep, that is correct. With the way that SGD works anyway, it's not a very exact process, and isn't actually guaranteed to converge due to the random ordering of the training examples. This tradeoff would likely make little to no difference to accuracy but a huge one to performance-- and we can always slow down the learning rate or try to make it more accurate as we reach the end of the training phase to get more accuracy later.
Just to add on EggyLv999's excellent comment, given a large amount of data, SGD and GD are equivalent to each other when reaching the optimum. The difference is that GD is deterministic while SGD is not, which means if you run GD many times you'll get the same result but given different orders of the training set, you may get different intermediate results from SGD.