Instead of returning a pointer to the allocated space (like C malloc), cudaMalloc returns a CUDA error code. So it has to return the allocation result in the first parameter. And the common way to do this in C is just: 1. declare a variable 2. pass its pointer to the function 3. the function change the value.
We can also write a wrapper function for cudaMalloc like this:
$$
void *CudaMalloc(size_t len)
{
void *p;
if (cudaMalloc(&p, len) == success_code) return p;
return 0;
}
$$
amolakn
I was curious about something in class. How expensive is this memory copying? I feel like it would be a significant bottleneck. Is there such a thing for the GPU and CPU to have shared memory address spaces?
flxpox
Rather than passing pointer, cudaMemcpy is more like a message that imforms the GPU to allocate the bytes of memory in the GPU device memory space.
ferozenaina
As prof said, CUDAMemCpy is closer to passing a message with the data content to GPU. This operation is pretty expensive and the bandwidth is limited by the PCI bus.
I don't think GPU and CPU can have a shared address space. However, the GPU and other devices on the PCI bus could - http://docs.nvidia.com/cuda/gpudirect-rdma/#axzz4LxQMnlAq.
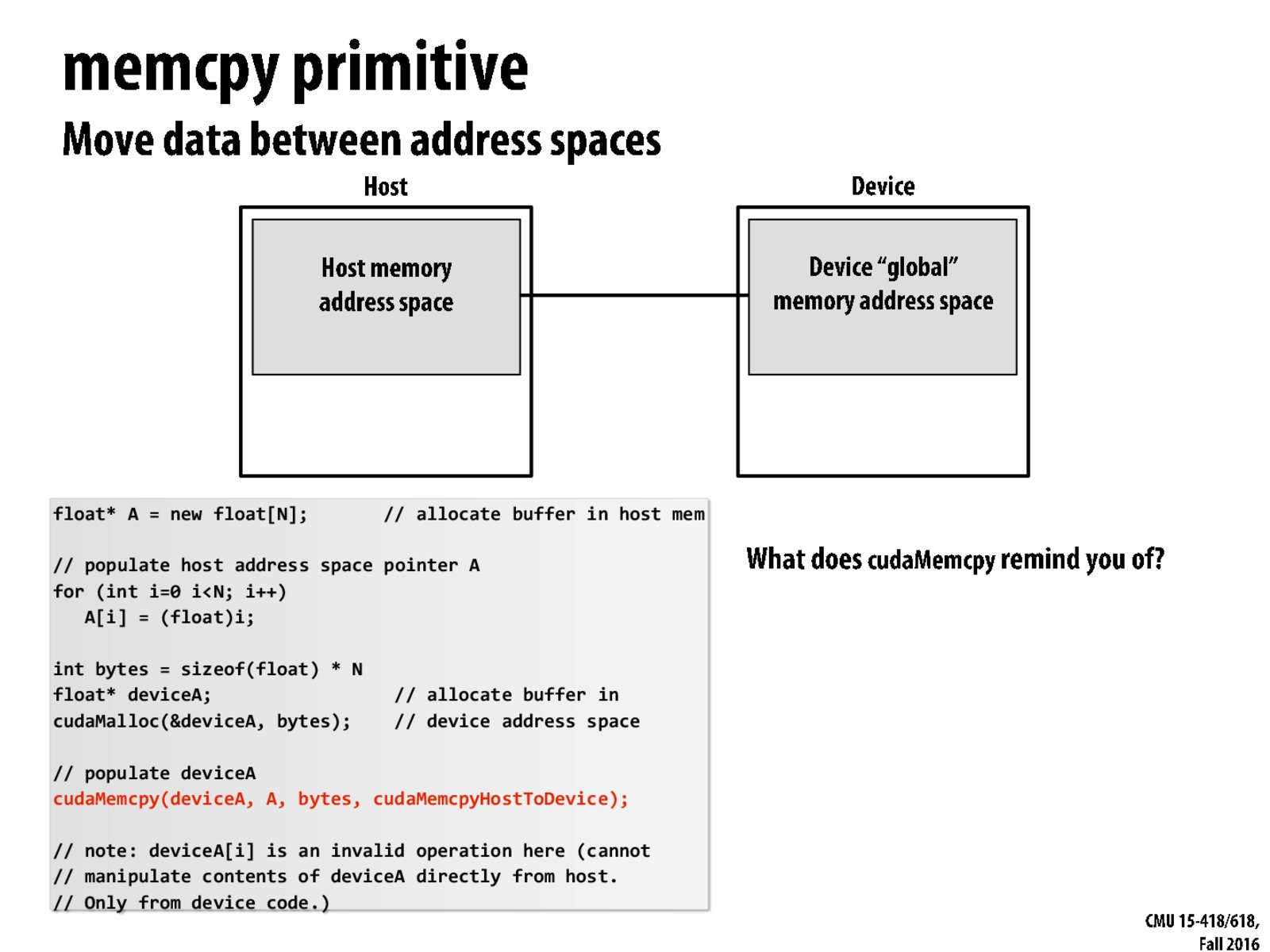
Why is $ cudaMalloc $ passing a double pointer (&deviceA;) instead of using a function prototype like C malloc: $ void *malloc$(size_t size)$; $ ?
As explained in StackOverFlow:
Instead of returning a pointer to the allocated space (like C malloc), cudaMalloc returns a CUDA error code. So it has to return the allocation result in the first parameter. And the common way to do this in C is just: 1. declare a variable 2. pass its pointer to the function 3. the function change the value.
We can also write a wrapper function for cudaMalloc like this: $$ void *CudaMalloc(size_t len) { void *p; if (cudaMalloc(&p, len) == success_code) return p; return 0; } $$
I was curious about something in class. How expensive is this memory copying? I feel like it would be a significant bottleneck. Is there such a thing for the GPU and CPU to have shared memory address spaces?
Rather than passing pointer, cudaMemcpy is more like a message that imforms the GPU to allocate the bytes of memory in the GPU device memory space.
As prof said, CUDAMemCpy is closer to passing a message with the data content to GPU. This operation is pretty expensive and the bandwidth is limited by the PCI bus.
I don't think GPU and CPU can have a shared address space. However, the GPU and other devices on the PCI bus could - http://docs.nvidia.com/cuda/gpudirect-rdma/#axzz4LxQMnlAq.