What's the overhead for partitioning graph vertices into intervals and then determining what data is relevant such as incoming vertices and such? I understand that this is increasing locality, but I wonder what the overhead trade off for this sharded distribution is.
acortes
The overhead is likely large but if you are reusing data frequently or have multiple iterations of running your algorithm on the nodes then preprocessing will lead to a significant increase in speed.
Split_Personality_Computer
Would these edges be stored as an edgelist to be most space efficient? Or would there be an attempt to make a local adjacency list to get the best of both worlds (memory and computation)?
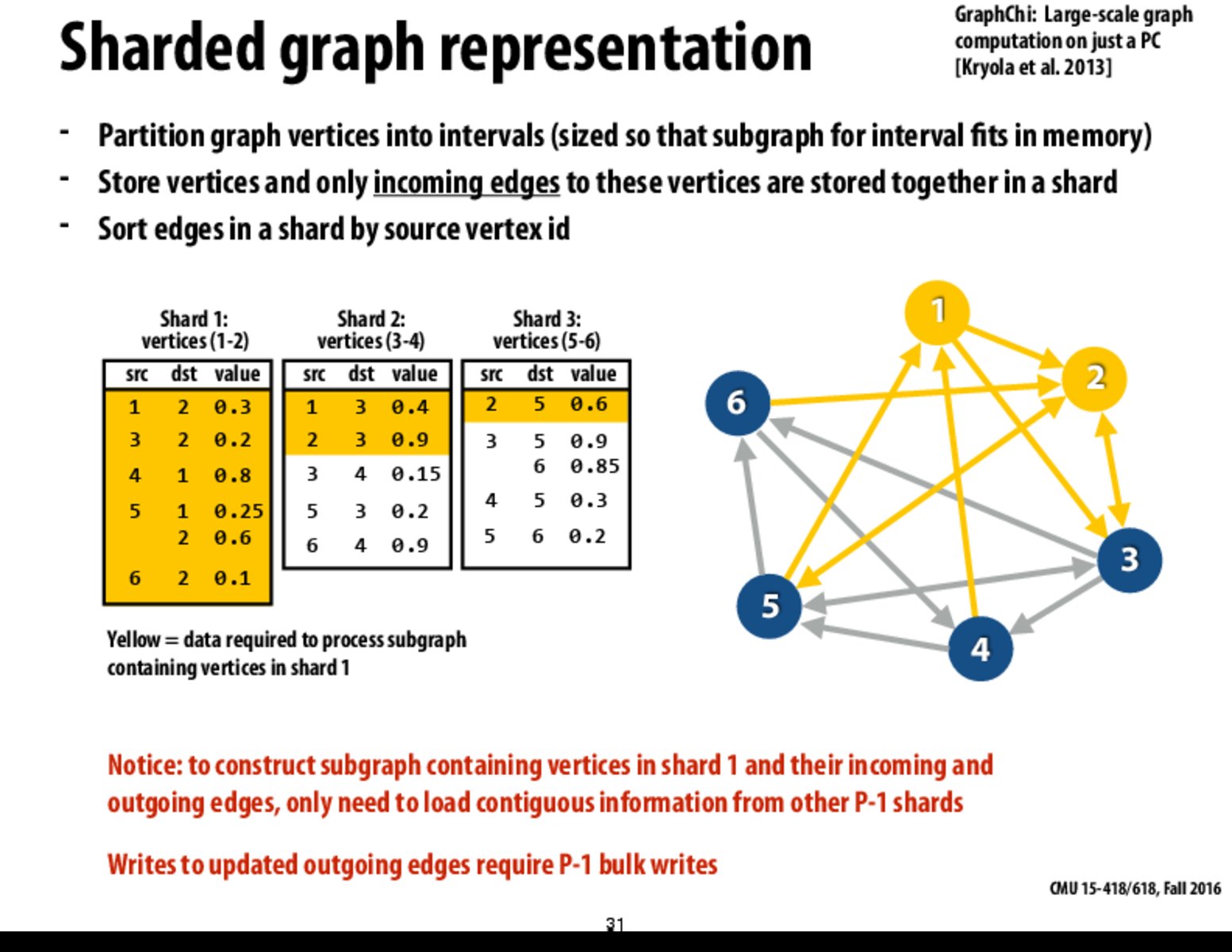
What's the overhead for partitioning graph vertices into intervals and then determining what data is relevant such as incoming vertices and such? I understand that this is increasing locality, but I wonder what the overhead trade off for this sharded distribution is.
The overhead is likely large but if you are reusing data frequently or have multiple iterations of running your algorithm on the nodes then preprocessing will lead to a significant increase in speed.
Would these edges be stored as an edgelist to be most space efficient? Or would there be an attempt to make a local adjacency list to get the best of both worlds (memory and computation)?