Introduction:
N-body simulation is a simulation of dynamic system of particles on their interactions. It simulates on how each body continuously interacts with other bodies under the influence of physical forces, such as gravity. A popular use of N-body simulation is an astrophysical simulation of a galaxy or stars. Other applications include protein folding using N-body simulation to caculate electrostatic and van der Waals forces, turbulent fluid flow simulation, and global illumination computation in computer graphics.
A naive solution to this problem is to use the all-pairs approach to N-body simulation, which is a brute-force technique that evaluates all pair-wise interactions among the N bodies. It is a relatively simple method, but one that is not generally used on its own in the simulation of large systems because of its $O(n^{2})$ computational complexity. We should notice that although in this naive approach, all values in the NxN grid of all pair-wise forces can be calculated in parallel, which gives us $O(n^{2})$ parallelism, the $O(n^{2})$ memory requirement would be substantially limited by memory bandwidth. Hence we will mainly focus on another approximation algorithm called Barnes-Hut that is more applicable in the real world.

Description:
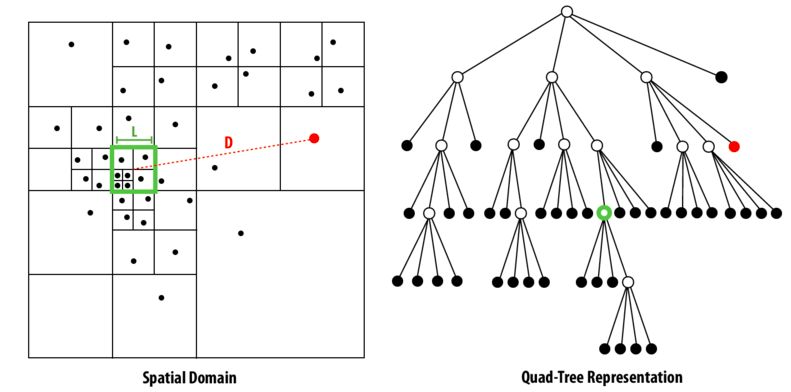
The Barnes-Hut algorithm is a notable algorithm for optimizing n-body simulation that has an O(nlog(n)) runtime. We will discuss the two dimensional version of the Barnes-Hut algorithm here. For the two dimensional version of the Barnes-Hut algorithm, we will recursively divide the n bodies into groups by storing them in a quad-tree. The root of this tree represents a space cell containing all bodies in the system. The tree is built by adding particles into the initially empty root cell, and subdividing a cell into for children as soon as it contains more than a single body. And as a result, the nodes of this tree are cells of the space that contain more than one body and the leaves of the tree are just single bodies. From the construction of the tree, we can see that the tree is adaptive in that it extends to more levels in regions that have high particle densities. And below is an example from lecture note of a quad-tree. From this example, we can see that the denser the particles are, the more level the tree has.
Then, to compute the net force acting on each body, we need to traverse the tree starting from the root and conduct the following test on each cell it visits: If the center of mass of the cell is far enough away from the body, the entire subtree under that cell is approximated by a single particle at the center of the cell, and we will compute the force contributed by this cell; if the center of mass is not far enough, we will go into the subtrees under that cell and recursively apply this algorithm on them. In addition, a cell is determined to be "far away enough" to be considered as a whole if the following condition is satisfied: $\dfrac{l}{d} < \Theta $, where $l$ is the length of a side of the cell, $d$ is the distance of the body from the center of mass of the cell, and $\Theta$ is a constant, which usually ranges between 0.5 and 1.2.
Problem Analysis:
There are two major issues when analyzing a parallel algorithm:
- Decomposition: Decomposition refers to the strategy used to partition the problem amongst the available processors. Data acquisition refers to the need to communicate between processors so that they have the data they need to carry out the necessary computations on their subset of the data. Decomposition is concerned with load balance, i.e., arranging that all processors finish approximately at the same time, and with minimizing the volume of communication.
- Data communication: Programmers must often be concerned with minimizing or hiding the large latency associated with every interprocessor message. This is achieved by overlapping communication and computation when the hardware supports it, and/or by buffering messages into large blocks which can be sent with the latency overhead of only a single message
Parallelism:
From the description of the Barnes-Hut algorithm, we can see that there are three main phases in the algorithm:
- Construct the quad-tree
- Compute the center of mass for all cells
- For each body, traverse the tree and calculate the force on that body
We can see that step 1 requires modifications on a shared data structure, which needs synchronization. For step 2, computation of the center of larger cells depend on the center of masses of their subcells, which introduces data dependencies, but can be parallelized on a per-level basis. And for the third step, although we need other particles' mass for computing the force, we don't actually need to modify this information, and therefore we can perfectly parallelize all these computations of the forces on different particles.
Work Distribution:
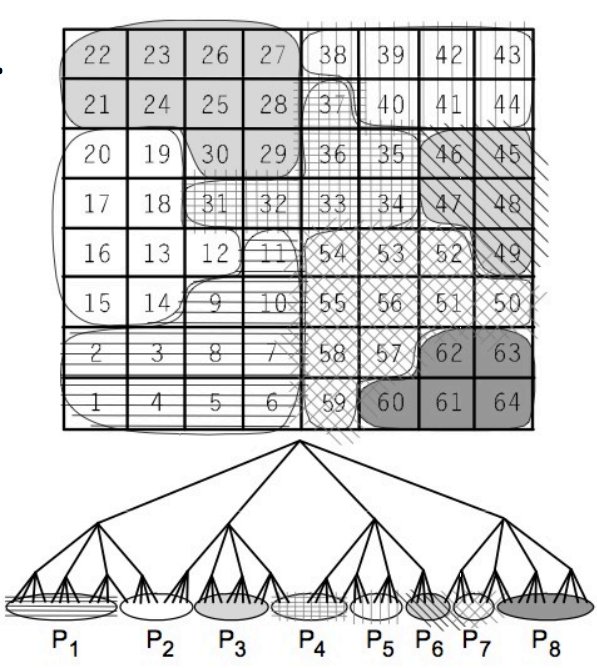
To utilize the maximum parallel computation power, we need to distribution the work evenly into each processor. Ideally, this partition of work should be spatially contiguous, which exploits the spatial locality, and also equal in size, which maximize the parallelism. To achieve this goal, we can use the idea of profiled load balancing. We should observation that the spatial distribution of bodies evolves slowly. And as a result, we can use semi-static assignment such that the total work is divided among processors, which gives each processor a contiguous, equal zone of work. And as the spatial distribution of bodies evolves slowly, we only need to update this assignment once a while. And other more robust technique for spatial locality is known as Orthogonal Recursive Bisection. And a detailed explanation of this technique can be find here.
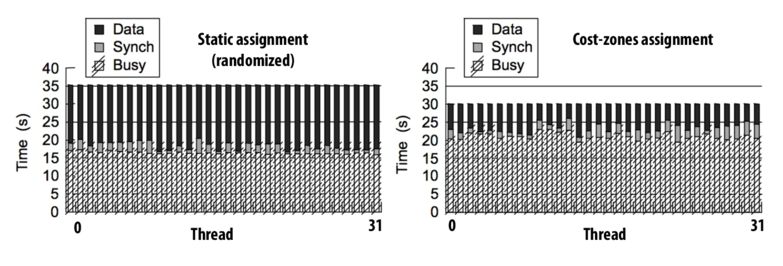
 Spatial localities of processers are improved by grouping adjacent data.
Spatial localities of processers are improved by grouping adjacent data.
If we divide work to each processors with good locality, it will boost the performance by good amount as shown in the image. However, "Busy" part of processors in the image might have increased due to some work that is required to group data and assign them to proccesors compared to randoming assigning processors their work. However, overall performance is definitely improved because there are less communication overheads.