Abstract
We like the intuitive behavior of a shared memory model, but modern CPUs aren't inherently cache coherent because the shared memory abstraction doesn't match the reality of caches. We can regain cache coherence through snooping, but this is complicated and can be expensive without effort on both the hardware and software sides.
Cache Design Review
Basic Cache Model
Recall our basic model of a cache from 15-213: an array of cache lines, like the one pictured below.
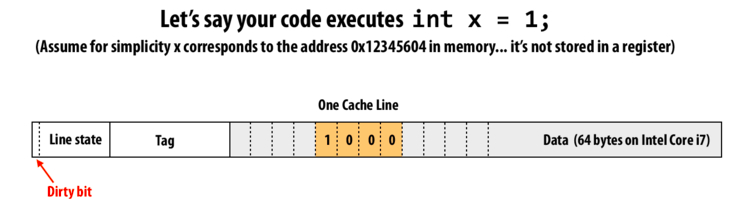
Cache lines consist of flag bits, a tag, and 64 bytes (on all x86 processors in the last few years) of cached memory. The flag bits vary from architecture to architecture, but will usually contain some sort of "dirty bits" which is set when the cache contains changes that should eventually be flushed out to main memory. The tag partially identifies what memory the line is currently caching; the rest of the identification comes from the index of the cache line itself. For example, if an integer x, backed by the memory address 0x1234604, resides in the cache, the last 6 bits in the address, 0x4, determine the byte-offset into the cache line x is at; the next lowest n bits determine the index of the cache line where x resides; and the high order 64 - 6 - n bits are stored in the tag, to prevent confusing 0x1234604 with, say, 0x2234604. (Note that caches don't necessarily use exactly the middle bits to determine the index of the cache line.)
Different Cache Protocols
There are different ways in which updates to cached memory can be made. A Write-Through policy updates main memory directly every time a change is made. However, a Write-Back policy is able to avoid these expensive writes to main memory by making these updates in the cache: when data in a write-back cache needs updating, its value in the cache is updated and the entry's 'dirty bit' is set. It is only when the entry is evicted that the write actually goes out, and a main-memory transaction occurs. In the former case, the cache is used to provide quick access to variables with recently-used values; in the latter, the cache is also used to store a modified version of the data for inexpensive updates.
There are also different ways in which updates to memory not currently in the cache can be made; a Write-Allocate cache will bring the target address into the cache and make the update to the cache, whereas a Write-No-Allocate policy will change main memory directly without loading a line into the cache. Since its policy dictates that all reads of new data will end up in the cache anyway, most write-allocate caches will also be write-back. It's worth noting that most CPU caches will be write-allocate, write-back.
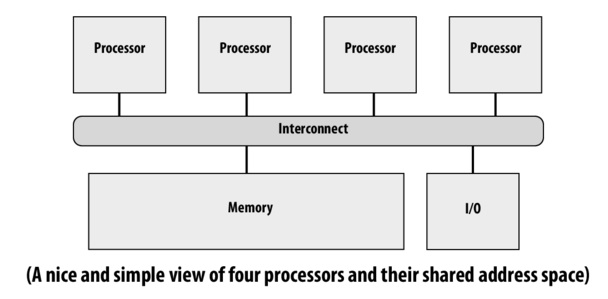
When thinking about a multi-processor system, we assume that each processor will have its own cache, connected as parts of the same memory system. This means that data from main memory may sit in some, all or none of the individual caches; without special care, a set of write-back caches might each contain their own differing changes to the same bit of data, which clearly has the potential to cause problems.
The Cache Coherence Problem
Intuition vs Reality
Stepping away from implementation details, let's consider how the abstraction of a shared-memory system should behave: intuitively, we expect that when updates are made to data, subsequent reads reflect these changes; specifically, we expect that a read from a given address will return the last value written by any participant in the memory system.
We don't get this behavior for free, because the shared-memory abstraction isn't a particularly close fit to the reality of caches. A processor with cached data has no inherent way of knowing when a second processor changes the underlying memory (and can't always be checking the underlying memory, because that defeats the point of a cache!). An I/O device which reads or writes to directly to main memory, like a network card or modern hard drive, has no way to tell if a processor has a dirty page waiting to be flushed out, potentially missing updates or updating the data itself without invalidating the cached version. The slides give more such examples.
There are further obstacles to implementing a system that follows intuitions: the intuition is actually under-defined: for instance, what does "last write" even mean when we have multiple processors, and thus the potential for simultaneous updates? We need a more formal definition of the intuitive behavior, which we'll call coherence.
Coherence
A memory system is coherent if, at every step of execution, there is some hypothetical serial order of all memory operations that could have resulted in the current state. Specifically:
- When processor P writes to an address x, and then tries to read the data it just wrote, assuming no other processor has updated the value the read will reflect this last update.
- Write-Propagation: A write to address x will eventually be reflected by all future reads of every other processor (assuming no other updates occur in the interim). Note that, while coherence guarantees that propagation happens eventually, it makes no guarantees as to how soon. Consistency deals more specifically with this; will get to that in a later lecture.
- Write-Serialization: All updates to address x are seen in the same order across all processors: if processor 1 writes a 1 to address X, and processor 2 simultaneously writes a 2 to address X, every processor should be able to agree on the processor that actually wrote first.
The simplest solution is just to remove the source of the problem -- having independent caches. If every processor uses only a single shared cache which attends serially to the requests of each processor, then we clearly have coherence and all of the issues disappear (forget about I/O devices for now). Of course, this doesn't scale: even in consumer CPUs, cores use the faster, private L1 and L2 caches in addition to a shared L3 cache.
Snooping
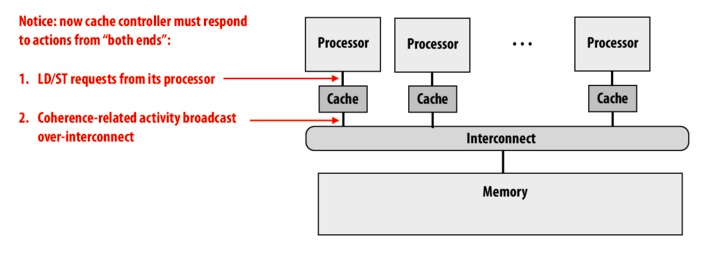
One approach to ensuring coherence among separate caches is cache snooping, whereby cache controllers "snoop" on and can respond to memory operations being performed on a different cache. For example, a write-through system upholding coherence via cache snooping could have processor making changes to a value will 'shout' this update to the other processors (actually, cache controllers), which will respond immediately by invalidating their now-obsolete cached versions, and thus forcing reads from main memory of the new value on their next access of that value.
It's much more complicated to get coherence with independent write-back caches; see the slides about the MSI protocol which involves flagging cache lines with ownership, and broadcasting intents to modify and such. The slides also cover additional protocol for coherence, which increase efficiency at the expense of becoming quite complex, there's a lot of messages cache controllers have to send and listen to, and lots of actions controllers have to take. This in itself is hard to do efficiently, as messages cause traffic on interconnects, and controller actions can delay memory operations issued by the processor.
No matter how it's implemented, cache coherence -- that doesn't simply ditch the caches -- has a significant overhead. Indeed, modern GPU do not implement coherence, on the design choice that the overhead isn't worth the convenience of the shared memory abstraction.
An Additional Remark
Because caches operate on a per cache line basis, "false sharing" can occur when processors are working with different bits of memory that happen to be in the same cache line; for example, if processor 1 interacts with an integer at address X, and processor 2 interacts with an integer at X+16 that is in the same cache line, expensive coordination is necessary to maintain coherence even though the processors are working on independent data: when processor 1 flushes the cache line out to memory, it could overwrite changes made by processor 2 to X+16 if the coherence protocols weren't in place. This false sharing can be avoided by taking care to keep unshared data away from other processors' unshared data, perhaps by using 64 byte aligned allocations where necessary.
Questions
- Why does caching tag with high address bits and index with middle address bits? Why not the other way around?
- Which combinations of Write-Though/Back and Write-Allocate/No-Allocate make sense, and which make no sense?
- How is GPU programming made different by the lack of cache coherence?
- What would be the performance consequences of overloading the interconenct with cache controller messages (such that latency is added to all interconnect operations)?
- Why might we expect standard CPU caches to be write-allocate, write-back?
- Cache coherence has significant overhead; GPUs are an example of a system where the convenience of the abstraction doesn't justify the cost of implementation. Under what circumstances might cache coherence be worth the expense?