



Question: Why is a dirty bit necessary in a write-back cache? Is a dirty-bit necessary in a write-through cache?
This comment was marked helpful 0 times.

A dirty bit is necessary if you have data in a cache line which differs from that of main memory. Since a write-through cache updates main memory, it would not be necessary to have a dirty bit if the write to memory will happen before the processor looks at this cache line again.
This comment was marked helpful 0 times.

When a cache line is evicted, if it is dirty, write data back to memory and mark as "not dirty".
This comment was marked helpful 0 times.

Will there be contention for a cache line?
I mean before step 3, two threads keep on evicting the current cache line.
This comment was marked helpful 0 times.

For two threads on the same processor, I don't think this would be a problem, because they would access the same local cache. But for different processors, this is what might bring the problem of cache coherence.
This comment was marked helpful 0 times.
@shudam: To clarify, you are correct that eviction of a dirty line cannot proceed until the line is written back to memory, but there's no need to mark the line as "not dirty" if it's being evicted, the line is not longer in the cache!
This comment was marked helpful 0 times.
@TeBoring: It's certainly the case that the execution of two threads on a processor (via any form of multi-threading: hardware multi-threading or software-managed threading) can cause one thread's working set to knock the other thread's working set out of the cache. (This is called "thrashing", and something programmers may want to be cognizant of when optimizing parallel programs).
To prevent the "livelock" problem I believe you are thinking about, any reasonable implementation will allow the write to complete prior to evicting the line in the future. What I mean is, if the cache line is brought into the cache due to a write, the update of the line will be allowed to occur (completing the write operation) before any other operation can proceed to kick the line out.
I think an example that's closer in spirit to what you are envisioning is contention for the same line between two writing processors. As we're about to talk about later in this lecture, to ensure memory coherence, the writes cannot be performed simultaneously. A write by processor 1 will cause processor 2 to invalidate its copy of the line. Conversely, a subsequent write by processor 2 will cause processor 1 to invalidate it's copy of the line. If the two processors continue to perform writes, the line will "bounce" back and forth between the two processor's caches. All this is discussed in detail beginning on slide 17.
This comment was marked helpful 0 times.
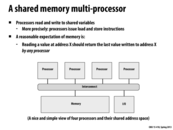

Real-life example of the reasonable expectation of memory is if you told your friend to write something on some paper, and they come back and say 'okay, I've done it,' then you'd expect to see that writing when you go back to look at the piece of paper.
This comment was marked helpful 0 times.

Question about the term last value? What is the last value written to address X? The last write issued by any processor before the load(read) instruction is issued? Is the memory system serialized when multiple read and write comes from multiple processor?
This comment was marked helpful 0 times.
@fangyihua: Exactly! Coherence provides a proper definition of last value. See the later discussion of write serialization.
This comment was marked helpful 0 times.


This example shows us the problem with cache coherence among multiple processors. As we can see, each processor has its own cache in which they store and read from. So, when P1 stores x it is marked with a dirty bit and stored as 0 in memory because it is a write back cache, implying that the cache line is not immediately updated. As P2 and P3 load and read x as 0, we realize that the processors can get out of sync because the value that the processors store is not reflected in the machine. This is where how the cache coherence problems comes about.
This comment was marked helpful 0 times.


Mutual exclusion is a problem associated with atomicity, which we have no problems with since our loads and stores aren't even concurrent in this example, so locks can't help fix it. Cache coherence is more of a problem with not having the latest "version" of a variable available to every processor as soon as it is modified by one. More in-depth description of cache coherence problem in the slides to follow.
This comment was marked helpful 0 times.
More importantly, loads and stores are atomic actions by definition (the hardware guarantees this... even without coherence). We require mutual exclusion when we want a series of hardware actions to be atomic, such as the sequence load,increment,store.
This comment was marked helpful 0 times.

So, from the previous slide and this one, it seems that the cache coherence results from the situation where the latest variables are not visible to the others. I am curious, despite of the efficiency, will write-through just solve this problem?
This comment was marked helpful 1 times.
@yingchal: Write-through behavior alone doesn't provide a coherent address space. Processor 1's write to X might immediately propagate to memory, but a copy of X might exist in processor 2's cache. Until X is evicted from processor 2's cache (if ever), processor 2's reads of X will return the stale value.
However, as shown on slide 18 the combination of write-through and invalidation of other cache's data on writes is sufficient to provide coherence.
This comment was marked helpful 0 times.

Question: What is a good non-CS analogy for the cache coherence problem?
This comment was marked helpful 0 times.

A non CS analogy might be a bank account analogy. You have multiple people viewing the balance of an bank account. And lets say, one person deposits money into the account or withdraws money from the account. Then every other person needs to be notified of this change. Otherwise, they would get a incorrect balance.
This comment was marked helpful 0 times.
@akaskr: But one detail you left out is that you need each party to have acted on a copy of their bank records that has gone stale.
This comment was marked helpful 0 times.

To extend this metaphor a bit further, say one person deposits a check into the account and updates his own records accordingly. Since the bank won't process the check immediately, if someone else copies the balance into his own separate records before the check clears, he will then be working with incorrect account data.
This comment was marked helpful 0 times.
This may link back to the beginning of this course, Lecture 1, Demo 2. In this demo, four students who were adjacent to each other and computed the sum of a set of numbers, but could only communicate by writing on a single sheet of paper with one pen. Every student computed their partial sum and updated on the paper. To get the total sum, we need to sum up all the partial sum written on the paper. The cache coherence problem may occur when the final sum up step is preformed before the partial sum is completely updated.
This comment was marked helpful 0 times.

I think fight ticket booking system is a analogy for cache coherence problem. Each counter have a local copy of current empty seats. When one counter conduct a transaction, the state in other counters become stale until they refresh the state. Customers will see a wrong state if the local copy is not updated.
This comment was marked helpful 0 times.

Question: Why do you think did Intel chose to build 8-way associative L1 and L2 caches, but a 16-way L3 cache?
Question: What does "outstanding misses" mean?
This comment was marked helpful 0 times.

A 16-way associative cache will have a lower miss rate than an 8-way associative cache. Having a lower miss rate will reduce the number of times you have to go to memory to retrieve data - which is very expensive. I remember that it was said that 16 way associativity is more expensive than 8 way associativity, but how exactly is it more expensive?
This comment was marked helpful 0 times.
@askumar: By expensive, I meant it is a more complicated cache design. Once the cache determines which set an address to load resides in (using the middle bits of the requested address), it must check the tags for all lines in the set to determine if a valid cache line containing the line is present. There's twice as many lines to check in the 16-way cache than in an 8-way cache. This translates into the need for more cache hardware to perform more tag checks in parallel, or a longer cache lookup latency. The cache also has to manage a replacement policy for more lines.
Although I'm not an expert on this, I imagine it's more economical to build a 16-way cache as an L3 because you can get by with an implementation that's slower when performing its tag checks. First, as the last-level cache, the L3 is accessed less frequently. Second, an access that reaches the L3 has already incurred major latencies by missing the L1 and L2, so an extra cycle or two in the L3 access critical path doesn't have a huge relative effect on performance. In contrast, the job of the L1 (which services requests all the time) is to return data to the processor with as low latency as possible.
This comment was marked helpful 0 times.
Outstanding misses refer to the number of misses before you try the next level of cache. Since L1 is shared, I think its saying we try up to 10 times to find cached data in one of the 8 associative sets.
This comment was marked helpful 0 times.
@tpassaro: Not quite. The idea of outstanding misses is unrelated to how data "is found" in a cache. Anyone else want to give my question a try? Hint: out-of-order processing.
This comment was marked helpful 0 times.

From what I've read, I think the concept of outstanding misses is related to a "non blocking" cache. If a processor asks the L1 cache for data and there is a cache miss, instead of waiting for the request to be serviced by the L2 cache, the L1 cache has mechanisms to continue working on other requests. The first request that had to go to the L2 cache is the "outstanding miss." The L1 cache in this diagram could have up to 10 requests for such misses out at a time before it has to block.
This comment was marked helpful 2 times.

If you are asking yourself like I did what N-way associativity means, here is the answer :
Since the cache is much smaller than main memory, it has to have some mechanism to map main memory addresses to cache lines (not unlike a hash function). If any address can go to any cache line, the cache is called fully associative. If an address can only go to one single cache line, the cache is instead called directly mapped. Finally, if an address can be mapped in one of a set of N cache lines, the cache is said to be N-way associative.
This comment was marked helpful 0 times.


Direct memory access (DMA) is a feature of modern computers that allows certain hardware subsystems within the computer to access system memory independently of the CPU. Without DMA, when the CPU is using programmed input/output, it is typically fully occupied for the entire duration of the read or write operation, and is thus unavailable to perform other work. With DMA, the CPU initiates the transfer, does other operations while the transfer is in progress, and receives an interrupt from the DMA controller when the operation is done.
This comment was marked helpful 0 times.


This slide confused me for a while so here's my understanding. The problem here is DMA, Direct Memory Access. Communication between applications (running on the processor) and an external device (e.g. a network card) often communicate by reading from and writing to specific addresses in memory.
Case 1: This is the case when the processor wants to send data to the network card (say we want to send a packet over the network). The problem is that the network card will access the memory directly. But if we have a write-back cache, our data may not have been written to memory yet. The key point is that the network card does not access memory with the same pattern as the processor (read() -> cache -> main memory). Instead, the network card reads from a direct address.
Case 2: In this case, data is flowing in the other direction. The network card received a message and wants to pass it to the processor. It writes to the memory address and tells the processor that the data is ready. But if the processor has the addresses corresponding to the message buffer still in cache, it will read that data instead.
This comment was marked helpful 1 times.
Processor will not go to the main memory if the address is in the cache. However, other devices may update main memory directly, so the cache will have outdated value. In this way, the memory and cache are not synchronized.
This comment was marked helpful 0 times.


In order to guarantee consistency amongst the processors, we need to have a total ordering for their requests since everyone receives the same updates in the same order. This is difficult when multiple processors are involved since multiple processors could potentially perform actions at the same time. We run into the problem of how do we know which action should be completed first?
This comment was marked helpful 0 times.

@sjoyner In my view, program order across threads is not that important in the perspective of hardware. The hardware just promises the atomicity of every operation. For memory hierarchy, it needs to ensure the update of data to be observed by all caches. But it does no more than that. And program order across threads is what the programmers should pay attention to, because it is an software-level problem. Many methods and ideas, such as locks, have been developed to solve synchronization problem across threads. Interesting part of lock implementation is that its atomicity comes from the atomicity of single assembly instruction, such as xchg.
This comment was marked helpful 1 times.

Coherence: Every memory address has an ordering for every operation. The ordering should keep the ordering of the operations from a given processor since those operations already have a clearly defined order. A read operation should given back the last value given by a write operation. Therefore, nothing like the example on lecture 10, slide 5 should occur if we have coherence. These rules only apply for a given memory address. There is no rules on how operations in two separate memory addresses should occur relative to each other.
This comment was marked helpful 0 times.

Question: In the diagram on the right, P0 reads 5 after P1 writes 25. Is this suppose to be an example of when write is not propagated in time for the read? What does this mean about coherency?
This comment was marked helpful 0 times.
@Leek. Slide typo. The last line should be: P0 read 25 (sorry)
This comment was marked helpful 0 times.


Question Point 2 says "if the read and write are sufficiently separated in time". Doesn't a write operation end only after all the logic for cache coherence has been completed. So can this condition be re-worded as: "if the end time of write < start time of read."
This comment was marked helpful 0 times.

@mayank: This is an abstract definition, so saying "a write operation ends only after all the logic for cache coherence has been completed" isn't necessarily true. A memory system could be coherent without meeting your requirement (but still meeting the three requirements on the slide).
That said, I'm curious how this works on actual CPUs: do writes return before all the cache coherence logic is done? Anyone know?
This comment was marked helpful 0 times.
This is lecture 13!
This comment was marked helpful 1 times.

Just to explain write serialization with an example - with only one shared variable
Initially :
x = 0
Launch 4 threads on 4 CPUs :
Proc 1 | Proc 2 | Proc 3 | Proc 4
x = 1 | x =2 | while (1)| while (1)
print x | print x
With Coherence, output may look like :
Proc 3 : 00012... (or 0021111.....)
Proc 4 : 00112... (or 002221111...)
==
But if output looks like :
Proc 3 : 000221...
Proc 4 : 001122...
That indicates write serialization is broken. Hence coherence is not satisfied. It may be surprising, but there are processors which do not guarantee write serialization and will ask programmer to put synchronization barriers in order to ensure expected behavior. It makes sense because if you write such a program in real world scenario you'll probably want to add synchronization to enforce certain ordering.
(I'm forced not to use synchronization or another shared variable as flag in this example because here we're talking about coherence. As soon as we introduce two shared variables we start talking about ordering of loads/stores to two (shared) variables. Then the behavior is defined by consistency model of the processor - which is treated differently.)
This comment was marked helpful 0 times.

Is the example a counter-example to write serialization? I am a little confused.
This comment was marked helpful 0 times.
Yes, the provided example is a counter-example. There is no single timeline over operations involving X that is consistent with both the timelines observed by P1 and P2.
This comment was marked helpful 0 times.

A key point here is that coherence specifies the observed behavior of reads and writes to the same address (e.g., X). No where in this lecture do we discuss the relative ordering of reads and writes to different addresses (X and Y).
This comment was marked helpful 0 times.

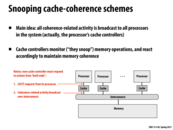
To use a sort of classroom demo to illustrate snooping cache coherence, let's say in 418 lecture everyone were a processor working on some calculation. Whenever anyone finished and wrote to the "main memory", they would yell out that that address had been updated. Everyone else would be listening for the yell, and if they had that address in their personal "memory" they would stop using it. With all the shouting you can imagine that it would get pretty loud and difficult to hear. The job of the interconnect is to handle all the yelling back and forth. For instance, if we had a webservice that handled all the shouting instead, that would be the interconnect in our classroom analogy.
This comment was marked helpful 3 times.
The individual cache must now handle 2 things: 1. load and store from its own processor. 2. handle the broadcast from other processors.
For this example, the interconnect will serialize all the broadcast by all the processor such that there will be only 1 broadcast request handled by the interconnect.
This comment was marked helpful 0 times.
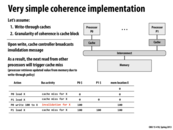

Once P0 writes to the cache, it lets all other processors know about this write. When this occurs, P1 invalidates the line in the cache. Since this is a write-through cache, the write is put straight into memory, and all subsequent reads from other processors yields the correct result.
This comment was marked helpful 0 times.
@thedrick: To clarify, you should say "before" P0's write completes, not "once". The cache coherence protocol specifies that P0's write does not officially complete until P0's cache controller confirms that all other processors have invalidated their copy of the cache line. "Once" implies the write occurs and then all the other caches invalidate.
Question: Is cache coherence preserved if P0's write completes AND then the invalidations occur?
This comment was marked helpful 0 times.
I don't believe coherency is preserved if P0 were to write then broadcast. Since the write is write-through, P0 would write to main memory, then after the write is complete, the other processor can read from that address if it were not already cached. If the value were cached, then they would read stale cache data.
If this is correct, then the other processors would need to acknowledge the message before they could resume processing. I believe this is called an IPI (interprocessor interrupt).
This comment was marked helpful 0 times.

@tpassaro It's morally the same as an (Intel) IPI, but this is at the hardware level (specifically the cache controller). This interprocessor communication cannot be seen by software.
It's interesting you mentioned IPIs though, as using those is one way to ensure TLB consistency in an SMP (those do not have the same coherency protocols real caches enjoy). It's like we both wrote code that does this or something...
This comment was marked helpful 1 times.
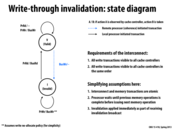

In this slide, we see a state diagram representing a simple cache coherence protocol (it assumes write-through, no-allocate caches). The cache line can be said to be in either one of two states: valid (dirty bit is not set) or invalid (dirty bit set).
Assuming we start in the invalid state, upon issuing a processor write, the cache line stays in the invalid state, as the write is made directly to memory (no-allocate policy). Seeing a write from another processor will result in a cache line in the valid state to transition to invalid state. The cache "drops" its line so that on the next read, it will observe the updated result.
A read or write, however, will result in a transition into the valid state.
This comment was marked helpful 0 times.
@Amanda: Everything you described is true except for the part of about the dirty bits. This is a write-through cache... so there's no concept of a dirty line. The writes always immediately propagate to memory. There are no dirty bits for cache lines, just valid and invalid states!
Also, I believe you mean "cache line" when you write "we" in paragraph two.
This comment was marked helpful 0 times.
Question: Why does a processor need to send a BusRd when it performs PrRd in invalid state?
This comment was marked helpful 0 times.
@Mayank You need to do a BusRd because you need to load the data from main memory, since your local version is invalid.
This comment was marked helpful 0 times.

Question: Describe an access pattern where a write-back cache generates as much memory traffic as a write-through cache.
This comment was marked helpful 0 times.

In a write-back cache, writes only go out to memory when the cache line is evicted and the dirty bit is set. So, if a system with a single cache-line (we're designing on a budget) had a load/write/evict pattern ad infinitum, there would be as much memory traffic as in a write-through cache. More concretely. $P_0$ loads address $X$, writes to address $X$, loads address $Y$ (which causes an eviction of the modified cache line and therefore a write to memory), writes to address $Y$, loads address $X$...
This comment was marked helpful 0 times.
What @gbarboza was getting at here was the situation where we have a direct mapped cache with (hopefully) more than one cache line in the cache. If we have multiple sets with one line each, but we bounce between writes between two locations with the same "set" bits (213 anyone?) we will have this thrashing behavior.
This comment was marked helpful 0 times.

As a refresher, see the discussion of dirty bits on slide 2.
This comment was marked helpful 0 times.

Write-through caches ensure memory always has the most up to date value stored in an address. This simplifies coherence, since to obtain the latest value stores at an address, the requesting processor can simply issue a memory load. Write-back caches pose new challenges to maintaining coherence, since the most recent value stored at an address may be present in a remote processor's cache, not in memory.
This comment was marked helpful 0 times.
@kayvonf Is it faster for one cache to supply data to another cache, or does it have the same cost as fetching the value from memory? Mainly, is there a fixed amount time for getting data around on the interconnect?
This comment was marked helpful 0 times.
I assume that traveling the interconnect is faster than going to main memory, but I'm curious if the cpu will send out a load request to each core and in parallel send out a request to main memory in case none of the cores have the value. The pipelining would mean this system takes just as much time to read from main memory as before, but may be too complicated to implement...
This comment was marked helpful 0 times.

@tpassaro While performing a load from another cache at the same (or lower) level would certainly require less time, I think the logic to implement such an operation would be prohibitive. The primary issue I see is that there isn't any way for one processor to know what's in another processor's cache without doing something silly like asking it to load the value (which could of course result in a load from main memory just as often as a cache hit). A shared memory controller could try to keep track of this information, but that's exactly the point of the next level of cache- if one proc pulled data in recently, there's a good chance that data is still in the cache which is the lowest common ancestor of the two (L3 in most architectures today).
This comment was marked helpful 0 times.
This comment was marked helpful 0 times.

Question: The first two bullet points on this slide describe two major principles of implemented cache coherence. Someone should try to put my description in their own words.
This comment was marked helpful 0 times.

When the dirty bit is set for a cache line that indicates the line is in the exclusive state. A processor with the dirty bit set is the only one that can have that line loaded - no other processors can have the line in their cache. Thus if a processor has a line loaded in the exclusive state it can freely write to it.
If a processor wants to write to a line that it does not have in the exclusive state it must first tell all the other processors it wants to write to that line by broadcasting a read-exclusive transaction. All the other processors that have that line loaded must then drop it. As the previous slide says, if another processor had it loaded in the exclusive state it is responsible for supplying the data since it is the current owner of the line and its cache is the only place where a valid copy of the data currently lives. Once the processor sending the read-exclusive gets replies back from all the other processors that they dropped the line it can then load the line into the exclusive state by setting the dirty bit and write to it.
This comment was marked helpful 0 times.

Specifically:
BusRdnotifies all processors the issuing processor is pulling the line into its cache for read-only access, and also fetches the line from memory.BusRdXnotifies all processors the issuing processor is pulling the line into its cache for read-write access, and also fetches the line from memory.BusWBwrites a cache line back to memory.
This comment was marked helpful 0 times.
Since BusRd is a transaction for read-only access, why must the processor fetch the line from memory? This transaction does not change other processors' behaviors with that cache line, correct?
This comment was marked helpful 0 times.
I believe this transaction doesn't change other processors' behaviors. Processor uses BusRd to get fresh data from memory when other processor has exclusive ownership of the data.
This comment was marked helpful 0 times.
@mitraraman, @martin: The answer to your question is provided in the precise description of the MSI coherence protocol on the next slide. There is no concept of "stale data" sitting in the cache. Either the line is valid (indicated by a line in the M or E state) and it contains the most recent copy of the data, or it is invalid (and thus can be thought of as containing no data at all).
Processors must broadcast a BusRd operation on the interconnect to inform all other processors of their intent to read. The coherence protocol requires the cache with the line in the exclusive state (if such a cache exists) to move the line to the S state (and thus perform no further writes) before the read by another processor is permitted to occur. Otherwise, the write serialization requirement of memory coherence could be violated.
This comment was marked helpful 0 times.
How does a processor determine whether the current request is a BusRd or a BusRdX? Does this only depend on the current single instruction, or is it influenced by the following instructions?
This comment was marked helpful 0 times.
@chaominy: When a read or write instruction issued by the processor triggers a cache miss, the cache must broadcast a BusRd or a BusRdX message (respectively) for the line to all other processors. See the protocol description on the next slide.
This comment was marked helpful 0 times.
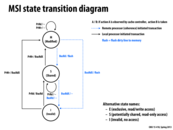
An optimization could be when a processor wishes to take a line from Shared to Modified (when it sends the cache a PrWr), since we already have the latest data (since the line is valid: it's in the Shared state), instead of BusRdX, we just need to broadcast that we have exclusive rights to it and don't need to completely reload it with BusRdX.
This comment was marked helpful 0 times.
@Xelblade: we could write the optimization you describe as PrWr/BusUpgrade. Like BusRdX, BusUpgrade is a transaction where all processors are notified that the issuing processor is taking exclusive access of the line. If differs from BusRdX in that BusRdX also includes the fetch of the cache line from memory. Adding a BusUpgrade operation is a useful optimization on the basic MSI protocol described here.
This comment was marked helpful 0 times.
Question: Why must the cache controller "drop" it's line (transition to the invalid state) when it observes a BusRdX on the interconnect?
This comment was marked helpful 0 times.
Someone intends to change the line, so the current information we have will become invalid in the near future. We don't want to keep reading and writing to outdated data so we drop to the invalid state.
This comment was marked helpful 0 times.
I know someone asked this question in the lecture but I'm still confused about the transition from M to I when the cache observes BusRdX for the line. I understand that the cache needs to drop the line to the invalid state because the data is no longer the most recent one. But why do you need to flush the cache line? Can you simply jump to I state from M and do nothing at all when you observe BusRdX?
This comment was marked helpful 0 times.
@martin I think if you are in M, you probably already has some changes in your cache, when you need to jump to I. You need to let everyone else know this change.
This comment was marked helpful 0 times.
@sjoyner: Correct. But by "we" you mean "the local processor's cache". And by "someone" you mean a remote processor. And @martin, by "you" you mean "the processor's cache".
Am I being ticky-tack... perhaps, but would these changes make your comments significantly more precise... most certainly.
This comment was marked helpful 0 times.

I think what @martin means is that since some other processor is going to write soon when BusRdX is received, why does the processor bother flushing and write back the currently-modified data to the memory (since it will be overwritten soon?). Can someone clarify this? Or by any chance, is that flush used to "flush" the dirty bits but not necessarily write to the memory?
This comment was marked helpful 0 times.
@raphaelk: The contents of the dirty line must be flushed to memory (or directly communicated to the processor that wants to write to the line) because processor reads and writes can be to individual words or bytes. Just because a processor is going to write to a line it does not mean it will overwrite the entire contents of the line. Consider the case where a 64-byte line X is dirty in processor 1's cache because the processor wrote to word 0 in the line. Now processor 2 wants to write to word 1 in the line. If the word 0 write was not flushed to memory, that write would be lost.
This comment was marked helpful 0 times.

Question: What is write serialization? Someone take a crack at explaining why the MSI protocol ensures write serialization.
This comment was marked helpful 0 times.

Write serialization means that all processors see the same ordering of reads and writes, ensuring that there can be an overall timeline of operations.
We said in lecture that the interconnect ensures reads and writes are ordered by the order that they appear on the interconnect. The trickier case is the writes on a cache line held exclusively by one processor. The key is that only this processor, P, can write to it while it has exclusive access, so the only ordering that exists is the one that P sees. When another processor requests to read the cache line, P, flushes the line meaning all other processors now see the same order of writes to that line that P did. Only then can the requesting processor read the line. Since the flushing and bus communication is done over the interconnect (which ensures an ordering), we are ensured that all those writes to the cache line by P will fit in some overall ordering that will be consistent for all processors.
This comment was marked helpful 0 times.


The difference between this and Slide 25: E state.
When some thread wants to read, it shout to all threads. If no thread care, this thread can go directly to E and it doesn't need to shout again if it wants to write later. If some one cares, this thread can just go to S. If it wants to write later, it needs to shout again.
I have a question: in distributed system, sometimes someone doesn't answer. Here, the current thread will get clear answers from all the other threads. Is that correct?
This comment was marked helpful 0 times.

@TeBoring. The "thread" here is different from what means in a distributed system. Here a thread is typically a CPU core, and I think it is reasonable to assume that the core won't crash and fail to answer during the transaction. But if you apply the protocol to other system, I think you have to consider such situations.
This comment was marked helpful 0 times.
@TeBoring: I want to make it absolutely clear that this slide is describing the operation of the processor's cache controller, not threads in a program. The state diagram above describes how the cache responds to operations involving a cache line in order to maintain memory coherence. These operations include: (1) Local processor requests for reading or writing to an address stored in the cache line. (2) Operations by other processors (more precisely, other caches) that involve the cache line. A cache controller learns of operations by other processors when remote processors broadcast this information over the chip interconnect.
This comment was marked helpful 0 times.

Here the benefit is that when a cache line is in E state, it does not need to send BusRdX on the bus and can directly execute PrWr.
This comment was marked helpful 0 times.
@monster, the other benefit is it decouples the exclusivity from the line ownership. so if the line is not dirty, copy from the memory is valid and can be loaded exclusively.
This comment was marked helpful 0 times.

Question: can anyone think of a reason why cache-to-cache transfers might be a detriment to overall performance?
This comment was marked helpful 0 times.
@kayvonf: I think cache-to-cache transfers might create a performance problem when the MESI protocol is used since there is no designated forwarder of the cache line in the S state. Thus you would have a lot of redundant data being sent if the line is loaded in multiple processors. For example, consider processors 1,2, and 3 all having some line loaded in the S state while processor 4 is in the I state. Processor 4 then sends a BusRd. Processors 1,2, and 3 would all have to respond to the request and send the data since there is no designated processor to handle the request. This results in the interconnect being bogged down with all this data being sent and processor 4 having to handle multiple copies of the data coming in.
This comment was marked helpful 1 times.
Another example is that the cache is occupied as the cache controller reads the cache line to send to the requesting cache. This could temporarily block the processor from accessing its own L1.
This comment was marked helpful 0 times.

Question: How does MESIF work? Specifically, how is the cache that supplies data in the event of a cache miss determined in MESIF? (BTW: Wikipedia has a nice description)
Question: How does MOESI work? (again, see Wikipedia)
This comment was marked helpful 0 times.

As mentioned above, only one cache can be in the F state for a given cache line. The way this works is that a LIFO (last-in, first-out) policy is used to determine which cache gets to be the "data provider" for the line; the most recent cache to request the line gets maintains it in the F state, while the previous holder transitions into the S state.
This comment was marked helpful 0 times.
In MOESI protocol, transition from M to S requires no flush. Instead, it defers the flush and transits into the Owned(O) state, and supply the modified data directly to the other processor. Other processors reading this line should be in S state.
If another processor tries to write to the line, it may tell the processors in O and S states to update their copies with the new contents and transit to S state, marking its own copy in the O state. This involves a transition of the Ownership of this line.
This comment was marked helpful 0 times.
The thinking in MESIF is that the last cache to request a line is the most likely cache to have the line well into the future. (The least likely cache to evict the line soon.) For simplicity, if a line in the F state is evicted, the next processor trying to load the line will retrieve the data from memory (even though there might still be other caches with the line in the S state).
To avoid this memory transfer, a more complex coherence protocol might instead try to promote a cache with a line in the S state to the F state in the event the F-state line is evicted. This would require the caches to coordinate to choose the new owner. It sounds complicated. As you are learning in this class, simplicity typically wins.
This comment was marked helpful 0 times.

If GPUs do not implement cache coherence, does this mean it is possible to have inconsistent data in the cache and memory of the GPU? Or do they just avoid coherence issues by only using shared caches?
This comment was marked helpful 0 times.
Yes, it is certainly possible. For example each SM core in an NVIDIA GPU has it's own L1 cache. There is a single shared L2 for the chip. My understanding is that the L1's use a write through policy.
The L1's are not coherent and it is certainly possible that a write by one of the cores is not observed by a subsequent read from another core. I believe however, that all memory operations are guaranteed to be visible by the next kernel invocation.
An interesting question is to consider what CUDA programs would benefit from full-blown support for coherence across the L1's. Note this would entail inter-thread-block communication, and CUDA does provide a set of atomic operations for this purpose. The atomic operations are explicit, and are treated specially not only to ensure atomicity of these operations, but also so that the other processors observe the updates.
This comment was marked helpful 0 times.

In the first case, many counters would lie on the same cache line as ints are only 4 bytes and they are contiguous in memory. There's lots of cache coherency issues requiring lots of communication to organize it since a single load will load variables that should be modified by threads other than the current one.
In the second case, we add junk bytes to reach 64 bytes so we don't have cache line overlap, trading memory for reduced communication.
This is called false sharing, as explained further on the next slide.
This comment was marked helpful 0 times.
It appears that using the GCC align keyword is the way to do this.
See this article.
This comment was marked helpful 0 times.
Question: Could someone elaborate on @Xelblade's statement about "lots of cache coherence issues?"
This comment was marked helpful 0 times.
If we had int myCounter[NUM_THREADS], we could reason that the entire array will fit into one cache line. So when each processor went to update its corresponding counter element in the array, it would first pull the line into its L1 or L2 cache. Since each processor has its own L1 and L2, we then have the case that each processor is modifying a cache-local copy of myCounter.
The issue that arises from this is that when one processor writes to its unique element of myCounter it causes all the other processor's cache-local copies of myCounter to become stale (because they all share the same cache line!). Therefore, the modifying processor has to push its changes back to main memory, and all the other processors have to pull in fresh copies from main memory before they can make their own changes to the array.
This comment was marked helpful 0 times.
@garboza: You got it. One clarification I'll make is that in MSI or MESI, the line would go all the way out to memory and then back to the requesting processor as you mention. But in MESIF, or MOESI, cache-to-cache transfers would eliminate some of these memory transactions.
Nonetheless, the issue at hand is exactly what you state: That the line is frequently being invalidated in processor caches due to writes by other processors to different data on the same cache line. This is false sharing!
This comment was marked helpful 0 times.
Question: In assignment 2 we used a similar array to indicate whether or not a circle was relevant (the array of booleans was shared among threads). However, this didn't cause issues because we were using GPUs which do not implement cache coherency right?
This comment was marked helpful 0 times.

Since cache is row-oriented, it is wise to break down matrix like this by rows instead of by columns. And it could limit the chance of false sharing shown in this example.
This comment was marked helpful 0 times.
@martin: Could you clarify what you mean by "row oriented"? A cache line contains consecutive memory addresses. (The cache has no knowledge of how data is mapped to the addresses.)
In the figure in the top right, let's assume the data is laid out in row-major order, so consecutive elements in a row correspond to consecutive memory addresses. In the figure, the processing of the 2D grid is partitioned down the middle of the matrix as shown. If two elements at the boundary of the work partitioning happen to map to the same cache line (which is the case in the figure due to the row-major layout), false sharing may occur between these processors.
It is false sharing, and not true sharing, if data need not actually be communicated between processors, but is communicated only because of the underlying granularity of communication of the machine.
This comment was marked helpful 0 times.
Question: Someone should try and write a simple piece of pthread code that shows off the effect of false sharing on the Gates machines. Report your timings and share the code with the class!
This comment was marked helpful 0 times.
I created the simple code below where I had 4 threads increment different integers stored consecutively in an array the maximum integer amount of times. I ran it on one of the Gates 3K machines and it ran in 52.241 seconds.
#include <pthread.h>
static void *increment(void* intPtr)
{
int* i = (int*) intPtr;
for(int j = 0; j < 2147483647; ++j)
{
*i += 1;
}
pthread_exit(NULL);
}
#define NTHREADS 4
int main(void)
{
pthread_t threads[NTHREADS];
int arr[NTHREADS] = { 0 };
for(int i = 0; i < NTHREADS; ++i)
{
pthread_create(&threads;[i], NULL, increment, (void*) &arr;[i]);
}
pthread_exit(NULL);
}
I then modified main as below to pad the array (according to proc/cpuinfo the cache line size is 64 bytes so I left 15 ints after the one each thread writes to). This new version ran in 15.827 seconds. So in just this simple example of incrementing integers false sharing led to code that ran over 3.30 times slower than similar code that didn't have false sharing.
int main(void)
{
pthread_t threads[NTHREADS];
int arr[NTHREADS * 16] = { 0 };
for(int i = 0; i < NTHREADS; ++i)
{
pthread_create(&threads;[i], NULL, increment, (void*) &arr;[i*16]);
}
pthread_exit(NULL);
}
This comment was marked helpful 4 times.

An example where nkindberg's code is applicable is when each thread is assigned its own independent counter. This kind of efficiency difference could easily be important when memory bandwidth is an issue.
This comment was marked helpful 0 times.


Here is an article that includes a an excellent overview of cache coherency on a modern intel chip.
This comment was marked helpful 0 times.
A write-through cache writes to memory every time you write to the corresponding cache item. A write back cache will just write to the cache (marking the dirty bit) and only "write back" to memory when it has to (when it is evicted from the cache) and only if the dirty bit is marked (meaning that the value was actually edited).
A write allocate cache will first bring the line into the cache before writing (in preparation to read/write it more later), while a write-no-allocate cache will simply perform the write directly to memory.
This comment was marked helpful 4 times.
EDIT: The address of
xon the slide has been changed to 0x12345604. During lecture it was 0x12341234. Note that since the cache has 64-byte lines, the last 6 bits in the address give the line offset. Although I drew the 4 bytes ofxstarting at line offset 4, it should have been at offset 52, since:0x12341234 & 0x3f = 0x34 = 52.I changed the address to 0x12345604 to fix the problem.
This comment was marked helpful 0 times.
Here's my own explanation because some things were not clear to me:
If I read an address
x, that address's data (and neighboring data in the same line) will be loaded in to the cache. If I then write data to addressx, the cache's version ofx's data will be changed. In a write-back cache, a dirty bit may be set if this write actually changes that data. When this data is evicted from the cache, if the dirty bit is set, the data will be written out to main memory. In a write-through cache, the data will be updated in the cache, and written to main memory right away.In a write allocate cache, if I write to memory address
xandx's data was not loaded into the cache by a previous read, addressx's data will be loaded into the cache. In a write no-allocate cache, addressx's data will not be loaded, and the write will go straight to main memory.This comment was marked helpful 3 times.
As mentioned in lecture, write back is usually paired with write-allocate to maximize the possibility and benefit of a cache hit, and x86 processors use this policy.
This comment was marked helpful 1 times.
I have question: why in the graph it is 1000 instead of 0001? Is it because
xis a variable in stack?This comment was marked helpful 0 times.
Question: @TeBoring has a good question. Who can answer it?
This comment was marked helpful 0 times.
@TeBoring Linux running on x86 architecture are little-endian machines meaning that the least significant bit is actually in the left most position. The wikipedia article on endianness goes into a lot more detail about both main types.
This comment was marked helpful 1 times.
Given their respective definitions, it was described that the relationship between a write back/through cache and a write allocate/no-allocate cache is "not orthogonal". For instance, it is very unlikely that you will have a write-allocate cache that is not write-back.
This comment was marked helpful 0 times.
@miko: A better example is that a write no-allocate cache that is write-back doesn't make a lot of sense. This is the example I should have used in lecture. I suppose a write-allocate cache that was write-through is useful if you believe the write is a predictor for future reads.
This comment was marked helpful 0 times.
Question: If endianness is the reason, why are the bytes not 01 00?
This comment was marked helpful 0 times.
An int is 4 bytes in this case.
1 = 0x00000001 (Big Endian)
1 = 0x01000000 (Little Endian)
If we leave off leading zeros. We get [1 0 0 0].
This comment was marked helpful 0 times.
@markwongsk Each square represents a full byte. I notice that the Wikipedia article that Thedrick referenced states that the little-endian version of "03 E8" is "E8 03", but each of those pairs represents only a byte.
If we wrote each byte out in pairs, than the number 1 would be "00 00 00 01", and so the little-endian version is "01 00 00 00", which the slide rights out as "1 0 0 0"
This comment was marked helpful 0 times.
@gbarboza, @zwei: Thanks that makes more sense now :) Didn't realize we were omitting the leading zeroes but I guess it makes sense if we are viewing 32 bit stuff.
This comment was marked helpful 0 times.