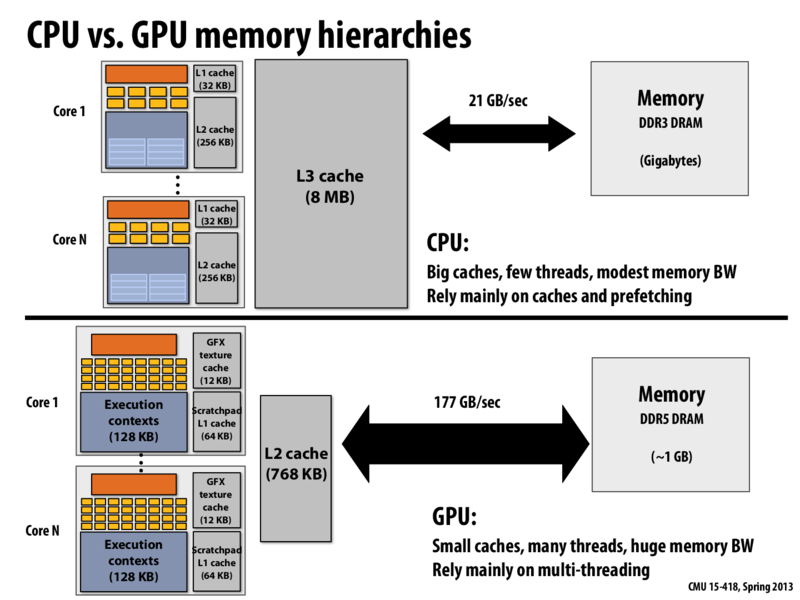
At first, I wasn't clear why the cache could be smaller for GPU, but I later understood that multi-threading hides the memory latency. And therefore, and as long as there is enough bandwidth to load the data while these threads are continuously working, then it effectively hides stalls.
While I was figuring this out, I also found another interesting article showing why GPU needs a smaller cache. This tells that because GPU is optimized for stream processing, it can easily identify independent blocks of the data, and therefore apply multi-threading and effectively predict bulk of data needed from the memory which increases cache efficiency (just like cachelab from 213).
This comment was marked helpful 1 times.
Xiao
Are the numbers listed on this slide full duplex bandwidth? Because I was playing around with my cpu, which was rated at a max bandwidth of 25 GB/s, using memory intensive applications. But I only managed to achieve a maximum throughput of about ~10 GB/s. Which would make sense if it is 10 GB/s on both ways, which adds up to ~20 GB/s. Could anyone verify or disprove this?
This comment was marked helpful 3 times.
evan
So it's 177 GB/sec from GPU to GPU memory - how fast is communication between the GPU and CPU/main memory? I'd assume it'd be much slower, but how much slower?
This comment was marked helpful 0 times.
kayvonf
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.
kailuo
I might have a misunderstanding here, but if GPU to GPU memory communication can be way faster (177 GB/sec) than CPU to main memory communication (21 GB/sec), how come they can't make CPU/main memory communication as fast? The concept of DDR3 and GDDR5 should not be mixed together I guess?
This comment was marked helpful 0 times.
kayvonf
@kailuo: Of course they could, but architects have decided it is not the best use of resources.
Remember, if you are trying to build a chip, one of your goals is to try to maximize performance for a certain set of workloads given some constraints. Examples of constraints include chip cost, chip area (which has direct correlation to cost), or chip power consumption.
CPU memory systems provide lower bandwidth because architects have determined it is a better strategy (for workloads they are most interested in) to rely on caches to absorb a large number of memory requests. If the CPU's cache handles most data requests, then there is less demand on the memory system to fulfill those requests.
In this class, it's often best to think about ratios. A CPU has less compute capability than a GPU. So it's reasonable to expect it will request data at a lower rate than a GPU. A good design will strike the right balance between compute capability and the ability to feed compute units with data. If you add to much compute capability, the compute units will idle, waiting on data. If you build too fancy of a memory system, it will be underutilized because the processor won't request data at a high enough rate. The right balance depends on workloads. You should also take a look at the discussion about arithmetic intensity on slide 60.
This comment was marked helpful 0 times.
TeBoring
GPU can depend on multi-threading to hide memory latency, but, for a single processing unit on GPU, it still needs to stall for the latency. Is GPU suitable for realtime applications?
This comment was marked helpful 0 times.
placebo
@kayvonf: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
Maybe one immediate result is that a programmer would want as little communication between GPU memory and main system memory as possible, since the PCIe bus limitation would place an inherent bottleneck between those two subsystems. But then this brings up the question of what types of programs can potentially saturate the PCIe bus? I understand that compression/encryption type applications can use a ton of CPU, while video processing/rendering can use a ton of GPU resources. What types of applications heavily rely on both resources (and thus might use up a ton of PCIe bandwidth)?
This comment was marked helpful 0 times.
tpassaro
The newer Intel/AMD chips now offer GPU/CPU processors on the same chip. Since the bandwidth to the processor is much less than that to the GPU, how is this a sustainable model? I could see that the processor could prefetch some amount of data for GPU operations, but even if you filled the entire cache of the processor with GPU data, a context switch could make these cache entries invalid. Is there some new technology that allows higher bandwidth from main memory to the processor?
This comment was marked helpful 0 times.
mmp
One reason that the lower sustainable BW is not a problem for the integrated CPU+GPUs is that their GPUs are less powerful than that discrete GPU with 177GB/s. They both have fewer ALUs and lower bandwidth, so in the end, the ratio of GPU ALUs to off-chip bandwidth is about the same on both systems. Thus, it should still have a reasonable balance between compute capability and feeding the compute units.
Regarding why CPUs don't have as much bandwidth: I'm not a memory system expert, but Kayvon's definitely right about different design points. One related factor is that the CPU's memory system tries to also be low latency when it goes to off-chip memory (i.e. if you've missed all the caches then hurry and get a result back from RAM), while a GPU's memory system in turn can be a little slower (since the GPU is already not latency-sensitive thanks to the massive threading). Thus, the GPU has opportunity to coalesce more memory transactions by waiting for more requests to come in, which can help.
My understanding is also that having those DIMM slots on your motherboard imposes costs in peak bandwidth as well (versus a GPU-like set up where the amount of RAM is fixed). GPUs can (and do, I believe) have direct connections between the pins coming out of the GPU and the DRAM pins, whereas if you have DIMM slots (not all of which may be filled, and where the amount of memory in each slot may vary), that flexibility reduces the maximum performance.
This comment was marked helpful 0 times.
edwardzh
@TeBoring Also, if the application cannot sustainably keep high occupancy on the graphics card, then the latency of the back-and-forth between the CPU and the GPU further diminishes the suitability of accelerating applications by computing on a GPU.
At first, I wasn't clear why the cache could be smaller for GPU, but I later understood that multi-threading hides the memory latency. And therefore, and as long as there is enough bandwidth to load the data while these threads are continuously working, then it effectively hides stalls.
While I was figuring this out, I also found another interesting article showing why GPU needs a smaller cache. This tells that because GPU is optimized for stream processing, it can easily identify independent blocks of the data, and therefore apply multi-threading and effectively predict bulk of data needed from the memory which increases cache efficiency (just like cachelab from 213).
This comment was marked helpful 1 times.
Are the numbers listed on this slide full duplex bandwidth? Because I was playing around with my cpu, which was rated at a max bandwidth of 25 GB/s, using memory intensive applications. But I only managed to achieve a maximum throughput of about ~10 GB/s. Which would make sense if it is 10 GB/s on both ways, which adds up to ~20 GB/s. Could anyone verify or disprove this?
This comment was marked helpful 3 times.
So it's 177 GB/sec from GPU to GPU memory - how fast is communication between the GPU and CPU/main memory? I'd assume it'd be much slower, but how much slower?
This comment was marked helpful 0 times.
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.
I might have a misunderstanding here, but if GPU to GPU memory communication can be way faster (177 GB/sec) than CPU to main memory communication (21 GB/sec), how come they can't make CPU/main memory communication as fast? The concept of DDR3 and GDDR5 should not be mixed together I guess?
This comment was marked helpful 0 times.
@kailuo: Of course they could, but architects have decided it is not the best use of resources.
Remember, if you are trying to build a chip, one of your goals is to try to maximize performance for a certain set of workloads given some constraints. Examples of constraints include chip cost, chip area (which has direct correlation to cost), or chip power consumption.
CPU memory systems provide lower bandwidth because architects have determined it is a better strategy (for workloads they are most interested in) to rely on caches to absorb a large number of memory requests. If the CPU's cache handles most data requests, then there is less demand on the memory system to fulfill those requests.
In this class, it's often best to think about ratios. A CPU has less compute capability than a GPU. So it's reasonable to expect it will request data at a lower rate than a GPU. A good design will strike the right balance between compute capability and the ability to feed compute units with data. If you add to much compute capability, the compute units will idle, waiting on data. If you build too fancy of a memory system, it will be underutilized because the processor won't request data at a high enough rate. The right balance depends on workloads. You should also take a look at the discussion about arithmetic intensity on slide 60.
This comment was marked helpful 0 times.
GPU can depend on multi-threading to hide memory latency, but, for a single processing unit on GPU, it still needs to stall for the latency. Is GPU suitable for realtime applications?
This comment was marked helpful 0 times.
@kayvonf: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
Maybe one immediate result is that a programmer would want as little communication between GPU memory and main system memory as possible, since the PCIe bus limitation would place an inherent bottleneck between those two subsystems. But then this brings up the question of what types of programs can potentially saturate the PCIe bus? I understand that compression/encryption type applications can use a ton of CPU, while video processing/rendering can use a ton of GPU resources. What types of applications heavily rely on both resources (and thus might use up a ton of PCIe bandwidth)?
This comment was marked helpful 0 times.
The newer Intel/AMD chips now offer GPU/CPU processors on the same chip. Since the bandwidth to the processor is much less than that to the GPU, how is this a sustainable model? I could see that the processor could prefetch some amount of data for GPU operations, but even if you filled the entire cache of the processor with GPU data, a context switch could make these cache entries invalid. Is there some new technology that allows higher bandwidth from main memory to the processor?
This comment was marked helpful 0 times.
One reason that the lower sustainable BW is not a problem for the integrated CPU+GPUs is that their GPUs are less powerful than that discrete GPU with 177GB/s. They both have fewer ALUs and lower bandwidth, so in the end, the ratio of GPU ALUs to off-chip bandwidth is about the same on both systems. Thus, it should still have a reasonable balance between compute capability and feeding the compute units.
Regarding why CPUs don't have as much bandwidth: I'm not a memory system expert, but Kayvon's definitely right about different design points. One related factor is that the CPU's memory system tries to also be low latency when it goes to off-chip memory (i.e. if you've missed all the caches then hurry and get a result back from RAM), while a GPU's memory system in turn can be a little slower (since the GPU is already not latency-sensitive thanks to the massive threading). Thus, the GPU has opportunity to coalesce more memory transactions by waiting for more requests to come in, which can help.
My understanding is also that having those DIMM slots on your motherboard imposes costs in peak bandwidth as well (versus a GPU-like set up where the amount of RAM is fixed). GPUs can (and do, I believe) have direct connections between the pins coming out of the GPU and the DRAM pins, whereas if you have DIMM slots (not all of which may be filled, and where the amount of memory in each slot may vary), that flexibility reduces the maximum performance.
This comment was marked helpful 0 times.
@TeBoring Also, if the application cannot sustainably keep high occupancy on the graphics card, then the latency of the back-and-forth between the CPU and the GPU further diminishes the suitability of accelerating applications by computing on a GPU.
This comment was marked helpful 0 times.