





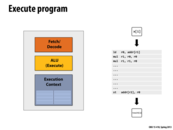

This diagram represents the extremely simplified model of a processor which we used in class. This is composed of three basic elements. The Fetch/Decode unit reads in the next instruction and determines what it needs to do, the ALU (Arithmetic Logic Unit) actually executes the instruction, and the execution context contains the state (through elements such as registers).
This comment was marked helpful 0 times.
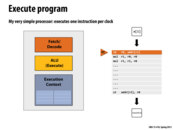
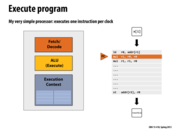
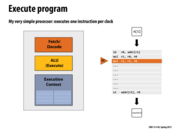
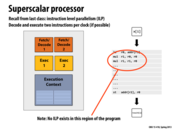

Superscalar processors exploit instruction level parallelism (ILP) in an instruction stream by using multiple functional units within a processor. The processor detects when independent instructions in the instruction stream are present, and it is able to dispatch more than one instruction per clock. This slide shows a processor with two functional units, and the ability to issue two different instructions per clock.
However, the amount of ILP in a program is limited by the presence of dependencies between different instructions. In lecture 1 we saw a graph showing that in practice, the maximum speedup processors can realistically achieve from ILP is about 3x.
This comment was marked helpful 0 times.

@mburman: Note that this 3x wall was specific to a system capable of issuing 4 instructions per clock cycle. A system which can issue more (8 wide SIMD execution, for example) would almost certainly surpass a 3x speedup in some cases.
Question: Based on the 3x speedup indicated by the graph, should we expect that executing 8 instructions per cycle would result in a 6x speedup (three quarters of the number of instructions per cycle), or a 7x speedup (one less than the number of instructions issued per cycle)?
This comment was marked helpful 0 times.

@FooManchu: I think may be mixing two different concepts: ILP that is present in a program containing scalar instructions (no explicit parallelism), and SIMD-style data-parallelism that is revealed by an application explicitly. The X-axis of the graph is the number of instructions that can be executed by a simulated processor, and the Y-axis plots the actual performance speedup.
The caption states that most of the possible speedup is obtained with an execution capability of four instructions per clock. This means that being able to execution more than four instructions per clock is unhelpful, since on average, there are only 3 parallel instructions at any point in the program. (You seem to have interpreted the title to mean the simulated processor can execute four instructions, but somehow issues more than four?)
This comment was marked helpful 0 times.


I believe the black boxes on this slide are where the processor tries to figure out where the parallelism exists in the code. At a high level, how does it accomplish that?
This comment was marked helpful 0 times.

I will try to be as simple as possible.
The retirement unit and reorder buffer are the last stage of that process. The whole process begins with the fetch unit, which fetches multiple instructions at the same time. Then they are passed to the register alias table (in between the orange and black box) which figures out the dependencies. At this point, independent instructions are moved down to the reservation station, where they await their operands (which could be memory or registers). Once all the operands of an instruction are ready, they are moved into the execution unit to be executed (yellow box). Multiple instructions could be moved into the execution unit at the same time, and the order at which they are executed is not necessary in order they are fetched, hence this whole process is called out-of-order execution. Finally, the results are passed back to the reorder buffer (which is the black box), where they are reordered back into the correct order. Retirement unit then does the last job of writing the results back to memory or register. The cpu uses this whole technique to identify ILP and run as many instructions in parallel as possible.
The other black box, the branch target buffer, should be the fancy branch predictor which decides which instruction should be fetched before resolving any conditional execution.
This comment was marked helpful 11 times.


Why do smaller transistors imply higher clock frequencies?
This comment was marked helpful 0 times.
From a wikipedia article about the Pentium 4 processor, "Making the processor out of smaller transistors means that it can run at higher clock speeds and produce less heat".
This comment was marked helpful 0 times.

For more info, I found this from realworldtech.com which discusses the relationship between the size of transistor and the transistor performance, and how High-k Dielectrics and Metal Gates allowed more shrinkage of the transistors with less cost in Intel's 45nm processors.
This comment was marked helpful 0 times.

I found this interesting article (http://www.quora.com/How-is-transistor-density-related-to-clock-speed-Why-does-higher-transistor-density-enable-faster-processors). I thought having more transistors would increase the size of circuit, increasing the critical path delay and power needed for the circuit. But, I believe the assumption is that "More transistors" -> more transistors in same/lower circuit size -> smaller transistors/circuit size that need less power -> higher clock frequencies. If the clock frequencies still can increase with bigger circuit size with more transistors, someone please enlighten me with more explanations!!
This comment was marked helpful 0 times.


If Moore's law implies that the amount of transistors we can fit into a certain amount of space keeps getting bigger and bigger, is it really necessary to decrease the sophistication of processor logic? Why can't we have the best of both worlds - several processors that are all just as sophisticated as the processors that came before the multi-core era?
This comment was marked helpful 0 times.

Given my knowledge of what's out there, I'd venture to say that even a singleton core on a modern processor is far more complex+powerful than those that came before the multicore era (e.g. one core of an i7 Ivy Bridge chip is faster and more sophisticated than say any Pentium 4), simply because of the many advancements that have come since then (SSE4 & AVX for example).
The impression I got from class is that you can always build a more complex single core CPU with the same number of transistors as today's multicore CPUs. But while those fancy add-ons would blow the multicore chip away in single-threaded applications, they'd only get you so far in multi-threaded apps since the power wall would limit the chip's highest clock frequency (arguably the single most important factor of single core chips). It wouldn't be able to compete with true multicore processors (which are still pretty complex in themselves).
This comment was marked helpful 1 times.
@tborenest: your thinking is correct. As @placebo says, it's really a matter of how sophisticated a single core is today, vs. how sophisticated a single core at today's transistor counts could be. You could implement very sophisticated branch predictors, prefetchers, huge out-of-order windows, and add in a huge data cache, or you could choose more modest implementations of all these features and place a few cores on the chip. Studies show the former would (for most single-threaded workloads) increase your performance a few percentage points, or maybe at best a factor of two. However, in the the latter case, you now have four or six cores to give a multi-threaded workload a real boost. I should change this slide to say: Use increasing transistor count for more cores, rather than for increasingly complex logic to accelerate performance of a single thread.
As keep in mind that by multi-threaded can mean multiple single-threaded processes active in the system, running on different cores. This is helpful on your personal machine when multiple programs are running, and it is very helpful on servers, where it's common to run several virtual machines on the same physical box.
This comment was marked helpful 1 times.
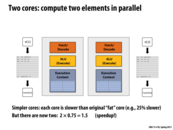


In the previous slide we demonstrated the benefit of splitting one powerful core into two slightly less powerful ones. In theory, since we have two cores running at 75% of the speed of the single core we should have 1.5x speedup on the tasks that we do. However, in this example, the code runs as one thread and can only be run on one core at a time. Therefore, if we were to run this on our "faster" two core setup, it will run 25% slower.
This relates directly to the first lecture where we talked about how software has to be parallel to see performance gains from multiple threads and cores.
This comment was marked helpful 0 times.

Even though we have 2 cores running at 0.75 times the speed of the original core, when we run this program we won't get a 1.5 x speedup. This is because the compiler is not capable of recognizing that everything inside the main for loop are independent instructions and could be done in parallel.
This slide makes the point that just adding more cores does not necessarily make a given program faster. The programmer must understand which instructions are capable of being executed simultaneously and thus, exploit the multiple cores.
This comment was marked helpful 0 times.


In this example, the wrapper function parallel_sinx() breaks up the work and parallelizes some of it by creating a new thread that runs sinx() on the first $N/2$ numbers and runs sinx() in the main thread on the last $N/2$ numbers. Thus, the potential speed-up is at most 2x, which is not very good considering this problem could be further parallelized with $ N $ independent sinx() calculations running.
This comment was marked helpful 1 times.

It depends on how many cores you have. If you have only two cores, it reaches best speedup if works are equally distributed. In that case, parallel with more threads will produce overheads.
This comment was marked helpful 0 times.

But in the later of this lecture, professor also mentions that, sometimes we also need have multiple threads per core to hide the stall.
This comment was marked helpful 0 times.
@yingchal: You are absolutely correct. However, you should also consider the above workload. It reads one value from memory x[i]. Then it performs a lot of math. Then it writes one value out to memory result[i]. So you can assume the arithmetic intensity of the program is pretty high. In fact, in this example, the parameter terms determines the arithmetic intensity of this program. If terms is reasonably large, the performance of the program is going to be largely determined by the rate the processor can do math. The potential stall due to the load of x[i] is only going to happen only once per cache line, and it's going to not effect the program that much.
(Advanced comment: this is such an easy access pattern that any modern CPU prefetcher will likely have brought the data into the cache by the time it has been accessed.)
This comment was marked helpful 1 times.


For anyone interested in learning how a compiler could decide whether to run a loop iteratively or in parallel without the programmer having to declare independent loop iterations, I came across the GCD test:
This test checks whether loops that modify arrays can be legally parallelized. Consider:
for(i = 0; i < 500; i++) { A[Ki + L] = A[Mi+N]++; }
where A is an array, and K, L, M, and N are constants.
Each iteration of this loop is independent if $\not \exists i_1, i_2$ such that:
K$i_1$ + L = M$i_2$ + N
Using (Bezout's Lemma, we know that there are no such $i_1, i_2$ if GCD(K, M) does not divide N-L.
Perhaps someone who has taken compilers could explain another method loop dependency analysis.
This comment was marked helpful 3 times.
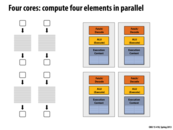
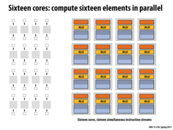

A dumb question:
Why don't we see machines with say 3 cores or 5 cores that often? Is there a specific reason to have 4 cores, 8 cores, 16 cores, etc.
This comment was marked helpful 0 times.

@choutiy: There are some commercial products with 3, 6, 10 or 12 cores. You can refer to here. Also, recall that GTX 480 has 15 cores instead of 16.
Given the transistors doubles every 18 months, it seems more reasonable to have 2^x cores. But if a company is willing to push out new product in the middle of the 18-month cycle, it have to end up with less cores.
This comment was marked helpful 0 times.


Recently released NVIDIA Tesla GPU K20 has 2496 cores. For more information, visit http://www.nvidia.com/object/workstation-solutions-tesla.html
This comment was marked helpful 0 times.
We should be careful how we count cores with all the company-specific terminology out there. As we'll discuss in a future GPU architecture lecture, NVIDIA's "CUDA cores" can't be thought of as 1-to-1 with CPU-style processor cores. The best analogy for a CUDA core, in the language of this lecture, is a single ALU/execution unit (one of my yellow boxes).
The GK110 chip that the K20 is based on has thirteen SMX blocks (SMX block ~ "core"). Each block as 192 single-precision execution units (we'll ignore the double-precision ones for now), which execute in a SIMD manner in groups of 32 (so for each SMX block there are six groups of 32 ALUs, each group executes in SIMD lockstep). Each SMX block interleaves execution of up to 64 warps (warp ~ "hardware thread"). Each clock, the SMX block selects up to four different runnable warps, and runs up to two independent instructions per each warp, so there's a total of up to eight instructions issued per SMX block per clock. As I said before, each instruction governs the behavior of 32 SIMD ALUs.
Complicated eh? So let's break it down:
There's thirteen SMX blocks (think cores). The unit of scaling the chip up or down is this block.
We're going to interleave processing of up to 64 independent instruction streams (warps) on each of these blocks. Instructions in the instruction stream execute 32-wide using what I previously called implicit SIMD execution.
The SMX employs both simultaneous multi-threading (four warps can be run at once) and interleaved multi-threading (scheduling for a total of 64 warps are managed by the SMX block). The chip also exploits ILP within the instruction stream of a warp: up to two instructions can be dispatched per cycle for each of the scheduled warps.
Where does the number 2,496 come from?
13 SMX blocks * (6 * 32-wide SIMD ALUs per SMX) = 2,496 single-precision ALUs clocked at 705 MHz.
What's peak single-precision performance, assume we count a multiply-add (MAD) as two floating point ops?
13 SMX blocks * 6 * 32 * 705 MHz * 2 = 3.5 TFlops
So the right comparison with a 3 GHz quad-core Intel Core i7 chip would be:
4 cores * 8 * 3 GHz * 2 = 192 GFlops
So for a workload that only performed multiply-add operations on a bunch of independent pieces of data, the K20 would be about 18 times faster than the quad-core Core i7. Would it be more power efficient as well? Likely so, but as @lkung points out, it's hard to compare TDPs reported by manufactures. Not only are there differences between reporting TDP as peak draw or average draw, the K20 TPD of 285 watts probably includes power expended by GPU memory, whereas the Intel Core i7 TDP of 80-100 watts likely does not. (Someone should correct me if I'm wrong on this.)
In a subsequent slide in this lecture about the older NVIDIA GTX 480 GPU, I draw similar comparisons between the generic terminology I like to use with the terminology NVIDIA uses.
Source: NVIDIA Kepler Compute Architecture Whitepaper
This comment was marked helpful 0 times.

The gates machines have 4 cores, which in theory, should reach their maximum speedup when we have 4 threads. However, in the problem 1 of the homework, the speedup of the program is even boosted when I create more than 4 threads. Can someone explain why that happens? Is it because of the hyper-threading? And can anyone give me a detailed explanation of what is hyper-threading please?
This comment was marked helpful 0 times.
@bosher, Gates' 5201/5205 machines don't have hyper-threading enabled. So you should reason that question using 4 cores, and you will have to come up with the explanation yourself :)
For a more detailed explanation of hyper-threading, slide 47 describes more or less how hyper-threading works. This is another interesting reading for hyper-threading.
This comment was marked helpful 2 times.

Some general stuff I read about the Xbox 360: It has 3 cores that have hyper threading. According to wikipedia the SIMD vector processor was modified to include dot product. According to this article the Xenon processor doesn't have any out of order execution and is short on branch prediction. The processor is slower in many ways in favor of having multiple cores and purposefully puts more of a burden on the programmer.
This comment was marked helpful 0 times.

@bosher, it happens because if the workload is not evenly distributed, then some threads could be sitting idle waiting for the one that takes the longest time to finish. Having more threads counteracts this. But having too many threads can be a bad thing as well because then a lot of time can be spent handling the assignment of work to the threads.
This comment was marked helpful 0 times.
@bosher and @aakashr. I want to make sure you understand that in assignment 1, many students decomposed the problem into many more ISPC tasks than machine processors. In your answer you said thread. If you are writing "thread" because you are thinking of pthread-style parallel execution (or thread execution context in the processors) you should take a moment to consider how many ISPC tasks are distributed to processors by the ISPC runtime.
This comment was marked helpful 0 times.
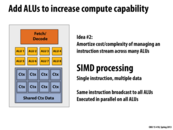

SIMD processing focuses on distributing data across parallel processors. The body of the loop in the sin function, for example, was essentially using the same logic every iteration, just on a different piece of data. In this idea, we take our ALU unit, and make eight of them. This lets us have our same processor that processes one instruction per clock, but actually executes it on eight pieces of data at once.
This comment was marked helpful 2 times.

a typical example would be C[i] = A[i] + B[i]. Assume this requires a lot of memory access, but this could be vectorized. And hence SIMD processing can executes on multiple (8 pieces of data in this case) at the same time. SIMD processing is more popular in GPU because images can easily have a million pixels and it is common that you may need to perform the same algorithm/operations on each (when you zoom in a picture for example). So it is very useful for GPU to have SIMD processing.
This comment was marked helpful 0 times.

To provide an even more concrete example of the applicability of SIMD instructions and vectorization, I spent last summer working at Microsoft adding auto-vectorization for averaging to their C++ compiler (getting the compiler to safely emit PAVGW and PAVGB instructions). Our main demo case was blurring image filters on bitmaps, where we got speedups of around 10-15x, which while below the theoretical maximum (16x if averaging 16 pairs of 8-bit chars in a 128-bit XMM register) was still appreciable.
This comment was marked helpful 1 times.

I'm wondering how are the ALUs and shared context data related? From the graph in the lecture slides, it seems that each ALU has its own buffer containing data. Is it always the case?
This comment was marked helpful 0 times.
The relationship between numbers of ALU's and context changes depending on what hardware is trying to achieve, which could be 1-to-1, N-to-1, 1-to-M, or N-to-M. For example, some superscalar execution (such as those involving out-of-order execution) involves mapping multiple ALU's to one set of context. This way it enables the cpu to issue multiple instructions that modifies the same context in parallel. SIMD might map multiple ALU's to one context or to multiple parallel contexts. Intel's SSE is an example of the former one; it uses multiple ALU's couple with one context of large registers, which can be used for one high precision floating point calculation or multiple vector calculations. For latency hiding, you pair multiple contexts with one set of ALU (which could be just one ALU), as described starting from lecture 45.
This comment was marked helpful 0 times.



As it turns out, the explicit intrinsics are actually unnecessary in this case: for the sinx program on the previous slide, gcc -O3 detects the data parallelism and emits vector instructions:
0000000000400520 <sinx>:
... <snip> ...
400575: 0f 59 c2 mulps %xmm2,%xmm0
400578: 0f 28 e2 movaps %xmm2,%xmm4
40057b: 0f 28 da movaps %xmm2,%xmm3
40057e: 0f 59 e0 mulps %xmm0,%xmm4
400581: 0f 57 c5 xorps %xmm5,%xmm0
400584: 0f 59 dc mulps %xmm4,%xmm3
400587: 41 0f 5e c2 divps %xmm10,%xmm0
...
This only works on simple programs and gcc -O2 does not generate vector instructions for sqrt.
This comment was marked helpful 0 times.

So what happens when this code actually runs on a cpu that does not support vector instructions? Does it just run each instruction that many times to get the computation done?
This comment was marked helpful 0 times.
@akashr: The processor throws an invalid opcode exception and your program is terminated. This is easy to see for yourself: Compile the ISPC programs from Assignment 1 using the --target=avx-x2 flag (you must edit the Makefile) and try and run the resulting binary on the 5201/5205 machines that do not support AVX instructions.
This comment was marked helpful 0 times.
Is it possible to have a compiler or OS figure out how large to make the vector based on the number of ALUs instead of hard coding 8?
This comment was marked helpful 0 times.

@bourne: GCC can (sort of) do it too, as @alex mentioned. Something like ISPC can do a better job. It's not really the OS's job to rewrite a program being executed at runtime.
This comment was marked helpful 0 times.

@bourne: to add to what @sfackler said, the way I see it, you're not hard-coding the 8 so much as you're hard-coding the entire function, because the compiler isn't yet good enough to vectorize your code for you, as @alex mentions regarding sqrt. I understand vector intrinsics as a sort of happy medium between regular C code and handcoded assembly. It's a sacrifice of portability for performance
This comment was marked helpful 0 times.

Unfortunately, merely the use of these %xmmN registers in a compiled binary is not sufficient to show that a program is actually performing vector arithmetic. The x86-64 calling convention uses the %xmm0-3 registers when passing floating point numbers and gcc will use them for simple floating point arithmetic. For example, the following code:
double foo(double x) {
return x + 0.0;
}
produces the following assembly:
00000000004004b4 <foo>:
4004b4: 55 push %rbp
4004b5: 48 89 e5 mov %rsp,%rbp
4004b8: f2 0f 11 45 f8 movsd %xmm0,-0x8(%rbp)
4004bd: f2 0f 10 4d f8 movsd -0x8(%rbp),%xmm1
4004c2: 66 0f 57 c0 xorpd %xmm0,%xmm0
4004c6: f2 0f 58 c1 addsd %xmm1,%xmm0
4004ca: 5d pop %rbp
4004cb: c3 retq
Note how even though the %xmmN registers are used, the math instructions generated only operate on one element of the registers. (See addsd above.)
This comment was marked helpful 1 times.


In case it's not obvious from the picture, the 128 ALUs come from the fact that there are 16 SIMD cores, each of which has 8 ALUs. 16 x 8 = 128
This comment was marked helpful 0 times.


Kayvon explained how this program contains parallelism in lecture: the 'forall' in the program executes the body of the loop on each iteration in parallel since the data is independent of each other. Would this example be similar to creating a pthread for each data iteration and then joining the pthreads after all threads have finished computing?
This comment was marked helpful 0 times.

@mitraraman Notice thread libraries, like pthread, may have their own scheduling algorithm, and their utilization of cpu resource is also affected by underlying kernel thread scheduling, ie, user level threading only tells the kernel that the work of different threads CAN be done in parallel, not necessarily so considering OS may choose to run them in other fashion depending on scheduling issue.
This comment was marked helpful 0 times.

Clarification: Imagine we want to execute the logic described by the pseudocode on the right for each element of a large array of numbers, and we want to do so as efficiently as possible on our fictitious processor which is capable of eight-wide SIMD execution. In the code, assume that there is an input array A, and that x is initialized to A[i]. Also assume there's an output array B and that B[i] = refl. The code segment on this slide should be changed to something more intuitive (I apologize).
Now consider the fundamental problem at hand. We have to perform a computation that logically may take a different sequence of control for each element in the input array, but we have a processor that operates by executing one instruction on eight execution units at once. We don't know what sequence of control each iteration requires at compile time, because the answer is dependent on the value of A[i]. How do we map this program onto this execution resource (given the constraints of the resource)?
This comment was marked helpful 0 times.
Looking at this diagram, it seems like each ALU is given its own tasks and execute on them. Then, it makes me feel like each ALU acts like a CPU, that has own registers, memory, and etc... However, from 18-240, Structure and Design of Digital Systems, we learn that ALUs are combinational logics with no memory, "where the output is a pure function of the present input only." Are these ALUs different in any ways or are they also combinational? or are we just generalizing the low-level implementation and just saying that each ALU is working on each task?
This comment was marked helpful 0 times.
As I've never taken 18-240, can someone explain to me what does it mean "combinational logic"... The answer to the question above will be greatly appreciated.
This comment was marked helpful 0 times.

@choutly Combinational logic is just any function whose output depends only on the input. For example, the addition function, given the same set of input, will always produce the same output and has no state. Checking your bank account on the other hand, depends on the all the transactions that occurred before it and thus has state.
This comment was marked helpful 0 times.


Here we see the case where a minority of the data elements (1,2,4) in the SIMD execution unit NEED to be processed by the more computationally expensive branch, however all elements WILL be processed by the instructions. The next few slides explain the intricacies of this situation.
This comment was marked helpful 0 times.


Examples of worst case: Switch statement with 8 branches (only one "lane" does useful work at once), or an if-else statement where one ALU does a lot of work in one case, and the other 7 get almost full parallelism out of the other case but is very short. In this case, one ALU does almost all the work.
This comment was marked helpful 0 times.

Are processors smart enough not to execute a branch if none of the "lanes" need it? Otherwise it seems like worst case could be arbitrarily bad.
This comment was marked helpful 0 times.
@mschervi: There's a critical point about this slide that I want to make, and it should be more clear once you write a bit of ISPC code in Assignment 1: The code on the right is a single sequential sequence of control. The variable x is meant to be single floating-point value (e.g., 'float x'). Now assume that this code might be the body of a loop with independent iterations, such as the forall loop I showed on slide 17. So let's say we're running this code for each element in an array 'A', and for each iteration of the loop x is initialized to A[i].
Now, we know we have SIMD execution capabilities on a processor and we'd like to make use of them to run faster. However, we have a program that's written against an abstraction where each iteration of the loop has it's own control flow. No notion of SIMD execution is present at the programming language level.
The problem at hand is how to map a program written against this abstraction onto the actual execution resources, which have constraints not exposed at the language level. (For example, the mapping would become trivial if if statements were not allowed in the language, forcing all iterations to have the same instruction sequence.)
On slide 33 I point out that the act of mapping such a program into an efficient SIMD implementation can be responsibility of a compiler or it could be the responsibility of the hardware itself (as in slide 34, and as you allude to in your comment about whether the processor is "smart enough" to perform this mapping intelligently). One example of the former case is the ISPC compiler. It emits SSE or AVX instructions into its compiled programs that generate lane masks, use the lane masks to prevent certain writes, and also generates code that handles the branching logic in the manner we discussed in class. The processor (e.g., the CPU in the case of ISPC) just executes the instructions it's told. There's no smarts needed. All the smarts are in the compiler.
If you really want to internalize what it means for a compiler to emit such code, you'll need to try doing it by hand once. That just happens to be the Program 4 extra credit on Assignment 1.
On the other side of the design spectrum, the compiler can be largely oblivious to SIMD capabilities of hardware, and most of the smarts can go into the hardware itself. To date, this has been the GPU-style way of doing things. Although we'll talk about GPUs in detail later in the course, here's a good way to think about it for now: The GPU will accept a mini-program written to process a single data item (e.g., you can think of the mini-program as a loop body) as well as a number of times the mini-program should be run. It's like the interface to the hardware itself is a foreach loop.
This comment was marked helpful 0 times.

@mschervi: Probably not, though conditional execution is usually only used for short sequences. Depends on how it's implemented. ARM for example would still "run" through the instructions, as the idea is to avoid control flow entirely.
This comment was marked helpful 0 times.

Can someone explain why is it that not all ALUs are doing useful work? So for this case, the ALUs in lanes 3, 5, 6, 7, 8 are not doing useful work? If that is so, is it because they run the computation for the 'true' case which is wasted in the end?
This comment was marked helpful 0 times.
@kuity That is exactly right - the ALUs 3,5,6,7, and 8 all 'do work' that is discarded for the 'true' case.
This comment was marked helpful 0 times.
@kayvonf Can you clarify a bit how GPU compilers are "largely oblivious to SIMD capabilities of hardware"? And how is GPU parallelism different from SIMD except the number of computing cores? From what I know, CUDA use the concept of "kernel", which is similar to "mini-program" we are talking about here. And the same kernel code is mapped on to many different CUDA cores. This seem to me very similar to SIMD, except NVIDIA GPUs usually have hundreds of CUDA cores.
This comment was marked helpful 0 times.

Remember that in divergent execution, SIMD can actually be slower than regular serial execution if the compiler compiles for SIMD at a higher width than the hardware can handle. We saw this in Assignment 1. For example, let's say the vector width of the hardware is 2 and the compiler is using a width of 4. If the first 3 elements take 1 cycle and the last one takes 8, then we will be using 9 cycles on the first two elements and 9 cycles on the last two elements, because for the purposes of divergence, the width is 4, even if the hardware can only do 2 elements at a time. So, it takes 18 cycles this way. But if we did it sequentially, it would only take 11.
This comment was marked helpful 0 times.

I was still a little unclear about what happens with exceptions or errors if both branches of the conditional are executed. If we don't have a way to handle or avoid this, how do we use this method? Does the language have to provide a way to deal with exceptions?
This comment was marked helpful 0 times.
I will use Intel's SIMD execution as an example. After compilation, the program is actually still sequential. There is a mask register which determines which lanes will receive side effects. Hence, if the mask bit of a lane is off, running through a branch does effectively nothing. In this case, the sample code would be translated into something along the lines of
SET_MASK(x > 0) // If the lane's x is > 0, then set mask as 1, else 0
y = exp(x, 5.f); // Every lane still performs these instructions
y *= Ks; // but only matters for those with the mask on
relf = y + Ka;
NEGATE_MASK // Do same thing for the other lanes
x = 0;
relf = Ka;
So to the processor, it looks like a normal program. For further information, here is how ISPC does it.
Now, in the case of a processor where every thread/warp could be doing something differently, this task becomes much harder, and it sort of boils down to how precise you want your exception handling to be. Saving the context of every one of the 1000+ threads and passing them to an exception handler sounds quite unrealistic. A way to do it is to have the processor remember checkpoints, which are states where execution was known to be correct, and fall back to the last checkpoint when it goes boom. Of course, this means exception handling will not be as precise as a CPU's exception unit, but this method can grant consistent recovery at a reasonable cost. Here is an ACM paper that explores this issue in more detail.
This comment was marked helpful 1 times.
In my (albeit limited) experience with languages that support these semantics, most don't have a high level mechanism for exceptions. I believe that most will only cause an exception if an active lane would error. For example, if the size of an array is not a even multiple of the number of lanes it is common practice to run all lanes but mask away any lanes that would be accessing invalid data.
Perhaps @kayvonf can offer some more insight?
This comment was marked helpful 0 times.
I'm still a little confused about this example. As shown by the graph above, it seems that ALU1, ALU2, and ALU4 are executing the true branch in parallelism taking advantage of SIMD, and afterwards the rest of the ALUs are executing the operations in the false branch. But I don't get why both branch can be executed in one loop iteration. Also, what are the rest of the ALUs working on (indicated by the red cross) while ALU1,2,4 are working on the true branch? Can someone clarify a little bit more for me?
This comment was marked helpful 0 times.

@martin ALU 1-8 are all executing the same instruction, but only ALU 1,2,4 allows to write the result into register or memory. The rest of ALUs do not stop working; since the mask can disable ALUs from writing, it seems that they are not doing any work.
This comment was marked helpful 0 times.


In computing, cache coherence (also cache coherency) refers to the consistency of data stored in local caches of a shared resource. (source: Wikipedia)
For example, in Intel architecture, each core has independent L1 cache. If some data in one L1 cache is modified, the related data in other L1 caches is stale. So it needs some extra action to ensure that the data read by other cores is the latest one. This property is called "cache coherence". Without coherence, it may result in severe synchronization problems.
This comment was marked helpful 0 times.


Although we were able to use all of these methods with our sinx example, none of them come off as a "perfect" method for taking advantage of SIMD. Intrinsics likely gives you the most precision to optimize the code, but puts a lot more work on the programmer and won't work with processors that don't support the instructions. Similar to "Kayvon's fictitious data-parallel language," MATLAB (though not a compiled language) has a parfor construct like used here with forall. The tradeoff when using parfor is that the interpreter needs to be sure that iterations are, in fact, independent, so it places restrictions on changing other variables in the loop body. As already stated, inferring parallelism likely will not be detected for intricate programs.
I guess the takeaway message is that we discussed so many different methods for making this one example (sinx) parallel because there isn't one right answer and knowing a variety of strategies is necessary to write effective parallel code.
This comment was marked helpful 0 times.

Is divergence a "big issue" because the program won't make good utilization of the floating point vector units?
This comment was marked helpful 0 times.
@sjoyner: It can be a big issue if you consider efficiency! A very wide SIMD width means it is more likely that you'll encounter divergence. (By the simple logic that if you have 64 things do, it is more likely that one will have different control flow requirements from the others than if you only have eight things do). When you have divergence, not all the SIMD execution units do useful work, because some of the units are assigned data that need not be operated upon with the current instruction.
Another way to think about it is worst-case behavior. On an 8-wide system, a worst-case input might run at 1/8 peak efficiency. While that's trouble, it's even more trouble to have a worst case input on a 64-wide system... 1/64 of peak efficiency! Uh oh.
So there's a trade-off: Wide SIMD allows hardware designers to pack more compute capability onto a chip because they can amortize the cost of control across many execution units. This yields to higher best-case peak performance since the chip can do more math. However it also increases the likelihood that the units will be not be able to used efficiently by applications (due to insufficient parallelism or due to divergence). Where that sweet spot lies depends on your workload.
3D graphics is a workload with high arithmetic intensity and also low divergence. That's why GPU designs pack cores full of ALUs with wide SIMD designs. Other workloads do not benefit from these design choices, and that's why you see CPU manufactures making different choices. The trend is a push to the middle. For example, CPU designs recently moved from 4-wide SIMD (SSE) to 8-wide SIMD (AVX) to provide higher math throughput.
This comment was marked helpful 0 times.
Kayvon's comment on lecture 1, slide 30 might help.
Divergence in code execute (e.g., if/switch statements) results in SIMD lanes getting masked. This inhibits performance since you aren't using the entire SIMD width of the target architecture which effectively slows things down.
Edit: I guess Kayvon beat me to it :)
This comment was marked helpful 0 times.
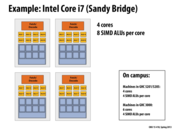
I missed the explanation for how much speedup we get for this. Can someone explain again?
This comment was marked helpful 0 times.
32x (4 cores x 8 SIMD) should be a theoretical limit for this example. Professor K's laptop achieved 44x performance because it had hyperthreading, which doubles the threads ran. Of course, communication and other overheads prevents it from hitting the theoretical limit of 64x when using hyperthreading.
This comment was marked helpful 0 times.
@Xioa: The real-life hyper-threading example has a complex answer, but you should reconsider your claim that about the 64X speedup. As you correctly state, there is only 32 times more processing capability on this slide than on my original simple chip. So why would you expect to see a 64X speedup?
I also recommend that folks with modern laptops measure the speedup of Assignment 1 programs like Mandelbrot_ispc_with_tasks and sqrt on their own machines to see if you can replicate my 44X number. Note that you'll have to change your ISPC build settings in the Makefile (this is discussed in the assignment.)
This comment was marked helpful 0 times.
I think 64x would be achievable (in the sense of coming near to it) if the program is structured such that the memory fetching of each thread is perfectly in synch with the execution of the other thread. I'm thinking of something along the line of slide 47, but with 2 threads and without the gap between end of stall and resuming execution. In such a case, each core would finish running two threads when sequentially it could had only finished 1, hence hyperthreading alone would grant a 2x improvement. Adding this to every SIMD core, would lead to a theoretical upper bound of 64x (4 cores x 8 SIMD x 2 SMT) compared to the sequencial program. Of course this is essentially impossible to achieve in real life applications :P
This comment was marked helpful 0 times.
Can someone explain hyperthreading or make links to later slides just for reference?
This comment was marked helpful 0 times.
@choutiy: There's a solid discussion about hyper-threading on slide 64. Hyper-threading is a particular implementation (by Intel) that combines ideas from simultaneous multi-threading and interleaved multi-threading.
This comment was marked helpful 0 times.

I have a question about the number of cores. Usually, we have 2, 4, 8 etc. which is 2^n. But here there are only 15 cores( 2^4 - 1), can anyone point out any special reason of doing this?
This comment was marked helpful 0 times.
@yingchal Good question! This bothered me in the past as well. To answer it, the GTX 480 does ship with 16 cores. One of its cores is disabled however. From what I can tell, the reason is poor yield - the number of chips that actually worked. Instead of tossing out a chip with one malfunctioning core, it made financial sense for NVDIA to simply ship the chip with that core disabled. They probably disabled one core on every chip to maintain consistency.
More about yield: Why NVDIA cut back the GTX480
This comment was marked helpful 2 times.
(Not really course-related but does answer the question) Another common reason: NVIDIA was planning a rather easy upgrade of their product line by enabling more cores. Both Intel and NVIDIA use this trick very often. For example, in NVIDIA's current product line, GTX660, GTX670 and GTX680 all use the same GK104 chip, but GTX680 has most cores enabled.
This comment was marked helpful 0 times.
Extra Fun Stuff: A while back, the Phenom II tri-core cpu from AMD became well known because you can easily unlock its 4th core (who produces only 3 cores anyways :P). In fact here is the DIY video. Since then manufacturers realized the power of hardware geeks and started using more tamper-proof mechanisms to disable those hidden cores. Some "apparent" techniques involve laser cutting the core out or even damaging them so they cannot be used.
If you could unlock open the extra cores of a GTX660, your name would most likely be heralded in the walls of reddit for weeks or even months :)
Happy hardware hacking!
This comment was marked helpful 3 times.
The same thing happened with ATI's HD 6950. It is identical to the HD 6970, with 128 of the 1536 unified shading units disabled. People figured out that you can just flash the 6970's BIOS onto a 6950 and turn the units back on (unless they were actually fried in the first place).
This comment was marked helpful 0 times.

For the architecture wonks:
realworldtech.com tends to have technical, but quite accessible, articles that describe the architecture of modern processors. This article on Intel's Sandy Bridge architecture is a good description of a modern CPU. It's probably best to start at the beginning, but Page 6 talks about the execution units.
This comment was marked helpful 0 times.

An interesting question to think of would be "What sorts of programs would run well using multiple cores but not in SIMD?" If we consider a code example with a switch statement where one of the cases dominates most of the work to be done by the code, one instance in SIMD will be busy whereas the other instances will be masked; resulting in performance loss. However, using threads in multi-core, we can distribute work so that most threads are busy on the work-dominating case and the other cases are executed instantly by threads given the nature of the switch statement.
This comment was marked helpful 1 times.

@rutwikparikh I think that both that question and the converse--what sorts of programs run well in SIMD but not with multiple cores--are really interesting ones. Pondering them both gives a lot of useful insight about HW architectures and parallelism.
On the "what runs well with SIMD but less well with multiple cores front": at first, one might think that multiple cores would always be preferable, since that's MIMD, and thus more general than SIMD (and handles cases like divergent control flow well, as you note). However, the nice thing about SIMD is that communication between program instances in a gang (ISPC) or threads in a warp (CUDA) is basically completely free. Communication between cores is much slower, especially if it has to go through a cache coherence protocol. Further, the fact that a gang or a warp is all running together means you don't need the same amount of synchronization you do across cores. So for communication-heavy computation, SIMD can be a better target.
Another issue is the overhead of starting parallel computation. With SIMD, you can be deep in some function operating on some data and opportunistically apply SIMD. There's essentially nil overhead for the transition (on a CPU at least). To launch work across CPU cores, there will unavoidably be higher overhead to enqueue work in a task system or the like.
Finally (related), there's the granularity at which it's worth going parallel. Launching tasks on other cores isn't worth it for a small amount of work, but again SIMD can be applied to many little problems pretty easily. (But on the other hand, there's always Amdahl's law, so a little SIMD in the middle of a big program doesn't necessarily buy you anything.)
Anyway, it's interesting stuff to think about.
This comment was marked helpful 1 times.



I am still a bit confused on the difference between memory latency and bandwidth. Going along with the laundry analogy from class, would it be correct to think of latency as the time we have to wait for the machine to finish after pressing the start button? Under this analogy, would bandwidth be the number of clothes that fit into the machine during one load? or the total number of clothes that can be washed in one hour?
I am confused about how latency and bandwidth are related. Maybe a pipe/water flow analogy would be helpful.
This comment was marked helpful 2 times.
The latency of an operation is the time to complete the operation. Some examples:
- The time to complete a load of laundry is one hour. The time between placing an order on Amazon and it arriving on your doorstep (with Amazon prime) is two days.
- If you turn on a faucet (and you assuming the pipe connected to the faucet starts with no water in it) it's the time for water entering the far end of the pipe to arrive in your sink.
- If I type
ping www.google.comI get a round trip time of 30 ms, so I can estimate the latency of communicating between my computer and Google's servers is approximately 15 ms. - If there's no traffic on the roads, it takes 5 minutes to drive to Giant Eagle from my house, regardless of how wide the roads are.
- If a processor requests data from memory it doesn't get the first bit back for 100's of clocks.
Bandwidth is a rate, typically stuff per unit time.
- A bigger washer would increase your bandwidth (more clothes per hour)
- A wider pipe would increase the flow into your sink (more gallons per second)
- A multi-lane road increases bandwidth (cars per second)
- A fast internet connection gives you higher bandwidth (100 gigabits per second)
- Once memory receives a request, it responds by sending eight bytes per clock cycle over the memory bus.
Note in the above examples: there two ways you can increase the rate at which things get done: make the channel wider (get a bigger pipe, add lanes, a wider memory bus) and push stuff through it faster (increase water pressure, increase the speed limit, increase bus clock rate).
This comment was marked helpful 3 times.

@kayvonf Just to clarify, does the value of memory latency include the computation time itself, or is it solely composed of the travel time of information to and from the CPU?
To place this into context, in your example "If there's no traffic on the roads, it takes 5 minutes to drive to Giant Eagle from my house, regardless of how wide the roads are.", is the time you spent shopping in Giant Eagle included? Or would the latency be only made up of the 10 minutes you spent driving on the road?
This comment was marked helpful 0 times.

@miko It sounds like it's only the time to get there, though I'm not entirely sure. See the example with pinging Google. If the round trip time is 30 ms to ping, then the latency is roughly 15 ms.
This comment was marked helpful 1 times.
@miko. Latency is the time to complete an operation. The answer to your question depends on the precise operation one is asking the latency of.
For example, L1 cache latency might mean the number of cycles between the processor requesting a value as part of an instruction and that data arriving in the CPU's instruction pipeline for use. Analogously, you could define memory as the time between issuing the load instruction and the data arriving at the instruction pipeline for use (assuming the data was not in cache and had to be retrieved from memory).
However, you could also define memory latency as time to first bit of response from memory, or time until the load request (e.g., a cache line transfer) is fulfilled in the cache. The latter would include the time to first bit + the time to send one 64-byte cache line over the bus.
effective_latency_of_transfer = time_to_first_bit + size_of_transfer / link_bandwidth
If a friend asked for a glass of milk, and I had none, I'd say the latency of me getting him a glass of milk would be the time to drive to Giant Eagle, purchase the milk, and drive home.
In the Google example above, I mentioned the communication latency as the operation, and I interpreted that as the time to send data to Google. That's why I took the ping time of 30 ms and divided by two. If you cared about round-trip latency, then you'd use 30 ms.
This comment was marked helpful 0 times.


Although compiler tries to rearrange instructions to avoid stalls, this rearrangement could get very complex for the compiler to analyze. However, in case of loops with independent iterations, this can be useful to hide stalls easily (loop unrolling). At times, this is a useful optimization done in the application code as well and might be much more useful in parallel computing.
This comment was marked helpful 0 times.
See these slides for a look at how compilers reason about data dependencies. They also briefly discuss how SIMD instructions are generated!
This comment was marked helpful 0 times.

One method of reducing the length of stalls is through the use of caching. Memory access times to the cache are much faster than accesses to main memory, so every cache hit will be a much shorter stall than an access to main memory. For instance, the Performance Analysis Guide for Intel Xeon 5500 processor approximates the cost of an L1 cache hit to be ~4 cycles, an L3 cache hit to be ~100-300 cycles, and local DRAM to be ~60 ns.
Source: Intel Perf Guide
This comment was marked helpful 0 times.
Doesn't a cycle take ~ 1 ns to perform? These numbers indicate that the time taken to access L3 cache and DRAM are about the same. Is something off, or am I doing something wrong here?
This comment was marked helpful 0 times.
@smcqueen, your L3 hit time seems a bit off.
An L3 hit in a modern Core i7 is about 30 cycles (see the diagram from lecture 10).
@aakashr: Period is 1/frequency so a clock cycle for a 1 GHz processor is 1 ns. As most modern CPUs operate in the 2-3 GHz range, the period of a cycle is less, about 300 to 500 picoseconds.
This comment was marked helpful 0 times.

What kind of logic does the CPU use to determine when it should or if it should try to prefetch the data. Does it do it all the time or some of the time? Is this compiler dependent or CPU dependent?
This comment was marked helpful 1 times.
Modern CPUs have hardware prefetchers that analyze the pattern of loads and stores a program makes in order to predict what addresses might be loaded in the future. Like branch prediction, or out-of-order instruction execution, this is done automatically and opaquely by the hardware without the knowledge of software. Earlier in this lecture I referred to these components of a processor by the technical term "stuff that makes a single instruction stream run faster".
However, most instruction sets (including IA64) do include prefetch instructions that can be emitted by a compiler to help deliver greater performance. These instructions are taken as "hints" by the processor. (It may choose to ignore them since remove a prefetch will not change program correctness.)
This comment was marked helpful 2 times.

For example, there are A and B threads running on the same core. When A thread is waiting some data into cache, B thread can still be running on the core.
--EDIT-- Actually, there is example in next few slides.
This comment was marked helpful 0 times.

Is caching a latency reducing technique?
This comment was marked helpful 0 times.

@chaominy caching is a latency reducing technique because the data is physically closer to the processor than it would be in memory or on disk. Threads are latency hiding, because the latency is still there for each individual thread, but the interleaving of multiple threads allows the processor to do work while waiting for the others to receive their data.
Multithreading is like household chores. If we start a load of laundry, we can leave this to go and start the dishwasher and even while running that cook dinner. Then while dinner is cooking, move our laundry to the dryer, clean out the dishwasher, and finally return to finish making dinner. Each of these tasks individually may take an hour, but all 3 could be accomplished within an hour or so by interleaving their start and end times together.
Caching reminds me of a refrigerator. We store items like milk in the fridge so that it takes less time to get them, as opposed to going to the store or the farm every time we want some milk.
This comment was marked helpful 4 times.
Very nice @Thedrick. Another common analogy is a desk. The papers related to what you are working on right now are kept on your desk for easy access. Papers you need less often are kept in your filing cabinet. Papers you need to keep around, but almost never need are kept in your basement.
A fundamental rule of thumb with storage hierarchies is that low-latency storage tends to be precious (and expensive), and the more a container can store typically the higher the latency is to access it.
This comment was marked helpful 1 times.
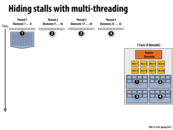
How does the latency of a stall on memory compare with the latency of a context switch? It was mentioned at some point that we can approximate a cache miss as ~100 clock cycles.
This comment was marked helpful 2 times.
Two things: a context switch
in the OS sense is very different than a context switch in this sense. The former changes the thread that is running on a CPU and the latter changes between thread contexts
in the same processor. There is a subtle distinction there.
Also, I just found this awesome infographic where you can see the differences between some latencies over the past several years.
edit: It is important to realize that this slide probably does not use thread
in the OS thread sense but rather in the hardware thread context
sense. The word thread
is somewhat overloaded and will mean different things at different points in this course - we will attempt to address some of the nuance but make sure you pay attention to this.
This comment was marked helpful 1 times.
In the context of interleaved hardware multi-threading, you can safely think of a processor being able to switch the active execution context (a.k.a. active thread) every cycle.
Keep in mind that from the perspective of the OS, a multi-threaded processor is simply capable of running N kernel threads. In most cases, the OS treats each hardware execution context as a virtual core and it remains largely oblivious to the fact that the threads running within these execution contexts are being time multiplexed on the same physical core.
The OS does, however, need to have some awareness about how kernel threads are mapped to processor execution contexts. Consider the processor above, which has four cores, and can interleave execution of four logical threads on each core. Now consider a program that spawns four pthreads. It would certainly be unwise for the OS to associate the four pthreads onto four execution contexts on the same physical core! Then one core would be busy running the threads (interleaving their execution on its resources) and the other three would sit idle!
Question: For those of you that have taken 15-410, can you list all that must happen for an OS to perform a content switch between two processes (or kernel threads)? It should quickly become clear that an OS process context switch involves quite a bit of work.
This comment was marked helpful 1 times.

OS process context switching involves the overhead of storing the context of the process you're switching from (A) and then restoring the context of the process you want to switch to (B).
- saving A's registers
- restoring B's saved registers
- re-scheduling A, setting B as running
- loading B's PCB
- switching to B's PDBR, which usually flushes the TLB (resulting in misses when translating virtual -> physical addresses as the cache warms up again)
The 410 book (Operating System Concepts) says that typical context switch speeds are a few milliseconds (I have the 7th ed, so it may be a bit outdated). "It varies from machine to machine, depending on the memory speed, the number of registers that must be copied, and the existence of special instructions (such as a single instruction to load or store all register). Context-switch times are highly dependent on hardware support. For instance, some processors (such as the Sun UltraSPARC) provide multiple sets of registers. A context switch here simply requires changing the pointer to the current register set."
This comment was marked helpful 0 times.
The state of the running process must be saved and the state of the next process must be restored:
- Storing all register values of the currently running process somewhere in kernel memory and then populating registers with the state of the next process. Included in the "state" of a process is all general purpose registers, the program counter, eflags register, data segment registers, etc.
- The page directory and tables must be swapped (which requires wiping the TLB).
Preceding this save-and-restore of state there is also work to be done in order to select the next runnable thread (scheduling) and some synchronization.
This comment was marked helpful 0 times.
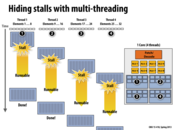
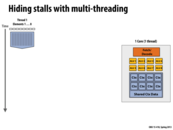
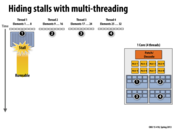
This diagram shows how multi-threading can be used to hide stalls. When thread 1 stalls while it waits for a read from memory, the processor can switch to thread 2 (etc...). In this example, by the time thread 4 is run and stalls, thread 1's request has returned and it is runnable. In this way the processor is always able to be doing useful work (except for maybe the overhead of context switching?) even though individual threads are stalled.
This comment was marked helpful 0 times.

Due to executing the other three threads until they blocked, thread 1 actually took longer in wall-clock time to finish executing than if we just waited on its stall since other threads were still executing when it became ready. This also led to a brief discussion on scheduling fairness in class since in reality you would need a better thread scheduling system than just executing all other threads until they stall before going back to the first since it could potentially be quite a long time before that happens, or never happen at all if another thread never stalled.
This comment was marked helpful 0 times.

Is there a way to estimate how long a thread will take before you run it? Or maybe even estimate how long each stall will take? To better optimize which order you run these threads in (for example if thread 1 took longer you might want to run it last rather than 1st). Or am I just missing something?
This comment was marked helpful 2 times.
@vvallabh: great question! So good in fact that good answers to that question might get you published in a computer architecture conference.
This comment was marked helpful 0 times.
Does the processor only switch between threads whenever it runs into a stall? Correct me if I'm wrong, but I originally thought it was possible to switch between threads even without something that causes execution to stall.
This comment was marked helpful 0 times.
@miko Before I try to answer this, I think it's important to note that we are talking about hardware threads here. If you look at the difference between slide 44 and slide 45, you'll notice that the execution context is replicated 4 times over in the latter. This implies you can store 4 independent execution contexts on that core (4 hardware threads).
With hardware threads, there is no "context switching". Context is stored directly on the core for each thread. Remember, when an OS thread is context switched out, its execution context is saved to memory and a different thread's context is restored - this takes a lot of cycles.
The answer to your question is on slide 52. Kayvon talks about it 62 minutes into lecture 2. It is basically down to implementation - you might run an instruction from a different execution context every cycle, or wait till a stall before you do.
I'm also going to add that, for OS threads, scheduling is handled by the OS' scheduler. The scheduler may choose to context switch from one thread to another at its discretion.
This comment was marked helpful 3 times.
Good answer, @mburman. The only thing I'll add is that when we talk about contexts in this class, we now need to be precise about what context we are referring to. There's a hardware execution context (register state, PC, etc.) defined by the hardware architecture and there's a software process context defined by the OS (the hardware context, plus info in the operating system PCB, virtual memory mappings, open file descriptors, etc.). The OS is responsible for the mapping of OS processes (or OS threads) to hardware contexts. The chip is responsible for choosing which of it's hardware contexts to execute instructions from. An OS context switch changes the mapping of OS threads to hardware contexts and should be considered an expensive operation.
This comment was marked helpful 0 times.

With throughput-oriented systems, we're assuming that there's a lot of parallel work that needs to be done. Therefore, we "sacrifice" individual thread throughput; our main concern is the aggregate system throughput.
This comment was marked helpful 0 times.
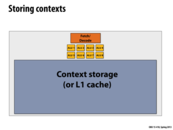

Contexts refer to states of threads. So if we want to be able to hide latency by running different threads, we need to be able to store the states of the different threads (register values, memory locations etc.) so we can load these and run them. This is where we use context storage.
This comment was marked helpful 0 times.
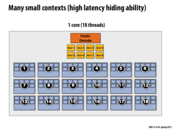
To understand why many small contexts lead to high latency hiding ability, note that when one of the threads stall on memory, other threads can run instead. More contexts implies more threads at the same time, which reduce the probability that all threads stalls and no one actually is able to run.
This comment was marked helpful 1 times.
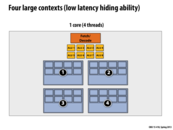

According to Wikipedia, the OS is made aware that some of the cores it sees are actually Hyper-threads running on the same physical core. It must arrange to run "appropriate" threads on the two cores (e.g. threads from different tasks) for the user to see the best performance improvement.
This comment was marked helpful 0 times.
A neat experiment: If you log into the machines in Gates 5201/5205 and type less /proc/cpuinfo you'll get a report about the processor. The Intel CPUs in those machines have four cores, but hyper-threading is disabled in their current configuration, so the cpuinfo report states there are four cores.
The Intel CPUs in the Gates 3000 machines have six cores, but hyper-threading is enabled. You'll find cpuinfo will report 12 logical cores although there are only 6 physical ones. In the terms I used in class, the CPU has 6 cores, but manages up to 12 independent hardware thread execution contents.
This comment was marked helpful 0 times.

What is the advantage of disabling hyperthreading?
This comment was marked helpful 0 times.
@nslobody I suppose without hyperthreading you would consume less power, specially if applications being ran are not heavily multithreaded, and would not take full advantage of this feature. After all, not every program was written with parallelism in mind :P Other than that, I can't think of a better reason. Maybe from an educational stand point, HT makes it harder to reason about the cores, as they operate slightly differently. Hence, if you were running certain benchmarks on them you would get "unexpected" results.
This comment was marked helpful 0 times.
http://bitsum.com/pl_when_hyperthreading_hurts.php
The idea of hyperthreading is fairly sound, but the implementation isn't perfect. I have heard of people who run servers disabling it. The cores have some shared hardware they can contest.
This comment was marked helpful 2 times.
@nslobody: The benefit of hardware multi-threading is to avoid stalls caused by long-latency operations (or in the case of Intel Hyper-threading: unused instruction issue slots) by executing with work from other threads. One disadvantage of concurrently executing multiple threads on a processor is the potential for interference. For example, imagine a CPU has a 1 MB cache, and each of the threads has a working set that fits in cache. Now consider the case where two threads run concurrently on a multi-threaded version of the CPU. If the aggregate working set of the two threads exceeds 1 MB, the threads will knock each other's data out of cache, and as a result suffer cache misses that they would not have suffered if only one was running on the processor alone. The result might be overall throughput that it worse than if only one thread was run at a time. If a thread's data access caches well, there are few memory stalls to hide and the benefits of hyper-threading are diminished.
Of course, there are also situations where concurrently running two threads on the same core can actually reduce cache misses. If threads share a significant portion of their working set, a load by one thread may bring the data into cache for a subsequent load by the other thread. When the other thread ultimately accesses this data, it will be in cache, avoiding "cold misses" that would exist if the thread was running alone on the core.
Another example of when Hyper-threading may not be desirable is if latency, rather than throughput, matters most to your workload. Hyper-threading results in the sharing of core resources between two threads (including ALUs, not just the cache as discussed above). The need to minimize time to complete the work in one thread, as opposed to maximizing work done per unit time by the core, might lead one to consider disabling hyper-threading.
That said, I do not know the rationale for why Hyper-threading is disabled on the GHC 5201/5205 machines.
This comment was marked helpful 1 times.
This is an excellent article covering some of the implementation details of how Intel hyper-threading works.
This comment was marked helpful 0 times.


Can someone correct me if I am wrong. 16 cores -> 16 simultaneous instruction stream; 4 thread per core because there are 4 context storing memory per core; therefore total of 4*16 concurrent instruction stream; 8 ALUs per core -> 64*8 = 512 independent data.
This comment was marked helpful 0 times.
That is correct for a theoretical maximum parallel throughput, but it is most likely unsustainable. Also notice the 4 context per core never run in parallel, since they share one execution unit, but nevertheless, as you mentioned, this processor can hold 512 independent data streams at once.
This comment was marked helpful 0 times.
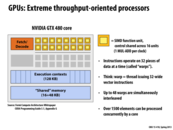

Who decides what a "thread" or "warp" is in a GPU? I don't think GPU threads are scheduled by the OS, so how does a GPU decide when one instruction stream constitutes a thread that is context-switchable? Is this information provided by a compiler?
This comment was marked helpful 0 times.
@kfc9001: Your question also applies to ISPC's abstractions of a "program instance" (akin to a CUDA thread) and "gang of program instances" (akin to an NVIDIA warp). Once you've had experience with Assignment 1, how do you think it's done?
NOTE: Please see Lecture 6, slide 43 for a description of how CUDA programs run on this processor.
This comment was marked helpful 0 times.
Where is the number 48 warps come from? What is the relationship between the execution contexts and 48 warps?
This comment was marked helpful 0 times.
@fangyihua: In the context of this lecture, a warp corresponds an execution context for an instruction stream. This GPU core can interleave up to 48 unique instruction streams. Each instruction stream operates on 32 pieces of data at a time (think 32-wide SIMD). See the next slide for further details.
This comment was marked helpful 0 times.


Please see Lecture 6, slide 43 for a description of how CUDA programs run on this processor.
This comment was marked helpful 0 times.

15 cores * 32 ALUs * 48 warps (or contexts) saved per core = 23,040.
This comment was marked helpful 0 times.
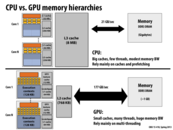
At first, I wasn't clear why the cache could be smaller for GPU, but I later understood that multi-threading hides the memory latency. And therefore, and as long as there is enough bandwidth to load the data while these threads are continuously working, then it effectively hides stalls.
While I was figuring this out, I also found another interesting article showing why GPU needs a smaller cache. This tells that because GPU is optimized for stream processing, it can easily identify independent blocks of the data, and therefore apply multi-threading and effectively predict bulk of data needed from the memory which increases cache efficiency (just like cachelab from 213).
This comment was marked helpful 1 times.
Are the numbers listed on this slide full duplex bandwidth? Because I was playing around with my cpu, which was rated at a max bandwidth of 25 GB/s, using memory intensive applications. But I only managed to achieve a maximum throughput of about ~10 GB/s. Which would make sense if it is 10 GB/s on both ways, which adds up to ~20 GB/s. Could anyone verify or disprove this?
This comment was marked helpful 3 times.

So it's 177 GB/sec from GPU to GPU memory - how fast is communication between the GPU and CPU/main memory? I'd assume it'd be much slower, but how much slower?
This comment was marked helpful 0 times.
Communication between the main system memory and GPU memory (for a discrete GPU card) is over the PCI Express (PCIe) bus.
To be precise, each lane of a PCIe 2.0 bus can sustain 500 MB/sec of bandwidth. Most motherboards have the discrete GPU connected to a 16-lane slot (PCIe x16), so light speed for communication between the two is 8GB/sec.
The first motherboards and GPUs supporting PCIe 3.0 appeared in 2012. PCIe 3 doubled the per-channel data rate, so a PCIe x16 connection can provide up to 16 GB/sec of bandwidth.
Question: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
This comment was marked helpful 0 times.

I might have a misunderstanding here, but if GPU to GPU memory communication can be way faster (177 GB/sec) than CPU to main memory communication (21 GB/sec), how come they can't make CPU/main memory communication as fast? The concept of DDR3 and GDDR5 should not be mixed together I guess?
This comment was marked helpful 0 times.
@kailuo: Of course they could, but architects have decided it is not the best use of resources.
Remember, if you are trying to build a chip, one of your goals is to try to maximize performance for a certain set of workloads given some constraints. Examples of constraints include chip cost, chip area (which has direct correlation to cost), or chip power consumption.
CPU memory systems provide lower bandwidth because architects have determined it is a better strategy (for workloads they are most interested in) to rely on caches to absorb a large number of memory requests. If the CPU's cache handles most data requests, then there is less demand on the memory system to fulfill those requests.
In this class, it's often best to think about ratios. A CPU has less compute capability than a GPU. So it's reasonable to expect it will request data at a lower rate than a GPU. A good design will strike the right balance between compute capability and the ability to feed compute units with data. If you add to much compute capability, the compute units will idle, waiting on data. If you build too fancy of a memory system, it will be underutilized because the processor won't request data at a high enough rate. The right balance depends on workloads. You should also take a look at the discussion about arithmetic intensity on slide 60.
This comment was marked helpful 0 times.

GPU can depend on multi-threading to hide memory latency, but, for a single processing unit on GPU, it still needs to stall for the latency. Is GPU suitable for realtime applications?
This comment was marked helpful 0 times.
@kayvonf: Even the fastest PCIe bus delivers bandwidth substantially lower than the 177 GB/sec of GPU to GPU memory shown on this slide (and also slower than the connection between the CPU and main system memory). What are possible implications of this?
Maybe one immediate result is that a programmer would want as little communication between GPU memory and main system memory as possible, since the PCIe bus limitation would place an inherent bottleneck between those two subsystems. But then this brings up the question of what types of programs can potentially saturate the PCIe bus? I understand that compression/encryption type applications can use a ton of CPU, while video processing/rendering can use a ton of GPU resources. What types of applications heavily rely on both resources (and thus might use up a ton of PCIe bandwidth)?
This comment was marked helpful 0 times.

The newer Intel/AMD chips now offer GPU/CPU processors on the same chip. Since the bandwidth to the processor is much less than that to the GPU, how is this a sustainable model? I could see that the processor could prefetch some amount of data for GPU operations, but even if you filled the entire cache of the processor with GPU data, a context switch could make these cache entries invalid. Is there some new technology that allows higher bandwidth from main memory to the processor?
This comment was marked helpful 0 times.
One reason that the lower sustainable BW is not a problem for the integrated CPU+GPUs is that their GPUs are less powerful than that discrete GPU with 177GB/s. They both have fewer ALUs and lower bandwidth, so in the end, the ratio of GPU ALUs to off-chip bandwidth is about the same on both systems. Thus, it should still have a reasonable balance between compute capability and feeding the compute units.
Regarding why CPUs don't have as much bandwidth: I'm not a memory system expert, but Kayvon's definitely right about different design points. One related factor is that the CPU's memory system tries to also be low latency when it goes to off-chip memory (i.e. if you've missed all the caches then hurry and get a result back from RAM), while a GPU's memory system in turn can be a little slower (since the GPU is already not latency-sensitive thanks to the massive threading). Thus, the GPU has opportunity to coalesce more memory transactions by waiting for more requests to come in, which can help.
My understanding is also that having those DIMM slots on your motherboard imposes costs in peak bandwidth as well (versus a GPU-like set up where the amount of RAM is fixed). GPUs can (and do, I believe) have direct connections between the pins coming out of the GPU and the DRAM pins, whereas if you have DIMM slots (not all of which may be filled, and where the amount of memory in each slot may vary), that flexibility reduces the maximum performance.
This comment was marked helpful 0 times.

@TeBoring Also, if the application cannot sustainably keep high occupancy on the graphics card, then the latency of the back-and-forth between the CPU and the GPU further diminishes the suitability of accelerating applications by computing on a GPU.
This comment was marked helpful 0 times.

Can GPUs actually do a 1-cycle multiply?
This comment was marked helpful 0 times.
The short answer to your question is yes. In fact, is common for GPUs to sustain a throughput of one multiply-add per clock on most of their execution units.
Modern Intel CPUs can also sustain a throughput of one multiply + one add per clock per lane on the AVX units. There's one AVS unit that can perform an 8-wide 32-bit floating-point multiply per clock, and one that can perform an add. Both instructions can be issued simultaneously.
Source: David Kantor's realworldtech.com article on Sandy Bridge, "Execution Units" Section.
The real answer to your question again brings up the question of latency vs. throughput. By breaking instruction execution into a number of stages and then pipelining those stages it is possible to maintain a throughput of one instruction per clock even if the latency of performing that instruction is more than a clock.
Pipelining itself is a form of exploiting instruction-level parallelism.
We'll address pipelining in a general sense later in the class, however Hennessey and Patterson (see suggested textbooks on the course info page) is the best place to get the full treatment of a basic pipelined processor. See Appendix in C in the 5th edition, or Appendix A in earlier editions.
This comment was marked helpful 0 times.
I guess I have another question, but probably more graphics-related: do most graphics algorithms really not touch memory that much? This algorithm above seemed fairly innocent, so I'm having a hard time believing graphics engines can really avoid touching the memory bus at all, to get anywhere close to 100% efficiency (or even 25%).
This comment was marked helpful 0 times.
The ratio of math operations to memory operations is sometimes called the arithmetic intensity of a program. 3D graphics applications tend to have extremely high arithmetic intensity compared to most other applications, thus it makes sense to build an architecture that has a high ratio of compute capability to memory bandwidth. But yes, one common challenge of writing programs for GPUs is to overcome the memory bandwidth bottleneck. (Keep in mind that GPU memory systems typically provide far more bandwidth than the main memory system attached to a CPU... they have to or the problem addressed here would be even more severe.)
There's a reason Intel doesn't fill their chips with execution units. They are targeting a different, and significantly broader class of workloads.
This comment was marked helpful 0 times.
Are there any studies on the average arithmetic intensity of common programs and benchmarks? This sounds like a very useful topic to consider how to spend the budget on a chip.
This comment was marked helpful 0 times.
In this case, how do we get the number 480 MULS per clock and 8.4TB/s ?
This comment was marked helpful 0 times.
@DanceWithDragon: see if you can answer your question using the information about this GPU given on slides 54-57.
This comment was marked helpful 0 times.
@Xiao: Check out this article about the Roofline model. For the record (and since I did my Ph.D. at Stanford), I'd like to add that to the best of my knowledge the term "arithmetic intensity" was coined at Stanford. The Berkeley folks errored in neglecting to make that citation here. Go Card! ;-)
This comment was marked helpful 0 times.

I'm just wondering how to get 8.4TB/s. I think each MUL requires 12 bytes per operation, there are 480 MUL per clock, and it can do 1.4G operations per sec. So data required per sec should be 12* 480* 1.4G=7.9T. Can someone correct me?
This comment was marked helpful 0 times.
I got the same answer @xiawend. I think we are doing it right, the 8.4 is probably an error.
This comment was marked helpful 0 times.
@xiaowend, @aakashr: You are correct, I believe I modified the clock rate slightly and didn't update the final answer. The correct math would be:
(12 bytes/op) * (480 ALUs) * (1.4 billion clocks/sec) / (1 GB = 1024 * 1024 * 1024 bytes) = 7.5 TB
This comment was marked helpful 0 times.



I think using a big cache can help reduce the number of accesses to the memory. So if bandwidth limit is a problem in both GPUs and CPUs, why use a relatively small cache in GPUs?
This comment was marked helpful 0 times.
Look at danielk2's comment on slide 59.
Bandwidth isn't generally a problem for GPUs. An NVDIA GTX 480 GPU has a maximum bandwidth of 177 GB/sec. Compare this to an Intel i7 processor which has a maximum memory bandwidth of about 25 GB/sec. That's a huge difference and is one reason GPUs do not need large caches.
I think another is that GPUs are designed to have a very high compute capability. As shown in this slide, they are typically required to do a lot more arithmetic operations per unit data accessed than a CPU. As a result, by design, it makes sense to fill a GPU core with arithmetic units instead of extra cache memory.
This comment was marked helpful 0 times.
Careful on this one: Remember it is about ratios, not about the absolute values.
A high-end GPU typically is connected to a memory system that can deliver significantly higher bandwidth than the memory system attached to a high-end CPU, but the GPU also has also has significantly more compute capability. The combination of this high compute capability coupled with smaller caches on a GPU often does mean that bandwidth limits come into play in GPU programming. We certainly saw it on the last slide.
This comment was marked helpful 0 times.
Ok, I agree that it's about ratios, I certainly did have GPU bandwidth issues on my final project last year.
Kayvon, I might be wrong here, but I think a more viable answer to @GG's comment is that it's not about bandwidth. It's about latency. GPUs have 1GB of on board DRAM. Caches are used to lower memory latency but on GPUs, with the DRAM on the chip, latency is low as is and the need for a large cache is substantially reduced.
This comment was marked helpful 0 times.
Actually, the opposite is true. The GPU memory is off-chip DRAM just like a CPU's main system memory. The GPU accesses it's own high-performance DRAM located on the graphics card. Since the entire GPU system is designed for throughput, other components, such as the memory controller tend to prioritize latency over throughput, so memory access times on a GPU tend to be higher than on CPUs. It's a bit of a feedback cycle: if you have a system that's all about throughput (and hiding latency), you start making design decisions for each component that don't prioritize latency... and as a result you have very high latencies... which means you need more latency hiding...
This comment was marked helpful 0 times.

I think the point that "on-board != on-chip" is worth making more clear. Correct me if I'm wrong, but GPU DRAM is faster only because it's a slightly fancier type of DRAM; it's nothing like on-chip CPU caches.
Also, it seems that large caches would be less useful on a GPU than a CPU, based on my guess that the typical GPU workload accesses the bulk of its data only once? (I guess not necessarily just once I guess; you might want to do a second or third pass over all the data, but large caches still wouldn't help there.)
This comment was marked helpful 1 times.


Question: This is a good comment opportunity: write a definition for one of these terms!
This comment was marked helpful 0 times.

Coherent Execution: This means that the same instruction sequence is applied to all elements that are operated on simultaneously. So this is relevant when describing parallel execution using SIMD processing. It is necessary to get good parallelization out of the SIMD processing resources because those execute the same instruction sequence for all the separate data. Coherent executtion is not necessary to get parallelization out of multiple cores as each core can do different things while still doing them in parallel. Coherent Execution is contrasted by Divergent Execution (like the conditional example from the slides).
This comment was marked helpful 0 times.
Arithmetic intensity - The arithmetic intensity of a program, algorithm, or function is the ratio of arithmetic operations to memory operations which it performs. For example, the arithmetic intensity of a piece of code which loads two numbers from memory, adds them, and stores the result is 1/3; one addition per two loads and a store. All other things being equal, programs with high arithmetic intensities are generally more performant on parallel architectures, since they are less likely to be memory-bound and spend less time stalled on memory latency.
This comment was marked helpful 1 times.

Hardware multi-threading - basically a term for the how hardware (can) facilitate the efficient execution of multi-threaded programs. The two types that we see in the above term list are:
Interleaved multithreading - in this case, the processor switches back and forth between executing instructions from several different threads. For example, cycle 1 is for an instruction from thread A, cycle 2 is for B, cycle 3 is for C, and cycle 4 is back to A again.
Simultaneous multi-threading - this really only applies to superscalar processors. Since a superscalar processor can handle multiple instructions in one cycle, we speed up the parallel program by having the processor simultaneously execute instructions from several different threads each clock cycle.
This comment was marked helpful 0 times.
I like @incanam's definition of coherent execution, but I want to point out that coherent execution is a property of a program. Instruction stream coherence is present when the same instruction can be used for each piece of data (I say "can" rather than "is"). When coherence is present, it is possible to execute the computation efficiently using SIMD approaches. It probably would have been more clear had I asked you to define "instruction stream coherence" rather than "coherent execution".
This comment was marked helpful 0 times.
Memory Latency - The amount of time for a memory from a processor to be serviced by the memory system. If a thread needs some information from main memory, it may take 10 cycles for that request to actually be fulfilled.
Memory Bandwidth - The rate at which the memory system can provide data to a processor. The higher the bandwidth, the more data you receive per time unit.
This comment was marked helpful 0 times.

Bandwidth-bound application - This term is applied to describe the fact that memory bandwidth can be a bottleneck for applications running on modern parallel chips. This is because arithmetic operations are extremely fast, so a lot of the time a thread must wait for a memory operation. Now, when a lot of different threads are running at the same time, we expect to see many, many memory operations happening at the same time. However, the chip can only process so many memory operations at a time. Thus, once there are too many memory operations happening concurrently, we can expect to see massive delays since the chip cannot handle it anymore. This is a major challenge for hardware designers to overcome.
This comment was marked helpful 0 times.
SMT (simultaneous multi-threading) is when the hardware is given more space for threads to run, meaning there are more registers for having multiple threads to run and more fetch/decode units to run multiple instructions in a single cycle. This is what Intel's Hyper-threading is. The processor still has the same number of physical cores, but each core has multiple execution units that can be used to run two separate threads per core.
Interleaved multi-threading has instructions from different threads being issued to the pipeline every clock cycle. Before, when talking about task switching to hide latency issues, the task switch itself is an interleaving of threads to be run in order to hide stalls. Operating systems will sometimes have simple round-robin execution of threads, where each clock cycle, a new thread is picked to run.
This comment was marked helpful 0 times.
Simultaneous multi-threading involves executing instructions from two different threads at once on different execution resources. Interleaved multi-threading involves interleaving execution of instructions from two threads on a single set of execution resources.
What does Intel's Hyper-threading technology really do? Hyper-threading involves a mixture of ideas from simultaneous multi-threading (SMT) and interleaved multi-threading. Two hardware threads are managed by a core and share the same set of execution resources. This design is in the spirit of interleaved multi-threading. However, instead of interleaving execution of the threads each clock, an Intel CPU tries to find a mixture of operations from the two threads to fill all possible execution units. For example one thread might be performing a load and an integer add, and the processor might also determine it's possible to schedule a floating-point multiply from the second thread.
This design is a natural evolution of a superscalar processor. Prior to hyper threading, Intel had several execution units in the chip that could be used in parallel when ILP was present in an instruction stream. As we observed in lecture 1, ILP does not always exist in programs, so in many cycles not all CPU core execution units could be used. Hyper Threading is technology that allows the core to maintain state for a second thread, and to fill unused execution capacity with instructions from this second thread when it would be helpful to increasing overall performance.
This really old article about hyper-threading explains the idea pretty well. So does this article from AnandTech.
This comment was marked helpful 0 times.
@tpassaro: Let's not confuse the interleaving of processes and threads onto a CPU by the OS with the fine-grained interleaving of hardware thread execution on a core. It takes thousands of clocks to perform a full OS-managed process context switch, making it untenable for this to be done at fine granularity.
This comment was marked helpful 0 times.

Intel's own hyperthreading whitepaper is nice enough that it's probably the best bet for anyone curious about details. They talk about the role that HT was intended to fill, and also have their own exam-friendly summary of hardware multithreading concepts from 2002.
Hyper-Threading Technology Architecture and Microarchitecture
This comment was marked helpful 0 times.
Examples for Question 1: Clock rate issue due to "Power Wall"; instruction Level Parallelism (Difficulties of finding independence);
Answer for Question 2:
Overhead communication; organization; (unbalanced) work distributions;
This comment was marked helpful 0 times.