Since cache is row-oriented, it is wise to break down matrix like this by rows instead of by columns. And it could limit the chance of false sharing shown in this example.
This comment was marked helpful 0 times.
kayvonf
@martin: Could you clarify what you mean by "row oriented"? A cache line contains consecutive memory addresses. (The cache has no knowledge of how data is mapped to the addresses.)
In the figure in the top right, let's assume the data is laid out in row-major order, so consecutive elements in a row correspond to consecutive memory addresses. In the figure, the processing of the 2D grid is partitioned down the middle of the matrix as shown. If two elements at the boundary of the work partitioning happen to map to the same cache line (which is the case in the figure due to the row-major layout), false sharing may occur between these processors.
It is false sharing, and not true sharing, if data need not actually be communicated between processors, but is communicated only because of the underlying granularity of communication of the machine.
This comment was marked helpful 0 times.
kayvonf
Question: Someone should try and write a simple piece of pthread code that shows off the effect of false sharing on the Gates machines. Report your timings and share the code with the class!
This comment was marked helpful 0 times.
nkindberg
I created the simple code below where I had 4 threads increment different integers stored consecutively in an array the maximum integer amount of times. I ran it on one of the Gates 3K machines and it ran in 52.241 seconds.
I then modified main as below to pad the array (according to proc/cpuinfo the cache line size is 64 bytes so I left 15 ints after the one each thread writes to). This new version ran in 15.827 seconds. So in just this simple example of incrementing integers false sharing led to code that ran over 3.30 times slower than similar code that didn't have false sharing.
int main(void)
{
pthread_t threads[NTHREADS];
int arr[NTHREADS * 16] = { 0 };
for(int i = 0; i < NTHREADS; ++i)
{
pthread_create(&threads;[i], NULL, increment, (void*) &arr;[i*16]);
}
pthread_exit(NULL);
}
This comment was marked helpful 4 times.
edwardzh
An example where nkindberg's code is applicable is when each thread is assigned its own independent counter. This kind of efficiency difference could easily be important when memory bandwidth is an issue.
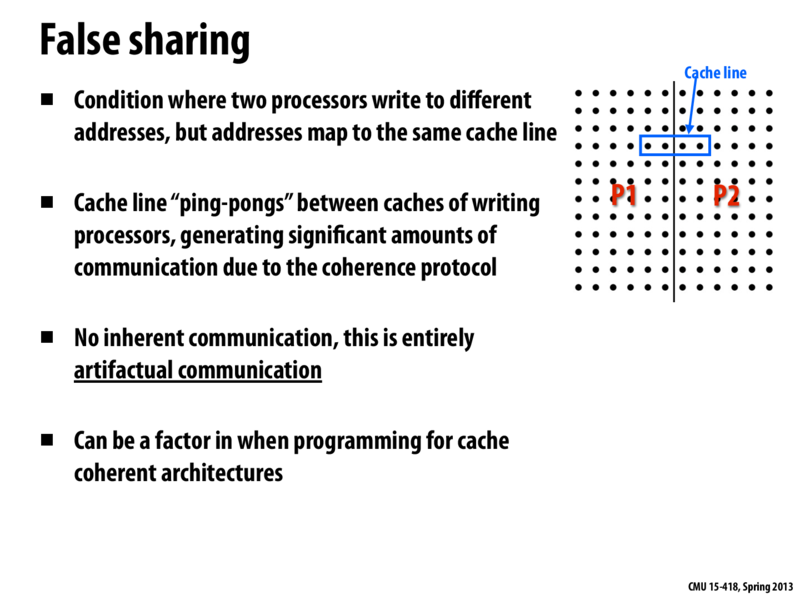
Since cache is row-oriented, it is wise to break down matrix like this by rows instead of by columns. And it could limit the chance of false sharing shown in this example.
This comment was marked helpful 0 times.
@martin: Could you clarify what you mean by "row oriented"? A cache line contains consecutive memory addresses. (The cache has no knowledge of how data is mapped to the addresses.)
In the figure in the top right, let's assume the data is laid out in row-major order, so consecutive elements in a row correspond to consecutive memory addresses. In the figure, the processing of the 2D grid is partitioned down the middle of the matrix as shown. If two elements at the boundary of the work partitioning happen to map to the same cache line (which is the case in the figure due to the row-major layout), false sharing may occur between these processors.
It is false sharing, and not true sharing, if data need not actually be communicated between processors, but is communicated only because of the underlying granularity of communication of the machine.
This comment was marked helpful 0 times.
Question: Someone should try and write a simple piece of pthread code that shows off the effect of false sharing on the Gates machines. Report your timings and share the code with the class!
This comment was marked helpful 0 times.
I created the simple code below where I had 4 threads increment different integers stored consecutively in an array the maximum integer amount of times. I ran it on one of the Gates 3K machines and it ran in 52.241 seconds.
I then modified main as below to pad the array (according to proc/cpuinfo the cache line size is 64 bytes so I left 15 ints after the one each thread writes to). This new version ran in 15.827 seconds. So in just this simple example of incrementing integers false sharing led to code that ran over 3.30 times slower than similar code that didn't have false sharing.
This comment was marked helpful 4 times.
An example where nkindberg's code is applicable is when each thread is assigned its own independent counter. This kind of efficiency difference could easily be important when memory bandwidth is an issue.
This comment was marked helpful 0 times.