It was mentioned that we would want a large cache with small lines to store the data based on the tree structure here. Could someone clarify why that would be ideal?
This comment was marked helpful 0 times.
jedavis
On some level this is true of most pointer-based data structures, that you want many cache lines, each about the size of one node. If you use a similarly-sized cache with large cache lines, you end up evicting a lot when you dereference a pointer to load a new node, and you get a fair bit of extraneous stuff. The computation has high spacial locality, but the data structure does not. The nodes are small, so if you have many small cache lines you can get a large portion of the tree into small cache lines and generate lots of hits.
There is likely something deeper here that I'm missing, though.
This comment was marked helpful 0 times.
GG
I want to add some points to @jedavis's answer.
A large cache with small lines means a large work set, which can store the entire processing path. In this way, we can make sure that all the data traversed can be stored in the cache without evicting.
Another benefit is that with small lines, we can reduce artificial communication. The tree nodes are typical small and can't fill a large cache line. So if the cache lines are large, we would waste our time transferring useless data. The ideal situation is that the size of a cache line is equal to the size of the tree node.
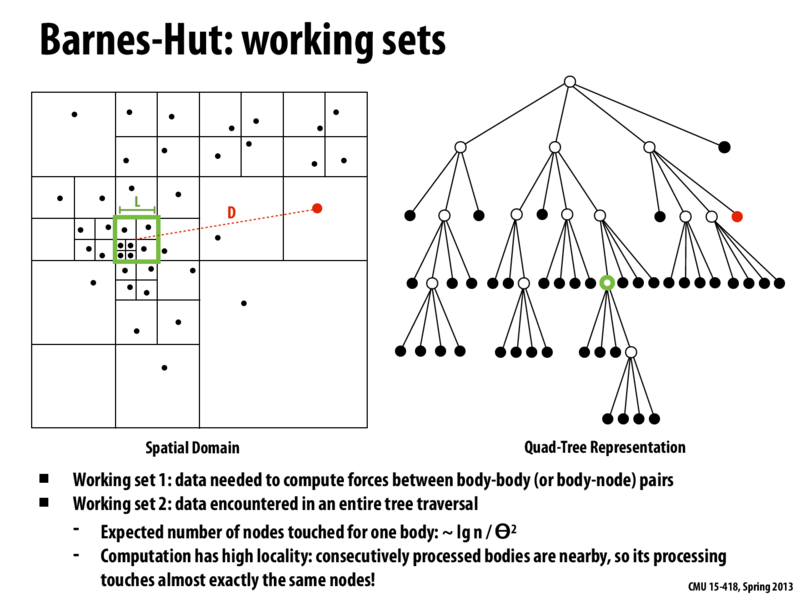
It was mentioned that we would want a large cache with small lines to store the data based on the tree structure here. Could someone clarify why that would be ideal?
This comment was marked helpful 0 times.
On some level this is true of most pointer-based data structures, that you want many cache lines, each about the size of one node. If you use a similarly-sized cache with large cache lines, you end up evicting a lot when you dereference a pointer to load a new node, and you get a fair bit of extraneous stuff. The computation has high spacial locality, but the data structure does not. The nodes are small, so if you have many small cache lines you can get a large portion of the tree into small cache lines and generate lots of hits.
There is likely something deeper here that I'm missing, though.
This comment was marked helpful 0 times.
I want to add some points to @jedavis's answer.
A large cache with small lines means a large work set, which can store the entire processing path. In this way, we can make sure that all the data traversed can be stored in the cache without evicting.
Another benefit is that with small lines, we can reduce artificial communication. The tree nodes are typical small and can't fill a large cache line. So if the cache lines are large, we would waste our time transferring useless data. The ideal situation is that the size of a cache line is equal to the size of the tree node.
This comment was marked helpful 0 times.