Parallels can be drawn here to MPI's asynchronous send. We hide the latency of the send by using Isend, placing data into a buffer, and continuing to read things while it is sending.
This comment was marked helpful 0 times.
mschervi
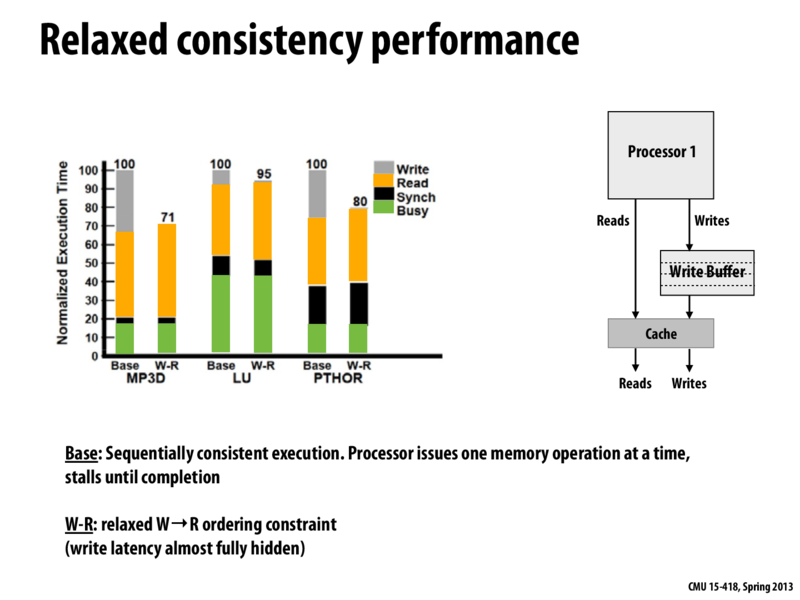
Question Why is the bar for "Read" longer in each of the W-R cases? Wouldn't both orderings have the same read latency?
This comment was marked helpful 0 times.
zwei
While I don't know for sure why the read time increases, I have two ideas. The first is that this graph looks hand-made, so it might just be accidental. Another idea is that a read from memory might require bumping something out of the cache, which in the W-R model requires actually righting that part to memory (as opposed to in Base where anything in the cache is also in main memory already).
I'm not confident on that though. Anyone else have thoughts?
This comment was marked helpful 0 times.
kayvonf
@mschervi: The graph is real data from a simulated system, so it's hard to say. I wouldn't lose too much sleep over it. One answer might be that if no reordering took place, the reads don't have to contend with outstanding rights for resources such as the chip interconnect, or cache controller logic, so they complete faster. In the reordered case, a read might get held up if the interconnect was busy handling a buffered write. This might cause the experimental framework to account for this time as "waiting for a read", whereas in the no-reordering setup the time would be attributed to the latency of a write.
This comment was marked helpful 1 times.
tliao
A question posed in class was "why is there no read buffer?" The answer is that the result of a read is used immediately, and thus program execution cannot continue until the read is satisfied. The write buffer is used so that the program can continue without having to wait for the write to propagate.
Parallels can be drawn here to MPI's asynchronous send. We hide the latency of the send by using Isend, placing data into a buffer, and continuing to read things while it is sending.
This comment was marked helpful 0 times.
Question Why is the bar for "Read" longer in each of the W-R cases? Wouldn't both orderings have the same read latency?
This comment was marked helpful 0 times.
While I don't know for sure why the read time increases, I have two ideas. The first is that this graph looks hand-made, so it might just be accidental. Another idea is that a read from memory might require bumping something out of the cache, which in the W-R model requires actually righting that part to memory (as opposed to in Base where anything in the cache is also in main memory already).
I'm not confident on that though. Anyone else have thoughts?
This comment was marked helpful 0 times.
@mschervi: The graph is real data from a simulated system, so it's hard to say. I wouldn't lose too much sleep over it. One answer might be that if no reordering took place, the reads don't have to contend with outstanding rights for resources such as the chip interconnect, or cache controller logic, so they complete faster. In the reordered case, a read might get held up if the interconnect was busy handling a buffered write. This might cause the experimental framework to account for this time as "waiting for a read", whereas in the no-reordering setup the time would be attributed to the latency of a write.
This comment was marked helpful 1 times.
A question posed in class was "why is there no read buffer?" The answer is that the result of a read is used immediately, and thus program execution cannot continue until the read is satisfied. The write buffer is used so that the program can continue without having to wait for the write to propagate.
This comment was marked helpful 0 times.