




Why does a read need to complete before a subsequent read? Why can't they be concurrent?
This comment was marked helpful 0 times.

From my understanding, a read doesn't NEED to complete before a subsequent read. It's just one of the types of orderings. Some systems may implement this, some may not. Sequentially consistent memory systems maintain this because its just sequential with no concurrency.
This comment was marked helpful 0 times.


Recall that this write may be slow: it has to broadcast it wants access to write, other cache lines may be dropped, there may be a flush to memory and a load of the line.
This comment was marked helpful 0 times.

When a processor is doing a write, it will use the bus to send out messages like busrdx, then how can a read happen concurrently when the bus is occupied?
This comment was marked helpful 0 times.

@chenc3 The bus between a CPU and main memory is many bits wide, so a single message like busrdx cannot "occupy" the entire bus. Are you thinking about the case in which a processor locks the bus? I'm not certain how this works, but there may be a way for one processor to prevent all other communication on the bus for the duration of some operation. But as I understand the scenario above, the read and write are occurring at different addresses, so there's really no need for this.
This comment was marked helpful 0 times.

In the first dependency ordering, B=1 doesn't really rely on A=1. Only actual dependency is that L can only be unlocked once both the writes are completed. Hence, these write operations can logically be executed concurrently and produce the same results as though they were executed sequentially. Same goes for the reads x=A and y=B. These are independent of each other.
This comment was marked helpful 2 times.

This is showing that the program order does not need to strictly followed for a program to produce correct results. For example, as long as we run A=1 before we run Unlock(L), the correctness can be preserved. We don't necessarily need to follow A=1, B=1, Unlock(L). Some program order can be relaxed here.
This comment was marked helpful 0 times.


In Total Store Ordering, a processor can move its own reads in front of its own writes. After a write to A, reads by other processors cannot return the value on A until the write to A is observed by all processors.
The difference between Processor Consistency and TSO is that PC allows any processor to see the change before the write is seen by all processors. For this reason, it is a more relaxed consistency model than TSO.
This comment was marked helpful 1 times.

In Total Store Ordering, reads by other processors cannot return the new value on A until the write is observed by all processors. Does this mean that, if the write is not yet seen, the processor will read the old A? Or will it hang? How would one actually implement a system in which all processors observe A at the same time?
This comment was marked helpful 0 times.

@AnnabelleBlue: If the write is not seen yet, the processor will read the old value of A. If you take a look at Program 4 in slide 8 for example, the reason TSO does not match sequential consistency is if processor P1 writes A=1 and then P2 writes B=1, but neither write is observed both processors can print 0 (the old value of A and B).
This comment was marked helpful 0 times.

Question: I understand that PC and TSO (and SC for that matter) are typically hardware-level memory reordering models. However, can these models also be implemented in software as well?
This comment was marked helpful 0 times.


We define "write is observed" by the point at which a read to that value will return the value just written. The difference between the second bullet of TSO and the bullet in PC is that PC doesn't assume anything about what other processors know about the newly written value; it can be the old value or the new value.
TSO does not maintain W$\rightarrow$R on the same processor, but maintains it across other processors. PC does not maintain W$\rightarrow$R across any processor.
This comment was marked helpful 0 times.

Here is a recent blog post where the author generated a short program the behaves differently under TSO than under sequential consistency.
This comment was marked helpful 0 times.
In other words, TSO is 'stricter'. If a processor reads a value from a given location in memroy, it can assume other processors will read the same value from that location, but PC does not have this guarantee.
This comment was marked helpful 0 times.

If a system uses PC, isn't correctness not guaranteed if processors have the ability to read a value that is not updated?
This comment was marked helpful 0 times.

Guaranteeing correctness is now placed on the programmer.
This comment was marked helpful 0 times.

Is there a reason why processor consistency is around? I could see it useful where a system knows that no two threads directly share the same data, and thus would never need to wait for anyone to complete any writes. This would take care of latency associated with assuring that a processor is done writing a value to memory.
This comment was marked helpful 0 times.
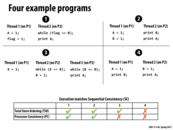
Note that it is assumed that all flags are initialized to 0.
The reason why program 3 may be different for PC is because Thread1 may set A to 1, letting Thread2 enter the loop and set B to 1, but Thread3 might have only seen the changes in Thread2 since it is not guaranteed like in TSO that the value of A is the same across all processors. Thus, Thread3 may see B as 1 with A still 0, and end up printing 0 instead. This is a clear example of Thread3 being allowed to read A without knowing the value of A in Thread2 as set by Thread1. In any SC execution, A would have to be set to 1 across all processors, so 1 must be printed.
The reason why program 4 may be different for TSO and PC is because Thread1 may move the read of B before setting A to 1, printing 0, and Thread2 might move the read of A before setting B to 1, also printing 0. This is a clear example of TSO (in Thread1) of reading B before the write to A is observed by Thread2. In any SC execution, in order to reach either print statement, the other variable must be set to 1 across all processors, so it is impossible to print 0 for both.
This comment was marked helpful 3 times.

For reference:
Program 1: will always print 1 because there is no way for thread 2 to observe a 1 value for flag (thus coming out of its loop) without first observing the 1 value for A.
Program 2: valid outputs are 00, 11, 01. 10 can't happen because there's no way for thread 2 to observe the write to B without first observing the write to A.
@Xelblade explained 3 and 4.
This comment was marked helpful 1 times.
To add to @nslobody: The reason behind the non-occurrences is because both PC and TSO still respect the W->W constraint as given in the previous slide
To clarify @Xelblade, there is no need for both threads to move their reads before their prints, so long as one thread moves its read before its print, it is possible for an execution path to produce prints of zeroes.
This comment was marked helpful 1 times.

Even though in Program 2, there might be several outputs, but each output may match its Sequential Consistency.
However in Program 4, any output matches its Sequential Consistency can not both 0. However in both TSO and PC, two threads may print the output before receiving the write from each other. Therefore in Program 4 both schemes do not match the Sequential Consistency.
This comment was marked helpful 0 times.

The key idea to remember is that reads propagate up before writes in both TSO and PC, and as a result, it is possible that a given execution of both threads results in both A and B to be printed as 0's. In SC, one of them must be 1 and as a result, we will differ from both TSO and PC.
This comment was marked helpful 0 times.

Here we relax the constraint that writes must complete before subsequent writes.
Previously with only W->R relaxed, we said the program could only print 1. The write to A had to complete before the write to flag, so if P2 observed flag being changed and exited the while loop it must have observed A being written also since that was written before flag. In this case we matched sequential consistency.
With W->W relaxed however, the write to flag might be observed by P2 before it observes the write to A in which case it could exit the while loop and print 0. This no longer matches sequential consistency since in a sequential memory system the write to A must always complete before the write to flag.
This comment was marked helpful 0 times.

With a release consistency model, all re-orderings are allowed so the processor usually supports synchronization operations that are available to a programmer such as a fence operation to make some guarantees about what memory operations have been observed. A fence operation blocks until all memory accesses before it complete and prevents any additional memory accesses from occurring until the fence has completed. Once the fence completes you know that all writes that occurred prior to it are now visible to all processors.
One example programming model that has a fence operation is CUDA. CUDA has a __threadfence() operation that blocks the calling thread until all the shared and global memory accesses it made before the fence are visible to all other threads since writes to those locations are not guaranteed to be observed with the exception of atomic operations like atomicAdd. __syncthreads() will make sure all threads in a block have observed memory accesses by the threads in the block.
This comment was marked helpful 0 times.

Relaxed memory consistency is an example of "optimize for common cases".
In most cases, threads don't share variables or they just read the shared variables. So there is no need to maintain a strict ordering in such cases. And this model can achieve better performance due to reordering and hiding latency. If threads do need synchronization, the programs can use FENCE or Lock to guarantee ordering. Although it may increase the complexity of programs or even slow the system down in such cases, the overall performance can be improved.
This comment was marked helpful 2 times.

@GG, as you mentioned this model is suitable for the workload with not many shared variables. How can this model be optimized for those "many shared variable" workload? Is a hybrid model possible?
This comment was marked helpful 0 times.

Another way to say what GG meant was that most of the time sequentially consistent semantics are not necessary since most of a program is not operating on shared variables. Therefore, it's arguably good design to allow some reordering for performance. The user always has the option of inserting fences when it matters for correctness. Of course, the burden is now on the programmer to realize when those situations exist.
This comment was marked helpful 0 times.
@kayvonf thanks. I see... so in weak consistency model, "smart" programmers are responsible for managing FENSE to ensure the correctness and leverage the performance advantage of reordering at the same time.
This comment was marked helpful 0 times.

Question: What kind of performance advantage can we get if we are able to reorder RR and WW? It's not clear that we can hide much latency here.
This comment was marked helpful 0 times.
@yongzuaw We stand to hide the same amount of latency by relaxing the RR constraint as we do the RW constraint- that is, the latency of a read. In both cases, by relaxing the constraint, we allow the next operation to begin before one read has finished. The same goes for relaxing the WR and WW constraints. In both cases, we allow the following operation to start earlier by the same amount of time- the time it takes to perform a write.
This comment was marked helpful 0 times.


Since the links on the slide are not "clickable", here they are:
http://bartoszmilewski.com/2008/11/05/who-ordered-memory-fences-on-an-x86/
This comment was marked helpful 1 times.

Here SC means Sequential Consistency.
This comment was marked helpful 1 times.
I think conflict here means that suppose two processors T1 and T2 both write to a memory space A at the same time, then some processors will first observe value from T1 then from T2, while some other processors will first observe value from T2 and then from T1.
This comment was marked helpful 0 times.
@monster This notion of conflict is more broad than that. It also includes the pair of one read and one write to the same address.
This comment was marked helpful 0 times.

Parallels can be drawn here to MPI's asynchronous send. We hide the latency of the send by using Isend, placing data into a buffer, and continuing to read things while it is sending.
This comment was marked helpful 0 times.

Question Why is the bar for "Read" longer in each of the W-R cases? Wouldn't both orderings have the same read latency?
This comment was marked helpful 0 times.
While I don't know for sure why the read time increases, I have two ideas. The first is that this graph looks hand-made, so it might just be accidental. Another idea is that a read from memory might require bumping something out of the cache, which in the W-R model requires actually righting that part to memory (as opposed to in Base where anything in the cache is also in main memory already).
I'm not confident on that though. Anyone else have thoughts?
This comment was marked helpful 0 times.
@mschervi: The graph is real data from a simulated system, so it's hard to say. I wouldn't lose too much sleep over it. One answer might be that if no reordering took place, the reads don't have to contend with outstanding rights for resources such as the chip interconnect, or cache controller logic, so they complete faster. In the reordered case, a read might get held up if the interconnect was busy handling a buffered write. This might cause the experimental framework to account for this time as "waiting for a read", whereas in the no-reordering setup the time would be attributed to the latency of a write.
This comment was marked helpful 1 times.

A question posed in class was "why is there no read buffer?" The answer is that the result of a read is used immediately, and thus program execution cannot continue until the read is satisfied. The write buffer is used so that the program can continue without having to wait for the write to propagate.
This comment was marked helpful 0 times.

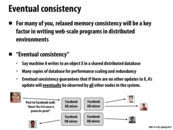

Eventual consistency, while not a really serious issue with the average Facebook post, can be an issue in industries such as the finance industry. An interesting paper on what eventual really means, in a probabilistic sense, can be found here.
This comment was marked helpful 0 times.




In case it's hard to read, green is transistors (DDD), dark blue is clock speed (MHz), light blue is power (Watts), and purple is performance/clock (ILP) rate. ILP is instruction level parallelism, and I believe DDD is Double Diffused Drain...?
This comment was marked helpful 0 times.

The answer to the question in this slide is:
parallelism performance is more focused on latency than throughput. Although the dumb way of asking a 10-core processor to do the same at once will increase the throughput by a factor of 10 but not affect the latency, the ultimate goal of parallelism is to shorten the amount of time to finish a certain job, through better algorithms, work distribution and communications.
This comment was marked helpful 0 times.
@choutiy: I'm not sure if I agree entirely. The four-core CPU in my laptop allows me to watch a video on YouTube, run MS Word, download from Netflix, and play a song in iTunes easily in parallel, but it doesn't reduce the time I get any of those things done in comparison to if I was running any one of those programs on its own on a single core processor.
While its true that a single task with ample sub-task parallelism may complete faster on a parallel machine, parallel execution of many tasks at once can actually slow down the time to task any one of those tasks.
This comment was marked helpful 0 times.




Because the machine has 4 cores, the first obvious attempt was to make 4 tasks and launch them. Due to work load imbalance though (specifically, tasks near the middle of the image were larger), it is actually more advantageous to create far more than 4 tasks to be dynamically assigned to the 4 cores, or statically assign tasks with more balanced loads per core, such as outermost to innermost chunks, or divide the image differently such as making the tasks near the middle of the image cover fewer rows.
This comment was marked helpful 0 times.


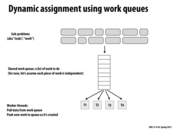

Work queues can suffer from poor performance under certain circumstances. For example, they do not scale very well due to contention, as each request from the queue must be handled atomically. Also, if the tasks are very small (e.g. arithmetic operations), the overhead from constantly querying the work queue could exceed the performance gains from doing the dynamic assignment.
This comment was marked helpful 0 times.





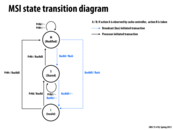
Because coherence applies to cache lines, variables that are within the same cache line will necessarily demonstrate sequentially consistent read/write behavior between each other.
This comment was marked helpful 0 times.
@zwei: CAREFUL! Coherence and consistency are COMPLETELY different concepts. Also, most systems I can think of do not provide sequentially consistent memory semantics.
This comment was marked helpful 0 times.
To clarify the difference between memory coherence and memory consistence, an example is discussed here.
The code on Processor 1:
The code on Processor 2:
The program on P2 cannot continue to execute until flag has been set to 1 by P1 and propagated to P2.
If only memory coherence is realized, the printed value of A can be either 0 or 1. Because memory coherence doesn't enforce the latest update of different locations, the value of A cannot be determined exactly.
But when memory consistency is guaranteed, the printed value is definitely 1. Because A=1 is executed over before flag is set to 1, the latest value of A should be loaded by P2.
This comment was marked helpful 4 times.
Question: If sequential consistency is provided, is memory coherence guaranteed?
This comment was marked helpful 0 times.
Question: Compared with slide 11 of the coherence lecture, can I say coherence is a sequential consistency of operations on a single value instead of operations on all values?
This comment was marked helpful 0 times.
@TeBoring: in my understanding, the concept of consistency and coherence are not dependent on each other. Consistency addresses WHEN does other processors see a memory update, while coherence shows HOW memory updates are propagated. Here is a more detailed slide.
This comment was marked helpful 0 times.
memory consistency is prerequisite of lock-free data structure. Re-ordering of load and store can happen. Memory fences will be required to ensure correct ordering.
This comment was marked helpful 0 times.