Because in most of time the communication is only exists between the neighbors, therefore the number of sharers of a line at the time of a write is usually small.
This comment was marked helpful 0 times.
yingchal
This slide is really important to connect between the benefits directory cache gives us and the potential optimization we need to do with it. From the graphs, we can observe that only a few processors share the line, which means the communication cost by directory-based cache coherence is largely reduced. However, it causes memory storage overhead at the same time, which introduces some optimizations in memory such as limited pointer scheme in the next few slides.
This comment was marked helpful 0 times.
kayvonf
Question: For this system of 64 processors, can you describe an access pattern that would produce a histogram where almost all the writes trigger 63 invalidations?
This comment was marked helpful 0 times.
akashr
Would this be the case where all of the processors are writing to the same cache line. The cache line would be a resident in all of the 64 processors. So when we are writing in one processor, we have to invalidate the cache line in all of the other 63 processors.
This comment was marked helpful 0 times.
kayvonf
@akaskr: The answer is a bit more subtle. If all the processors were frequently writing to the same cache line, think about what would happen. Each write would cause all other processors to invalidate. Thus, it's really likely that for each write, only a very small number of other processors (e.g., the last one to write) have the line cached.
This comment was marked helpful 0 times.
akashr
I see where my thinking was wrong. So lets say all 64 processors were reading the same line. That means the cache line is a resident of all the 64 processors. Now lets say that one of these processors were to write to a piece of data that is in the same cache line after all 64 processors read the data . Then we would have to send 63 invalidation requests as every other processor would need to drop the data.
This comment was marked helpful 0 times.
Mayank
Extending @akashr's example, one example could be from assignment 3. "Best Solution" is a piece of data which is read by all the processors all the time. It is written by the processor which finds the best solution, invalidating all other cache lines. Another example could be some iterative algorithm which updates a global parameter in each iteration.
This comment was marked helpful 2 times.
chaominy
Is high-contention mutex also an example for this?
This comment was marked helpful 0 times.
kayvonf
@chaominy: Not quite. A high contention lock is much like the situation @akaskr first described. If many processors are contending for a line, it is likely that between two writes most processors haven't had the chance to read, so the line is only going to be present in a small number of caches.
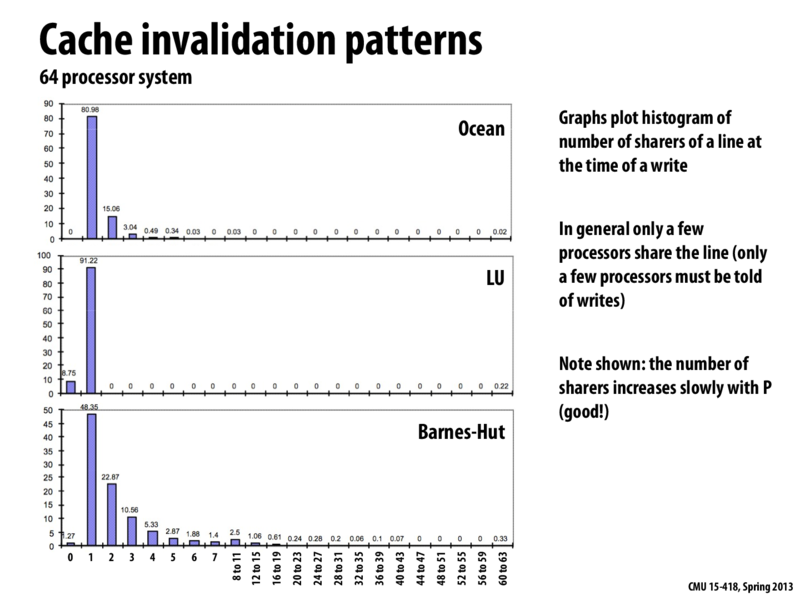
Because in most of time the communication is only exists between the neighbors, therefore the number of sharers of a line at the time of a write is usually small.
This comment was marked helpful 0 times.
This slide is really important to connect between the benefits directory cache gives us and the potential optimization we need to do with it. From the graphs, we can observe that only a few processors share the line, which means the communication cost by directory-based cache coherence is largely reduced. However, it causes memory storage overhead at the same time, which introduces some optimizations in memory such as limited pointer scheme in the next few slides.
This comment was marked helpful 0 times.
Question: For this system of 64 processors, can you describe an access pattern that would produce a histogram where almost all the writes trigger 63 invalidations?
This comment was marked helpful 0 times.
Would this be the case where all of the processors are writing to the same cache line. The cache line would be a resident in all of the 64 processors. So when we are writing in one processor, we have to invalidate the cache line in all of the other 63 processors.
This comment was marked helpful 0 times.
@akaskr: The answer is a bit more subtle. If all the processors were frequently writing to the same cache line, think about what would happen. Each write would cause all other processors to invalidate. Thus, it's really likely that for each write, only a very small number of other processors (e.g., the last one to write) have the line cached.
This comment was marked helpful 0 times.
I see where my thinking was wrong. So lets say all 64 processors were reading the same line. That means the cache line is a resident of all the 64 processors. Now lets say that one of these processors were to write to a piece of data that is in the same cache line after all 64 processors read the data . Then we would have to send 63 invalidation requests as every other processor would need to drop the data.
This comment was marked helpful 0 times.
Extending @akashr's example, one example could be from assignment 3. "Best Solution" is a piece of data which is read by all the processors all the time. It is written by the processor which finds the best solution, invalidating all other cache lines. Another example could be some iterative algorithm which updates a global parameter in each iteration.
This comment was marked helpful 2 times.
Is high-contention mutex also an example for this?
This comment was marked helpful 0 times.
@chaominy: Not quite. A high contention lock is much like the situation @akaskr first described. If many processors are contending for a line, it is likely that between two writes most processors haven't had the chance to read, so the line is only going to be present in a small number of caches.
This comment was marked helpful 0 times.