

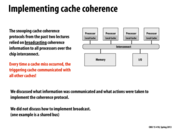


Here, we discuss the problem of scaling coherence to large systems, potentially with hundreds of cores, such as Blacklight. Blacklight is a cache-coherent system, and we might expect it to have the policy of notifying all processors of every cache miss from a read or write. Large-scale systems like these will attempt to utilize NUMA to reduce latency, but its benefits are defeated when every memory access requires a broadcast to all other processors. Snooping-based cache coherence will suffer from contention for the shared interconnect.
This comment was marked helpful 0 times.
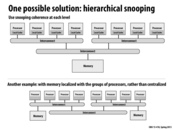

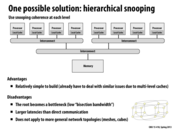
To summarize, hierarchical snooping suffers from high latency because the snooping and lookup must be done at multiple levels, and high bandwidth at the interconnect at the root, especially as the number of processors increases.
In the second example, memory scales well and local traffic and latency is reduced, but there is a longer latency to memory which is not local (i.e. in a different cluster), compared to just checking the root interconnect.
This comment was marked helpful 0 times.


The idea of switching from broadcast to a directory based essentially is changing from a decentralized system to a centralized system, where all information of different cache are kept in one place. In this way, it avoids the extra communication of broadcast, but create the directory as the bottleneck of the system.
This comment was marked helpful 0 times.
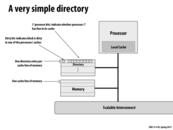

This is a very simple representation of a directory and it's use case. Obviously storing that much extra data has some overhead to it, and there are some solutions to work around that. Directories remove the requirement for processors to broadcast their reads and writes, but that can actually be detrimental if there are a lot of processors holding a given cache line because a processor will need to look up all other processors to send a message to, and then deliver them (hopefully in parallel), which could have a higher overhead than a broadcast.
This comment was marked helpful 0 times.
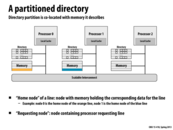

Main memory is partitioned between the processors. In this example, Processor 1 is the home node of the blue line. The home node can be computed using a simple hash of the memory address.
This comment was marked helpful 0 times.


In this example, normally with snooping, if Processor 0 wants to read a line then it will have to 'shout' to all of the processors. In directory-based though, it will send a message to the home node of the address (where home node is defined by a hash on the address). And then here, since no other cache has the entry, it will just respond with the contents from memory and not have to bother any of the other processors.
This comment was marked helpful 0 times.
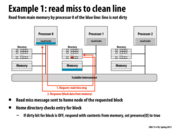




Question:
I think the home node should flush the new value to memory before clearing the dirty bit. Otherwise, if someone else read the line again, the home node will serve the request directly with stale value. Is this situation possible?
This comment was marked helpful 0 times.

@lazyplus Updating of memory happens in step 5. In step 5, the owner sends the data to the home node which updates its memory with the new data and then turns off the dirty bit. If you look at the arrow for step 5 you can see it points to the home node's memory, not to its cache.
This comment was marked helpful 1 times.





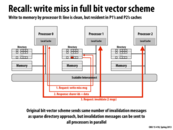
High-level Summary: Processor 0 wants to write to data stored in Processor 1's memory but the data was originally cached by Processors 1 and 2. Thus, Processor 0 gets the sharer ids from Processor 1 (to be more precise, Processor 0 requests a write to Processor 1's data and the response by Processor 1 is the sharer ids of the Processors with the data stored in their local caches) and sends invalidation messages to Processors 1 and 2. When Processor 0 then hears the responses from Processors 1 and 2 (following the invalidation), it means that the write can be safely performed (i.e. cache coherence protocols were followed).
This comment was marked helpful 0 times.


This slide shows how directory based cache systems can be no worse than snooping based systems (in terms of communication cost). In the worst case (a write where all caches share data) we have a a broadcast akin to a snooping based system. However, more often than not, the communication will be a lot less, as in most programs, it will be rare for all caches to hold onto data. (Next slide shows actual data, and the slide after that shows reason why).
This comment was marked helpful 0 times.


Because in most of time the communication is only exists between the neighbors, therefore the number of sharers of a line at the time of a write is usually small.
This comment was marked helpful 0 times.

This slide is really important to connect between the benefits directory cache gives us and the potential optimization we need to do with it. From the graphs, we can observe that only a few processors share the line, which means the communication cost by directory-based cache coherence is largely reduced. However, it causes memory storage overhead at the same time, which introduces some optimizations in memory such as limited pointer scheme in the next few slides.
This comment was marked helpful 0 times.

Question: For this system of 64 processors, can you describe an access pattern that would produce a histogram where almost all the writes trigger 63 invalidations?
This comment was marked helpful 0 times.

Would this be the case where all of the processors are writing to the same cache line. The cache line would be a resident in all of the 64 processors. So when we are writing in one processor, we have to invalidate the cache line in all of the other 63 processors.
This comment was marked helpful 0 times.
@akaskr: The answer is a bit more subtle. If all the processors were frequently writing to the same cache line, think about what would happen. Each write would cause all other processors to invalidate. Thus, it's really likely that for each write, only a very small number of other processors (e.g., the last one to write) have the line cached.
This comment was marked helpful 0 times.
I see where my thinking was wrong. So lets say all 64 processors were reading the same line. That means the cache line is a resident of all the 64 processors. Now lets say that one of these processors were to write to a piece of data that is in the same cache line after all 64 processors read the data . Then we would have to send 63 invalidation requests as every other processor would need to drop the data.
This comment was marked helpful 0 times.

Extending @akashr's example, one example could be from assignment 3. "Best Solution" is a piece of data which is read by all the processors all the time. It is written by the processor which finds the best solution, invalidating all other cache lines. Another example could be some iterative algorithm which updates a global parameter in each iteration.
This comment was marked helpful 2 times.

Is high-contention mutex also an example for this?
This comment was marked helpful 0 times.
@chaominy: Not quite. A high contention lock is much like the situation @akaskr first described. If many processors are contending for a line, it is likely that between two writes most processors haven't had the chance to read, so the line is only going to be present in a small number of caches.
This comment was marked helpful 0 times.


Question
Why do high-contention lock present a challenge? I think it has a similar access pattern as the frequently read/written objects. Have I missed some points?
This comment was marked helpful 0 times.

I think it might because the number of processors waiting for a lock might build up while sharer count of read/written objects might not.
This comment was marked helpful 0 times.


Overhead calculation:
$$ 100\%*\frac{P\text{ bits}}{(64\text{ bytes/line})(8\text{ bits/byte})} $$
This comment was marked helpful 1 times.

Just a dimensional analysis point but, it should be P bits/line (since every line has its own vector). Otherwise, you have units of lines x percent.
This comment was marked helpful 1 times.
As we have seen from the exam 1, the full bit vector overhead is acceptable sometimes. For example, on a quad-core processor, a full bit vector needs only 4 additional bits for each cache-line, the overhead is less than 1%. Under this situation, we should put effort on other performance issues instead of reducing the overhead of directory.
This comment was marked helpful 0 times.

First, a cache block is just a cache line without the associated tag information and valid bits. Hence, if we increase the block size, we will potentially get more cache misses due to false sharing, as displayed in this slide
This comment was marked helpful 0 times.

Using a limited pointer scheme, in this example, we could store ~100 pointers per line in the same amount of space needed by the full bit vector scheme. More practically, we would store less (maybe around 25?). This would drastically reduce the memory cost of a directory based cache coherency system. Yes, it is possible that sometimes data might be stored on more nodes than we have allocated memory for (so more than 25 in my example), but we can deal with this case. The key is, that this case should be very very unlikely, so even if this case performance heavy, the cost should not be significant.
This comment was marked helpful 0 times.




Question:
Although the cache is relatively small in one node, there is a chance that nodes will access to the memory in other nodes.
Assume there are 1024 nodes each with 1MB cache, it's possible (of course very rare) that all nodes access to part of node 0's memory. Thus, the total cache size could be as large as 1024 * 1MB = 1GB. How should we handle this potential large cache with sparse directory?
This comment was marked helpful 0 times.
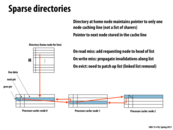

Question Based on the previous slide, I thought that the goal of a sparse directory would be to reduce the number of entries in a directory, since most lines would not be resident in any cache at a given time. However, on this slide, it looks like the directory still has M entries, and that this scheme is a way to reduce the overhead of storing which processors have a line in their cache at a given time, the same problem we addressed earlier.
This comment was marked helpful 0 times.
Good question. The system still needs a way to find the "head of the list" for each line. One way to do this in O(1) time is have a single head pointer per line in memory (requiring just a few bits, rather than a full bit vector, or a limited-pointer list). This is what is illustrated here for simplicity, although technical my illustration doesn't reduce M as claimed. However, given that cached lines are sparse, a more practical alternative would be to simply maintain a small lookup table storing the head of the list for cached lines. Perhaps each home node would maintain this lookup table for the lines it managed.
Notice that this discussion assumes there's a distributed set of caches. If there was a single, unified last-level cache, and inclusion is maintained, such as is the case for the L3 cache in a modern Intel Core i7 processor (as shown on slide 41), then finding the "head of the list" for a line is easy. Just find the line in the L3 cache, and the line contains extra information about the sharers. (In the case of a Core i7, the extra information is just a bit vector indicating witch of the processors has the line in its L2.)
This comment was marked helpful 0 times.

I think, compared with the limited pointer scheme on slide23, this method amortized the storage overhead to other processors in the list.
Perhaps, if we have a hash map, we can reduce M to just the number of cache line related to this processor (may be the processor is the home node or just a node in the list)
For the limited pointer scheme, if a cache line is not shared, we can also remove that entry in the directory and reduce M, can we?
This comment was marked helpful 0 times.
@kayvonf: I have a question here. As you mentioned:
However, given that cached lines are sparse, a more practical alternative would be to simply maintain a small lookup table storing the head of the list for cached lines.
I think we can also use something like the lookup table to reduce M in the Limited Pointer Schemes.
The Limited Pointer Schemes and Sparse Directories illustrated here are not as orthogonal as introduced in slide 22. The Sparse Directories illustrated here is much like the linked list extension of Limited Pointer Schemes in slide 24. The lookup table seems more precisely describing the approach to reduce M.
This comment was marked helpful 0 times.


The cost of a write is still amortized O(1) because each reader only sees one write (which then evicts it). So read, write, and flush are all O(1) operations.
This comment was marked helpful 0 times.
@jpaulson: I was confused by what you meant here. A write to line X will trigger invalidation of all caches holding the line. Therefore, a write in this doubly-linked list sparse directory scheme has latency that is O(num_sharers) and generates traffic that is O(num_sharers). Read and eviction both have O(1) cost.
EDIT: Oh, I understand your point. You're saying that the amortized cost PER MEMORY OPERATION is O(1) since you pay up front (at the time of the line load) "one credit" for the future invalidation. Good point.
This comment was marked helpful 0 times.



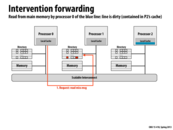
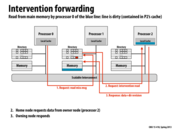
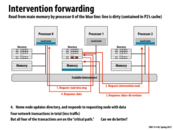
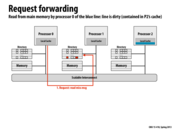
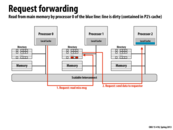
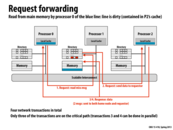

Correct me if I am wrong... I believe the dirty bit needs to be turned off? And, if it is, should it be done at step 2?
This comment was marked helpful 0 times.
@raphaelk: You are correct! The dirty bit should be off at the end of this transaction.
EDIT: The slides are fixed (you may have to refresh the page)
This comment was marked helpful 0 times.
Question: In the previous method, the owner should send dir revision to the home node and then the home node mark the request node as present in the corresponding dir entry. But here, the home node mark the request node as present right after step 1 and the dir revision msg disappears.
Why we need an additional dir revision msg in the previous methods but not need in this one?
This comment was marked helpful 0 times.
@GG: I think this method just assumed that anyone who had requested the memory would eventually become one sharer. And thus the home node can update directory after step 1.
I think the previous method could be improved in the same way. There is no need to send the dir revision message in the last step.
Anyway, the previous method is just a naive but working approach. This is why we have this slide talking about some optimization. We should not assume that the previous method is optimized already.
This comment was marked helpful 0 times.

Question: Since we can reduce the overhead of directory storage by using limited pointer schemes/sparse directory schemes, it seems that directory based coherence schemes outperform snooping schemes (i.e. in terms of scalability, communication between processors, etc.) with few disadvantages. Are there any nontrivial situations in which snooping schemes is preferred to directory based schemes?
This comment was marked helpful 0 times.
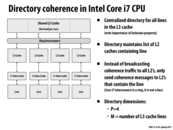
Question: what is the difference between a ring and a bus? I tried looking the words up and it seems to apply to network topology. Am I right to say that if the Shared L3 Cache didn't exist, then it will be a bus interconnect?
This comment was marked helpful 0 times.
@markwongsk: Yes, they are different interconnect implementations. I'll answer your question in the interconnects lecture in the second half of the course. The present of a cache does not change what the topology of the interconnect is.
This comment was marked helpful 0 times.
Directory-based cache and snooping-based cache are two ways to organize cache structure. They are designed to share memory in multiple caches efficiently. While update scheme and invalidation scheme are two methods to ensure cache coherence. Whether to reserve the cache lines in other caches when modifying the current one is the difference between them.
These two concepts are orthogonal, and they can pair up freely.
This comment was marked helpful 0 times.