Question: What is the bandwidth of the host memory to GPU memory? Also, should this be high? Can it be a bottleneck?
This comment was marked helpful 0 times.
jedavis
Experimentally, it appears to be about 5.5 GB/s on one of the GHC machines with a GTX480. Even if we double this like we did in assignment 1, it still seems low enough that it is very likely a bottleneck.
This comment was marked helpful 1 times.
kayvonf
The GPUs in the lab are connected to the CPU via a PCIe 2.0 x16 bus. (A 16-lane PCIe 2 bus). PCIe 2 provides a per lane throughput of 500 MB/sec, so a 16-lane bus has a theoretical peak bandwidth of 8 GB/sec.
During the review session on CUDA, it was mentioned that the actual bandwidth seen in program 3 of assignment 1 was about half of the theoretical peak. Since it seems that this theoretical peak isn't actually reached, is there a percentage that you can actually expect to see in practice?
This comment was marked helpful 0 times.
alex
@smcqueen: Actually, I've been spending a fair bit of time this week attempting to get closer to the theoretical peak for program 3. To make the problem simpler, try to just get close to the theoretical peak for writes only - i.e., make this pseudocode program get close to theoretical bandwidth:
With gcc and SSE intrinsics or ispc, I can achieve about half the theoretical peak bandwidth with writes. After some exploration, I thought I had found the problem: the cache controller must read the cache line, modify it, then write it back since SSE instructions allow 16 byte writes but cache lines tend to be 64 bytes long. The unnecessary read is causing us to only have half the desired bandwidth! However, there are some special non-temporal instructions (see here for more) that allow the processor to ignore the cache coherency protocol. When I modified the code above to use these non-temporal instructions, I get about three-quarters of the peak bandwidth on my Ivy Bride machine (but just over half on the older ghc machines).
Where is the last quarter? I don't know yet, but I'm still trying to find out. Expect a blog post when I do. In the mean time, if you can get close to max theoretical bandwidth on writes I'll buy you a beer or soda or whatever your favorite drink is.
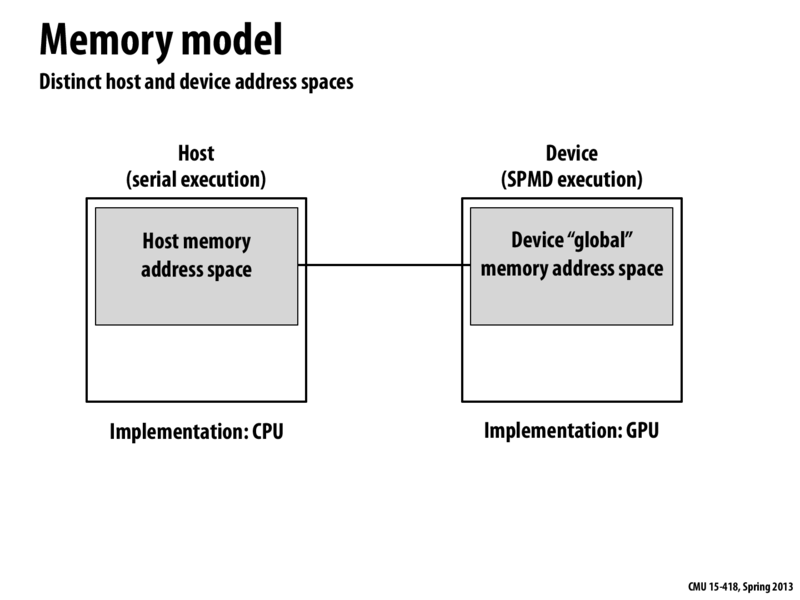
Question: What is the bandwidth of the host memory to GPU memory? Also, should this be high? Can it be a bottleneck?
This comment was marked helpful 0 times.
Experimentally, it appears to be about 5.5 GB/s on one of the GHC machines with a GTX480. Even if we double this like we did in assignment 1, it still seems low enough that it is very likely a bottleneck.
This comment was marked helpful 1 times.
The GPUs in the lab are connected to the CPU via a PCIe 2.0 x16 bus. (A 16-lane PCIe 2 bus). PCIe 2 provides a per lane throughput of 500 MB/sec, so a 16-lane bus has a theoretical peak bandwidth of 8 GB/sec.
http://en.wikipedia.org/wiki/PCI_Express#PCI_Express_2.0
This comment was marked helpful 0 times.
During the review session on CUDA, it was mentioned that the actual bandwidth seen in program 3 of assignment 1 was about half of the theoretical peak. Since it seems that this theoretical peak isn't actually reached, is there a percentage that you can actually expect to see in practice?
This comment was marked helpful 0 times.
@smcqueen: Actually, I've been spending a fair bit of time this week attempting to get closer to the theoretical peak for program 3. To make the problem simpler, try to just get close to the theoretical peak for writes only - i.e., make this pseudocode program get close to theoretical bandwidth:
With
gccand SSE intrinsics orispc, I can achieve about half the theoretical peak bandwidth with writes. After some exploration, I thought I had found the problem: the cache controller must read the cache line, modify it, then write it back since SSE instructions allow 16 byte writes but cache lines tend to be 64 bytes long. The unnecessary read is causing us to only have half the desired bandwidth! However, there are some special instructions (see here for more) that allow the processor to ignore the cache coherency protocol. When I modified the code above to use these non-temporal instructions, I get about three-quarters of the peak bandwidth on my Ivy Bride machine (but just over half on the older ghc machines).Where is the last quarter? I don't know yet, but I'm still trying to find out. Expect a blog post when I do. In the mean time, if you can get close to max theoretical bandwidth on writes I'll buy you a beer or soda or whatever your favorite drink is.
This comment was marked helpful 0 times.