




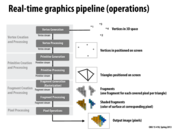
Some introduction for rendering. Rendering is a technique turn 3D world into 2D image, including consider the facts like materials, lights...etc. The image is composed of many triangle mesh. One reason to use triangle is that it guarantee all vertex are on the same plane. Introduction_to_rendering
This comment was marked helpful 0 times.






In the old days, programmers were forced to describe their materials in terms of the ten fixed parameters presented by graphics APIs. This design results in the unfortunate situation of one being able to envision a scene without being able to describe it in terms of the API and thus render it to screen (not that we're entirely unlimited with non-parameterized interfaces).
This comment was marked helpful 0 times.
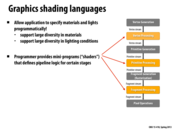

In order to not be limited to a specific number of parameters from the functions on the previous slide, programmers get much more customizability through using shaders.
This comment was marked helpful 0 times.

To clarify, a shader is just a function that tells the GPU how light or dark to color an image. Before these were supported, different 'materials' could be drawn by using different values in a parameterized list to a function. Shader support gives the programmer a lot more flexibility in creating exactly what a surface should look like when rendering an image.
This comment was marked helpful 0 times.

Shaders don't really seem limited to calculating brightness or materials - people use them for a wide variety of image manipulation. In 15-462 students use them to draw outlines around figures and show motion trails. Someone last semester made one that took a high-resolution image and turned it into a chunky 8-bit style pixelated image. I read somewhere that Pixar uses shaders that are 10,000 lines of code.
This comment was marked helpful 0 times.

Yes, a vertex shader is just a function that runs by the pipeline once per input vertex. A fragment shader is just a function that is run by the pipeline once per fragment. The graphics application defines what these computations do.
For example, a common vertex shader might compute the position of the vertex on screen (more precisely, if you've taken 15-462: the position of the vertex in 3D clip-space coordinates). A common fragment shader role is to evaluate lighting conditions and surface material properties to compute the color of triangle at the pixel corresponding to the fragment. As you might imagine, given the complexity of lights and materials in the world, these functions can get quite complicated.
This comment was marked helpful 0 times.


The important thing to note here is that the fragment shader operates like a data-parallel kernel function. For each pixel on the screen that is covered by a triangle, we take the fragment inputs and output a color to display at the pixel. We can parallelize this as a kernel function mapped onto the fragment stream since for each fragment, the work we do is independent of the work done for any other fragment.
This comment was marked helpful 2 times.




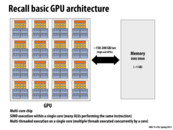
Around 2000 year, computer scientists in various fields discovered the usage of GPUs to speed up scientific computation, which led to the appearance of General-Purpose computation on GPU(GPGPU). But at that time, because GPU was designed for graphics displaying only, such programs could only be written by using graphics programming APIs, such as OpenGL and Cg, but it's rather hard to code.
Later, GPU companies develop and publish interfaces for GPU programming, which results in the fast growth of GPU computing. Today, as NVIDIA's web site says, 600 universities around the world have courses on parallel computing; hundreds of thousands of developers are actively coding on GPUs.
http://www.nvidia.com/object/what-is-gpu-computing.html
This comment was marked helpful 0 times.

A student has used this technique in 15-213 Datalab to compute two's complement arithmetic.
The resulting speedup made the student's code faster than optimal two's complement arithmetic on the hardware, surprising the course staff.
This comment was marked helpful 0 times.

Something worth noting about @Avesh's post: Based on the introduction of Autolab, all the students' code is run in virtual machines.
So, we have been demonstrated that GPU acceleration is provided even in virtual machines. Recently, Nvidia and VMware announced their first fully virtualized 3D graphics adapter in Aug 2012.[link].
So important the GPU acceleration is that people even want it in virtual machines!
This comment was marked helpful 0 times.

This may be pretty obvious, but when looking back over this slide I had forgotten the point of setting the two triangles. So if anyone else has this confusion, it is just that setting two triangles is an easy way of creating fragments (correct terminology?) that cover the whole screen, since the renderer gets run over pixels contained in the fragments.
This comment was marked helpful 0 times.
@tnebel: Correct. Rendering two triangles that exactly ocver the screen with no overlap was simply a hack to emulate a "forall output pixels" loop.
This comment was marked helpful 0 times.



The Brook language is a general purpose stream based programming language that was not originally applied to GPUs. BrookGPU was developed around 2003 and implements a subset of the Brook spec to run on GPUs.
This comment was marked helpful 0 times.

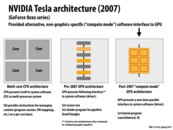

For the first time in 2007, NVidia introduces an alternative interface for system software to utilise GPU architecture -- CUDA. This new data-parallel abstraction is very C-like.
This comment was marked helpful 0 times.

ATI came out with http://en.wikipedia.org/wiki/Close_to_Metal around the same time, but it was hard to use. They followed it up with http://en.wikipedia.org/wiki/AMD_FireStream, previously ATI Stream.
This comment was marked helpful 1 times.


Question: I recall from lecture that we were supposed to 'clear the slate' in our minds as to avoid terminology confusion between SIMD and CUDA since they use similar terms such as threads. However, I feel like though SIMD threads and CUDA threads are different in terms of location where they run (CPU vs GPU), they are still fundamentally quite the same. They execute in parallel with one another and return when all are finished. In thinking this, am I missing something?
This comment was marked helpful 0 times.
Clarification: I advised that to avoid confusion, it would be wise to recognize that the pthread API, the ISPC programming language, and the CUDA programming language all use very different, and somewhat inconsistent terminology. (Not SIMD and CUDA... since SIMD is not a language).
Depending on context, the term "thread" can sometimes be used to generically refer to a "thread of control in a program", to a hardware execution context, to a pthread (a logical thread of control mapped to an execution context on a CPU core), or a CUDA thread (a logical thread of control that is mapped to a single "lane" of a SIMD set of ALUs in a GPU).
But yes, both a pthread, an ISPC program instance, and a CUDA thread present the program the abstraction of a logical "thread" of control. They just have very different mappings to hardware.
This comment was marked helpful 0 times.

Although CUDA is initially designed to handle computational tasks, it can also be used for Graphics. We can map some resources from OpenGL and Direct3D into the address space of CUDA, to enable them to interoperate with each other. In this way, we can reduce data transfer between the CPU and GPU, which causes a significant bottleneck in performance and we can also improve the performance of many graphical algorithms. More details can be found here.
This comment was marked helpful 0 times.


Question: Is CUDA an example of a shared address space model or message passing model? Variables can have the __shared__ attribute, but we also said cudaMemcpy is like message passing.
This comment was marked helpful 0 times.

Well, CUDA definitely uses a shared address space for threads. All threads within a block can communicate by reading from and writing to variables in shared memory. We even have global memory, which is a shared memory space for a given device to which threads from multiple blocks on the device can read and write.
We do have the cudaMemcpy operation between the host and device, and while it's the only way of passing information between these two devices, I'm not sure that it ascribes entirely to the 'message passing' model we saw in class. It seemed like our models were specific to describing a means of communicating between concurrent threads, which is not what is happening between the host and device. At least, not in the examples we've seen so far.
This comment was marked helpful 2 times.

To the first question, CUDA should be considered as data-parallel programming model because it supports numberBlocks and threadsperblock (up to 3D).
To the second question, CUDA is also an example of shared address space model. As mentioned above, there exists global shared memory per chip, and also shared memory per block and memory space only accessible for each thread.
To the third question, cudaMemcpy is an example of message passing as its the primary mechanism of passing data between the host and device address spaces.
Compared to ISPC instances, threadID is similar to programIndex. blockDim is similar to programCount.
This comment was marked helpful 0 times.
@martin: While CUDA's blockDim can be compared to ISPC's programCount in that both define the number of logical threads of control in a grouping, there's one small difference when considering implementation. All the threads in a CUDA thread block do not necessarily execute in SIMD lockstep, but all the instances in an ISPC gang do. Therefore, when considering implementation details, ISPC's programCount is actually most similar to CUDA's warpSize. Both values give the number of program instances (or CUDA threads) that execute in SIMD lockstep.
This comment was marked helpful 0 times.

In my view, a CUDA thread is much like an instance in ISPC arch. All CUDA threads in a warp run according to SIMD rule as the gang in ISPC, which is designed to utilize ALUs fully and is an issue of implementation. Thread block, which is set by user, consists of warps. What makes the concept of thread block important is that threads in the same block can synchronize easily and use shared memory efficiently. In the implementation, threads in a block are surely assigned to one core and will not be revoked from the core until it finishes(due to independence). A set of thread blocks is designed by programmer to solve problems. In implementation, a certain hardware controls the distribution of thread blocks to cores. One core may hold many thread blocks to hide latency. Unscheduled thread blocks will be assigned to some core by the hardware later, which reminds me of task in ISPC.
This comment was marked helpful 0 times.


Block groups are an implementation-level detail.
There is block-level shared memory and some synchronization operations at the per-block level.
This comment was marked helpful 0 times.

Here both blocks and threads per block are in the 2-dimension array. Each time you should tell the number of blocks and threads per block and the total threads you use is the number of blocks times the number threads per block.
This comment was marked helpful 0 times.
threadIDx is akin to program index. blockDim is akin to program count. blockID is akin to task ID.
This comment was marked helpful 0 times.

One advantage of keeping block-level memory is that this kind of shared memory is cheaper.
This comment was marked helpful 0 times.

The shared memory is on-chip, smaller but faster. The idea might be similar to the cache in the memory hierarchy. Another benefit is that it allows the threads in a block to communicate via memory.
This comment was marked helpful 0 times.
@Tao: Yes, you can think about the shared memory like a cache since data in shared memory is resident in low-latency, on-chip storage. The primary difference between shared memory and a traditional cache is that a program has to manually load data into shared memory (software manages what data is stored in the shared memory). In contrast, a cache is largely transparent to software: a program just issues loads and stores and the hardware manages what data is stored in a cache.
Another name for the storage used to implement shared memory is a "scratchpad".
If you read more closely about the details of an NVIDIA GPU, you'll find that each core has a fixed amount of addressable on-chip storage. This storage can be dynamically configured into a scratchpad region that is used for CUDA shared memory allocations and a part that functions as an L1 cache for off-chip global memory. On most recent NVIDIA GPUs (certain true of the 480 and 6xx GPUs in the lab), there's 64 KB of storage per core, of which at least 16 KB must be reserved for shared memory.
This comment was marked helpful 1 times.

SPMD = Single Program Multiple Data, a subcategory of MIMD (Multiple Instruction, Multiple Data). Can run the program simultaneously at independent points unlike SIMD, which imposes lockstep.
This comment was marked helpful 0 times.


Question: Does the "Host" code and the "Device" code run on separate address spaces? For the saxpy part of assignment 2, I tried to run the code without having done a cudaMemcpy which immediately segfaults which would seem to suggest so.
This comment was marked helpful 0 times.
Yes, you should consider host addresses and device addresses to reside in different address spaces.
I don't believe your code should SEGFAULT provided the device global memory accessed by the CUDA threads is properly allocated. Leaving out the cudaMemcpy should simply skip the transfer of data from the host to the device address spaces. Can you re-check? (And we can potentially take the discussion over the Piazza if there are issues.)
This comment was marked helpful 0 times.

A summary about the CUDA function declarations:
| Executed on | Only callable from | |
| __device__ float DeviceFunction() | device | device |
| __global__ void KernelFunction() | device | host |
| __host__ float HostFunction() | host | host |
the kernel function is the function that really launch the parallel execution. Note: a kernel function must return void.
I think this will help to understand the host and device code run in different space address.
This comment was marked helpful 3 times.

A function declared without any of __device__, __global__ and __host__ is equivalent to that function declared with only __host__.
This comment was marked helpful 0 times.

It is also interesting to note that __global__ functions can now be called from the device on devices that have compute capability 3.x (according to the CUDA C Programming Guide).
This comment was marked helpful 0 times.

Question: Is it bad style to call malloc from a Cuda kernel? Are there any situations where calling malloc would even be encouraged?
This comment was marked helpful 0 times.

@xs33 I'd imagine it would be bad. All the threads in a single warp would start executing malloc in lockstep. However, if you're talking about a device specific malloc that allocates memory out of each thread's local storage, that might be more feasible.
The safer way to do this would obviously be to malloc each thread's storage up front, and then parcel it out to each thread as it runs.
This comment was marked helpful 0 times.

If you want to write a function that is accessible on both host and device (you might do this for a function like max) you can do this by adding both __host__ and __device__ to the function declaration.
This comment was marked helpful 0 times.

The # of threads launched is not necessarily equal to the # of data points to process; the programmer is responsible for managing the assignment of work (e.g., elements of an array) to CUDA threads.
This comment was marked helpful 0 times.

As pointed out by someone in the lecture, Nx/threadsPerBlock.x should be rounded up (Nx/threadsPerBlock + 1) and similarly for the y-dimension of blocks. Hence, each block has 4x3 threads (the third dimension is always 1) and there is a grid of 3x2X1 blocks. To elaborate @jpaulson's point, in this example, the total number of threads launched are 12 * 6 = 72. But only 11*5 = 55 threads would actually be doing useful work.
This comment was marked helpful 0 times.

Just to elaborate on the last 2 posts, there are 2x3 = 6 blocks and 4x3 = 12 threads in each block for a total of 72 threads. The matrices being added are 11x5. The way matrixAdd is assigning threads to indices of the array, some threads are being assigned indices that are out of bounds of the array so the if statement is necessary to prevent out of bounds array access.
This comment was marked helpful 0 times.

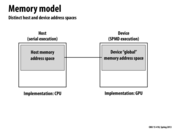
Question: What is the bandwidth of the host memory to GPU memory? Also, should this be high? Can it be a bottleneck?
This comment was marked helpful 0 times.

Experimentally, it appears to be about 5.5 GB/s on one of the GHC machines with a GTX480. Even if we double this like we did in assignment 1, it still seems low enough that it is very likely a bottleneck.
This comment was marked helpful 1 times.
The GPUs in the lab are connected to the CPU via a PCIe 2.0 x16 bus. (A 16-lane PCIe 2 bus). PCIe 2 provides a per lane throughput of 500 MB/sec, so a 16-lane bus has a theoretical peak bandwidth of 8 GB/sec.
http://en.wikipedia.org/wiki/PCI_Express#PCI_Express_2.0
This comment was marked helpful 0 times.

During the review session on CUDA, it was mentioned that the actual bandwidth seen in program 3 of assignment 1 was about half of the theoretical peak. Since it seems that this theoretical peak isn't actually reached, is there a percentage that you can actually expect to see in practice?
This comment was marked helpful 0 times.

@smcqueen: Actually, I've been spending a fair bit of time this week attempting to get closer to the theoretical peak for program 3. To make the problem simpler, try to just get close to the theoretical peak for writes only - i.e., make this pseudocode program get close to theoretical bandwidth:
char buffer[NUM_BYTES];
double start_time = get_current_time_in_seconds();
for (size_t i = 0; i < NUM_BYTES; i++) {
buffer[i] = 0;
}
double end_time = get_current_time_in_seconds();
double bandwidth = (double) NUM_BYTES / (end_time - start_time);
With gcc and SSE intrinsics or ispc, I can achieve about half the theoretical peak bandwidth with writes. After some exploration, I thought I had found the problem: the cache controller must read the cache line, modify it, then write it back since SSE instructions allow 16 byte writes but cache lines tend to be 64 bytes long. The unnecessary read is causing us to only have half the desired bandwidth! However, there are some special non-temporal
instructions (see here for more) that allow the processor to ignore the cache coherency protocol. When I modified the code above to use these non-temporal instructions, I get about three-quarters of the peak bandwidth on my Ivy Bride machine (but just over half on the older ghc machines).
Where is the last quarter? I don't know yet, but I'm still trying to find out. Expect a blog post when I do. In the mean time, if you can get close to max theoretical bandwidth on writes I'll buy you a beer or soda or whatever your favorite drink is.
This comment was marked helpful 0 times.

cudaMemcpy should remind you of message passing.
This comment was marked helpful 0 times.
For now, implemented as a DMA.
This comment was marked helpful 0 times.
There are many cudaMemcpy variants which can be seen at NVIDIA CUDA Library: cudaMemcpy. Variants include functions such as cudaMemcpy2D (which copies a 2D matrix from one memory area to another), cudaMemcpyAsync (which is asynchronous on the host and can return before the copy completes), and many others.
Note that almost every function also includes an asynchronous variant. Many of the functions also take a cudaMemcpyKind argument (one of cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, or cudaMemcpyDeviceToDevice), which specifies the direction the copy is being performed.
This comment was marked helpful 0 times.
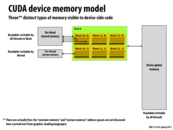
Remember, the closer you get to the thread, the cheaper memory accesses are.
This comment was marked helpful 0 times.

All threads can share memory if they are in the same block.
There is one instance of shared memory per block, while there is also one instance of local memory per thread, and one instance of global memory which is written to by all threads.
This comment was marked helpful 0 times.
Question:
Does the 'device global memory' in this diagram refer to the memory of the GPU? If so, does the GPU's memory actually behave in exactly the same manner as main memory does (perform caching and such) or are there some small discrepancies between the two?
This comment was marked helpful 0 times.
Yes. In modern GPUs device global memory corresponds to high-performance DDR5 DRAM resident on the GPU board (but not on chip). You can think of this memory just as you think of main system memory accessible to a CPU (typically DDR3 these days). The GPU does cache part of this address space, although GPU caches tend to be smaller than those on a chip.
This comment was marked helpful 0 times.
Use a table to conclude this part. Suppose we have M blocks, and each block has N threads.
| Memory type | num of such memory | Accessed by | Size | Speed |
|---|---|---|---|---|
| Device Global Memory | 1 | M*N threads | Large | Slow |
| Per-block shared memory | M | N threads in same block | Medium | Medium |
| Per-thread private memory | M*N | 1 threads | Small | Fast |
This comment was marked helpful 0 times.

Question: If we wish to achieve barrier synchronization between different blocks, then do we have to break the work as different kernel functions?
This comment was marked helpful 0 times.

@Mayank -- I'd say yes: since there's no guarantee about the order in which kernel blocks are run, it doesn't make much sense to have one block stop in the middle of a kernel function and wait for another block (or all other blocks) to catch up.
Edit: after some searching around, I found this paper that demonstrates that it's possible to synchronize between blocks in a way that boosts performance, at least for some problems. I don't think there's an official way to synchronize between blocks other than using multiple kernels (remember that GPUs were designed for handling independent data), and it's probably still not a good idea unless you really know what you're doing.
This comment was marked helpful 0 times.
Keep in mind the following statement in Section 5 of the paper referenced by @briandecost:
"Our solution to this problem is to have an one-to-one mapping between thread blocks and SMs. In other words, for a GPU with "Y" SMs, we ensure that at most "Y" blocks are used in the kernel. In addition, we allocate all available shared memory on a SM to each block so that no two blocks can be scheduled to the same SM because of the memory constraint.
This is exactly what I describe in slide 49. Since CUDA gives you global synchronization primitives that work across blocks, it is possible to use those primitives to build inter-block communication like how I do on slides 47 and 48.
However, we must stay mindful of the difference between CUDA's semantics and it's implementation on GPUs. It's not a question of official vs. unofficial, it's simply a question whether the programmer is willing to make assumptions about the implementation of the GPU's block scheduler or not. In the paper @briandecost cites, as well as in the example on slide 49, the program is written assuming that if N thread blocks are launched on a a GPU with N cores, the GPU will run all N tasks simultaneously on all the cores. This is an assumption about CUDA's implementation. It happens to be a correct assumption for current NVIDIA GPUs, but CUDA does not specify this behavior. If NVIDIA ever wanted to change this implementation in future GPUs, and say, use only half the GPU's cores to run the program, they are certainly allowed to do so (the implementation would still be valid according to CUDA's semantics). However, this implementation change would cause these programs to deadlock.
In spirit, a CUDA program defines a large stream of thread blocks, and those blocks are dynamically assigned to cores. In this manner, it makes sense to think of the work done by a thread block as a sub-problem, and its advisable for the programmer to break of problem into many more sub-problems than cores in order to achieve an even distribution of work onto the cores. If a programmer instead chooses to create exactly as many thread blocks as cores, the programmer is no longer thinking about splitting up work into subproblems, he/she is thinking about spawning a bunch of endlessly running low-level workers. The program takes ownership of manually assigning work to these workers (using global synchronization primitives to facilitate coordination). Essentially, it's like treating a thread block very much like a pthread.
This comment was marked helpful 1 times.
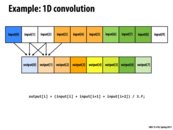
An example of a very simple 2D convolution is a "blur" convolution function in shader programming. For some indices i,j, we could make a very simple convolution as following:
output[i][j] = (input[i-1][j-1] + input[i-1][j] + input[i-1][j+1] + input[i][j-1] + input[i][j] + input[i][j+1] + input[i+1][j-1] + input[i+1][j] + input[i+1][j+1]) / 9.f;
This is similar to the slide, but for the 2D case. Assuming the output and input arrays were colors, this would, for each pixel, take the average of the color of the pixel and that of every adjacent (including diagonal) pixel.
This comment was marked helpful 0 times.

__shared__ means shared among every thread in a block.
This comment was marked helpful 0 times.
Note that the spec of this program is output[i] = (input[i] + input[i+1] + input[i+2]) / 3.0f
and NOT output[i] = (input[i-1] + input[i] + input[i+1]) / 3.0f
This comment was marked helpful 0 times.
Each of the 128 threads takes its input at index and copies it to the shared support array. The first two threads do double-duty to copy all N+2 pieces of input data.
__syncthreads ensures that all of the input data is copied into the shared block memory before each thread computes its output.
This comment was marked helpful 2 times.
The structure of this program allows us to minimize the expensive load from main memory, by copying the data to shared memory (in parallel). Then when each thread needs to access this memory it stored in the cheaper shared memory.
This comment was marked helpful 1 times.
Using the support array shared across the block, we prevent each thread from having to load three array values from input to calculate its convolution output and instead can load each value in input only once.
Thus, for each block we only have to make $n+2$ ($n =$ THREADS_PER_BLK) loads from input instead of $3(n+2) - 6 = 3n$ loads if we had not used support (each of the $n+2$ elements in input would be loaded 3 times, except input[0] and input[n+1] are only loaded once and input[1] and input[n] are only loaded twice, making 6 less loads).
This comment was marked helpful 2 times.
The total number of blocks in this piece of code is N / THREADS_PER_BLK
This comment was marked helpful 0 times.
What is the actual benefit achieved in terms of time? As @jcmacdon pointed out, we would be doing 3 times more loads from global memory if we did not use shared memory. However, since 2 threads perform 2 loads instead of 1, they also blocks all other threads (due to __syncthreads() barrier). So is the savings in terms of time $3/2$ instead of $3$?
This comment was marked helpful 0 times.
The discussion seems to revolve around THREE possible implementations of convolve program above:
- An implementation where shared memory is NOT used at all and each thread issues three loads for the data it needs.
- An implementation where thread 0 perform all loads into shared memory for the entire block.
- The implementation provided above, which uses all threads in the thread block to cooperatively load the union of all their required data into shared memory. Here, that's 130 elements of the input array.
Let's consider each possible program, and how it might map to a GPU. I will describe the implementations relative to option 3, since we described option three in detail in class, and also since that's the implementation shown above.
Option 1: This option is arguably the simplest option, since each CUDA thread operates independently and makes no use of the synchronization or communication capabilities of threads in a thread block. However, all together, the threads issue three times as many load instructions as in the code above. In the earliest CUDA-capable GPUs, all accesses to global memory were uncached, so three times the number of load instructions also entailed three times more data transferred from memory (ouch!). Modern GPUs feature a modestly sized L1 and L2 cache hierarchy, so the bandwidth cost of issuing three times as many loads as necessary is certainly mitigated since the program will benefit from hits in the caches. It is possible that on one of the GTX 6XXX GPUs, option 1 is competitive with, or perhaps faster than, option 3 on this simple program. Someone should code it up and let us know.
Option 2: The option only issues the required amount of loads, but does so sequentially in a single thread. It will take a significant amount of time to issue all these instructions. Also resenting 130 loads to the chip one-by-one will almost certainly not make good use of the wide memory bus on a GPU that is designed to satisfy many loads from multiple threads at once.
Option 3: This code does have the inefficiency that two threads in a block have to do more work than the others, since 130 is not equally divided by 128. However, the extra work is not as bad as you might think. First, executing 4 instructions (load from global, store to shared, load from global, store to shared) in two CUDA threads and 2 instructions (load from global, stored to shared) is certainly better workload balance than performing 260 instructions sequentially in one thread (130 loads from global and 130 stores to shared) while the others sit idle. Further, keep in mind that only threads assigned ot the same GPU hardware warp (not all 128 threads in a block) execute in SIMD lockstep, so in this example there's divergence in only one of the four warps that make up a block! If you're an astute reader, and are worried about the core going idle (because one warp is blocked on memory for those last two loads and and the other three are waiting at the barrier), I'll point out that slide 52 says that a single core of a GTX 680 GPU can interleave up to 16 blocks (or up to 2,048 CUDA threads, whichever is the limiting number for a program). So the GPU scheduler almost certainly will take my simple program above and assign 16 blocks to each GPU core at once! Warps from these blocks execute interleaved on the core as discussed in Lecture 2. That means that if all warps from one block cannot make progress, there are 15 other blocks (all together totally 60 other warps) for the core to choose from. That's a lot of hardware multi-threading! And a lot of latency hiding capability!
I encourage you to just try coding up the possible solutions and observe what happens on a real GPU!
This comment was marked helpful 2 times.
So I wrote up and benchmarked those three options. On the GTX 480, we see this (numbers are seconds to run the kernel 1000 times):
Option 1: 0.092963573
Option 2: 1.251477951
Option 3: 0.086575691
There doesn't seem to be any way to turn off the L2 cache, but we can disable the L1 cache by passing -Xptxas -dlcm=cg to nvcc. With that, there's an enormous difference on option 2:
Option 1: 0.097117766
Option 2: 2.815642568
Option 3: 0.086821925
I would guess that the L1 cache doesn't really matter too much for options 1 and 2 because a warp ends up consuming an entire cache line at once, avoiding the need to ever go back to cache.
On the GTX 680, we see roughly the same performance characteristics:
Option 1: 0.073917068
Option 2: 0.927370628
Option 3: 0.072028765
and without the L1 cache:
Option 1: 0.078198984
Option 2: 2.064859373
Option 3: 0.072251701
So it looks like option 2 is a terrible idea, and option 3 copies give you a ~7-8% performance boost on this kind of operation.
Code available here
This comment was marked helpful 5 times.
Amazing job @sfackler. I am surprised that disabling L1 does not impact option 1 more because there is 3x reuse in the program. What happens if you add a bit more reuse with a 5-wide convolution window (-2,-1, 0, 1, 2)?
This comment was marked helpful 0 times.
A 5-wide window bumps the runtimes up to:
Option 1: 0.143365269
Option 2: 1.274452689
Option 3: 0.088349569
with L1 and
Option 1: 0.133055357
Option 2: 2.858435744
Option 3: 0.088058527
without.
A 7-wide window takes:
Option 1: 0.168962534
Option 2: 1.296426201
Option 3: 0.091151181
with L1 and
Option 1: 0.166247257
Option 2: 2.901670890
Option 3: 0.091110048
without.
I updated the code with a WINDOW #define.
This comment was marked helpful 0 times.
Interesting. I cannot explain the lack of sensitivity to enabling/disabling the L1 cache. Perhaps someone from NVIDIA can help.
This comment was marked helpful 0 times.

Shouldn't the call to cudaMalloc(&devInput;, N) be cudaMalloc(&devInput;, sizeof(float) * N)?
This comment was marked helpful 0 times.

There are no high-level synchronization primitives across blocks.
This comment was marked helpful 0 times.


shared variables allow you to share memory between all the CUDA threads on a block on the GPU. The GPU has a certain memory allocated for specific block and per specific thread.
This comment was marked helpful 0 times.

All threads can read and write to a shared address space but there is also one instance of shared memory per thread. Threads belong to blocks but we must also remember that each block is assigned to a core so the threads run like SIMD instructions. However, to answer @kayvonf I don't think that CUDA threads in different thread blocks can communicate through shared variables, disproving your first statement that shared variables allow you to share memory between each block on the GPU.
This comment was marked helpful 0 times.
@mitraraman: Are you sure about: "All threads can read and write to a shared address space but there is also one instance of shared memory per thread". All CUDA threads can certainly read and write to/from global memory, which is indeed a single address space accessible to all threads created during a kernel launch. But this conversation is specifically about variables declared with the shared keyword in CUDA. Is there an instance of these variables per thread? One per thread block? Or per program? Can someone clear all this up?
This comment was marked helpful 0 times.
Attempting to clear up what CUDA shared memory is:
slide 30 presents the CUDA memory model on the GPU nicely. (and @Max summarizes it nicely)
In the CUDA device address space, there are 3 types of variables:
- local to a thread
- local to a block (on-chip, declared with
__shared__keyword inside the kernel) - global (main memory, like the global arrays allocated in the host code with cudaMalloc())
so there's one instance of a shared variable per thread block, stored in on-chip memory (so there's less latency when accessing them).
This comment was marked helpful 0 times.
I think we can say from a programmer perspective, the resources that each thread can access are:
| 1. r/w per-thread registers. (extremely high throughput.) |
| 2. r/w per-block shared memory. (on-chip memory, so high throughput.) |
| 3. r/w per-grid global memory. (something like main memory, so modest throughput.) |
| 4. r Only per-grid constant memory. (since using caching, also high throughput.) |
This comment was marked helpful 0 times.

The answer is NO to both questions in the slide.
Blocks and threads are logical concepts in CUDA program. How to allocate resources depends on the GPU core. If there are 8000 blocks and only 4 cores, there will be only 4 instances of the shared float array. These four instances will be reused for these 8000 blocks.
This comment was marked helpful 2 times.

CUDA does not let the programmer directly assign work to the hardware
This comment was marked helpful 0 times.

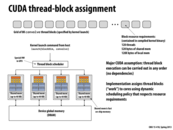

The implementation can assign blocks of work to different cores. This means that resources do not need to be reallocated. In the example, this means that we don't need to allocate 8000 arrays of 130 floats. Instead, each core can allocate the space needed (in the space labeled Shared mem) and reuse it for each block that it runs.
This comment was marked helpful 0 times.
The independence requirement allows thread blocks to be scheduled in any order across any number of cores, enabling the programs to be run on all kinds of GPUs without modification. And if you do require inter-block communication, which breaks the independence assumption, you have to make assumptions about the implementation of the GPU's block scheduler, as is discussed in the comments of slide 31.
This comment was marked helpful 1 times.

Since the thread block execution can be carried out in any order and also possibly simultaneously using multiple cores, one must be careful when reading and writing from global memory. One would need to lock any global variable being accessed across thread blocks in order to avoid race conditions.
This comment was marked helpful 0 times.
@ajindia As I learned painfully from Assignment 2, locking in CUDA with a shared memory mutex/semaphore is hard. There is no cache coherency protocol in place, so every read and write needs to be done with an atomic instruction. Also, because all the threads in a warp execute in lockstep, you incur a lot of thrashing because different threads will all attempt to grab the lock at exactly the same time, leaving it completely arbitrary as to who gets the lock (no bounded waiting, etc). You're better off writing to a local array, and then in the host code accumulating all the results and writing to global memory in one transaction.
This comment was marked helpful 0 times.


An example: Writing a CUDA program with a thread block count of 1024 is probably not a good choice in this case - as the thread count limits the number of blocks that can be scheduled on a core at once to 1 since 2*1024 > 1536.
This comment was marked helpful 0 times.
@aditm, you're thinking along the right lines. However, keep in mind there is nothing wrong running a single block of 1024 CUDA threads if 1024 CUDA threads (32 warps) provide sufficient parallelism for the core to hide stalls. More warps would provide more latency hiding, but it may not be necessary if the program has sufficient arithmetic intensity.
The end goal is to keep the execution units busy, it's not to maximize latency-hiding ability. It fact, it's preferable to execute with only the minimum number of threads needed to cover stalls. With fewer threads, you can use more resources per thread, e.g., more shared memory per thread, more L1 cache per thread, etc. In fact, there are situations where a lower thread count will yield better performance if the presence of more per-thread resources does more to prevent stalls than multi-threading does to hide them.
This comment was marked helpful 0 times.
@aditm @kayvonf i think there is a mistake in the above comment. The number of blocks that can be scheduled on a core at once should be 12 not 1, because threadsPerBlock in this example is 128 hence 1536/128 = 12 blocks can at most be scheduled on the same core at once.
Another thing I would like to add is that since CUDA doesn't allow the programmer to assign work directly to hardware but via a special block scheduler, the programmer can basically create as many threads as they want and the hardware would assign the work properly.
This comment was marked helpful 0 times.
@martin: I believe @aditm was making up his own example of a CUDA program with a thread block size of 1024. He points out the since 1024 doesn't divide 1536 evenly, a CUDA program with 1024 threads in a thread block won't ever benefit from the maximum latency hiding of the chip. I pointed out that this is certainly true, but not necessarily bad, if 1024 threads (32 warps) is sufficient to hide memory stalls in the program.
As you correctly state, for the convolve example used in this lecture, the thread block size is 128, so 12 blocks can be scheduled onto one GTX 480 SM core. This is also pointed out in the slide.
This comment was marked helpful 0 times.
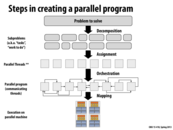

CUDA thread == one ALU == ISPC loop iteration
CUDA block == one core == ISPC task
This comment was marked helpful 0 times.

I think that a CUDA thread is more like an ISPC program instance. (I'm not sure if by 'loop iteration' you mean a single program instance, or a gang of ISPC program instances.)
This comment was marked helpful 0 times.

@jpaulson: I don't think CUDA thread == one ALU, CUDA block == one core are correct. Because one core in GPU could contain different blocks, and multiple threads may exists inside one ALU.
This comment was marked helpful 0 times.
@jpaulson. Be careful about the use of == since the the two quantities you are equating very different. One is a CUDA abstraction, and the other is a GPU hardware unit. Really the concept you are thinking about is the relationship between programming model concept and its implementation on a hardware unit.
Current CUDA implementations execute a CUDA thread using a single ALU in a SIMD group of ALUs. A CUDA thread block is mapped to a single GPU core, but multiple thread blocks can be interleaved on a core at once. As @mmp says, a good analogy to a CUDA thread is an ISPC program instance.
For more detailed discussions of how CUDA programs execute on modern GPUs, take a look at the next slide as well as slide 52.
This comment was marked helpful 0 times.

warp == ISPC gang
This comment was marked helpful 1 times.
Warps are exposed in CUDA. The warpSize built-in variable contains the number of threads per warp. In addition, there are "warp vote functions" __all, __any and __ballot and "warp shuffle functions" __shfl, __shfl_up, __shfl_down and __shfl_xor.
This comment was marked helpful 1 times.
Very good point @sfackler. The concept of a warp was not exposed in the early versions of CUDA. However, as reasoning about warps (about the underlying implementation of a CUDA program) is often required for performance tuning (just as it was important in Assignment 1, Program 4), the warp size ended up hard-coded in many optimized CUDA programs. As a result, later versions of CUDA have exposed the warp size and also warp-granularity operations using the constructs you mentioned.
Exposing these hardware capabilities is also consistent with NVIDIA's goal of maintaining a low abstraction distance between CUDA programs and the underlying hardware implementation. In general, I'd say CUDA's design reflects the philosophy that allowing programmers to maximize performance takes precedence over code portability. Obviously maintaining both are desirable, but in design choices that trade one off for the other, NVIDIA seems to have taken the performance-centric view most of the time.
This comment was marked helpful 0 times.

Question What happens when threads per block is less than 32? My guess is that it will run normally as if it had 32 threads (as if we don't use all the ALUs in ISPC). So if my guess is right, would it be more efficient to assign threads per block to be at least 32 if possible?
This comment was marked helpful 0 times.
@danielk2: Logically, the program runs as if it created N CUDA threads, where N is the number of threads per block specified. However, in the case you propose (N<32), your program's CUDA thread block would get mapped to one hardware warp. Certain threads of the warp would get masked off and the code would run at lower than peak efficiency. You can think of it as if the warp was divergent for the entire program.
This comment was marked helpful 0 times.
I have several questions:
1) If some threads in a warp are stalled, can core switch to do another warp?
2) If some warp hold on (eg:explicitly call function to wait for other threads in the block), can core do another warp?
3) If a block is not done, can core switch to another block?
4) if warp can be switched, does it mean the thread contexts (local variables) will be changed? if block can be switched, does it mean the block contexts (local variables) will be changed?
This comment was marked helpful 0 times.
Here is a simple (and sufficiently accurate for the purposes of this class) way to think about how an NVIDIA GPU core (a.k.a. SM) runs CUDA threads: First, don't think about individual CUDA threads, just consider the scheduling of warps. Since the warp is the minimum granularity of scheduling, it does not help to think about scheduling the individual CUDA threads.
The GTX 480 SM (core) in this figure can maintain up to 48 warp execution contexts at once. These execution contents can be from different thread blocks if more than one thread block is assigned to the core at once.
At any point in time, each warp is either runnable or not. Warps that are NOT runnable may be in this state because they are waiting on memory, waiting on other warps to reach a __syncthreads point, etc.
Each clock, the scheduler chooses up to two runnable warps to execute, decodes the next instruction in the instruction stream for each of these warps, and then executes the instruction on the core's SIMD array of ALUs.
When a warp terminates, not much happens. However, when all the warps executing CUDA threads in a thread block have terminated (that is, the block is complete), all the execution contexts for the block become free, so the scheduler is able to assign a new thread block to the core. State for this new thread block will get mapped to the available warp execution contexts.
This comment was marked helpful 0 times.

@jpaulson @kayvonf:
There's another difference, which has to do with the fact that ISPC instances on x86 map to lanes in a single set of wide shared registers. That is, in order to carry out an instruction in an SIMD setting, you need to coalesce the input of all instances into a single (or a pair, etc.) shared SIMD register.
On the other hand, according to NVIDIA, all threads get their own register state.
http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architecture
http://docs.nvidia.com/cuda/parallel-thread-execution/index.html
(Section 3.1 in PTX manual. I searched a couple GTX whitepapers, but they only seem to give the size of the register file, and not its structure.)
Why is this? I can understand that you might want to do 32 operations in lock-step in order to cut down on instruction fetch costs and ALU requirements for data-parallel programs. But why keep per-thread state if you're still only executing one instruction at a time?
My idea is that it might have to do with the cost of coalescing into a register.
In HW1, I tried to improve saxpy by interleaving the X, Y, and OUTPUT arrays into a single array of struct{int x; int y; int out;}. The ispc compiler actually warned me (thanks, @mmp!) about implicit gather-scatter, and my program ran a lot slower than the original.
Apparently the issue was that, in order for an ISPC gang to operate on several elements of X in the original code, it was only necessary to perform a single read from memory directly to an SIMD register. But since my code's arr[0].x and arr[1].x, etc. were no longer contiguous in memory, coalescing this data into a register presumably involved extra reads, and maybe extra work in compiling them together. I never got around to checking the assembly, but Intel describes the same issue here:
http://software.intel.com/sites/default/files/m/c/c/0/1/0/33940-OptimizingApps_Using_SIMD.pdf
I imagine that CUDA's design avoids this, since you can read from multiple banks simultaneously, and since you wouldn't need to coalesce into a single register. (But then, depending on the size of your struct, you might still wind up reading from ((int32_t\*)arr)[0] and ((int32_t\*)arr)[32] at the same time...)
I can't think of anything else, except the vague notion that you might be able to make divergent execution cheaper with such a scheme.
This comment was marked helpful 1 times.
@apodolsk: Absolutely excellent observations and question. I'll defer my answer to the weekend since a good answer is not trivial to explain. In the meantime you can Google SIMD vs. SIMT (or implicit SIMD) or try and think further about Lecture 2, slides 33 and 34.
This comment was marked helpful 0 times.
In the meantime, if anyone reads these posts and is wondering what's up: Alex R. talked to the NVIDIA lecturer about this. He said that warps' implementation can best be described as a set of shared registers, but that they reserve the right to switch to a registers-per-thread implementation and they want us to think about them as separate threads. I'm really curious to hear what's actually going on.
This comment was marked helpful 0 times.

Question: The previous slide says each block has 4 warps, and each warp can execute different instructions. But why do we have only 2 Fetch/Decode units here?
This comment was marked helpful 0 times.
@xiaowend: As the text at the bottom of the slide says, only up to 2 of the 4 warps can run at a same time. It's similar to Intel's Hyper-threading. At any time, there's a decently high probability that some of the warps are going to be blocked on memory so having a full set of 4 Fetch/Decode units and ALUs would be a waste.
This comment was marked helpful 0 times.
I'll also clarify that the previous slide refers to 4 warps because a CUDA thread block with 128 threads (which is what the CUDA program in this example specifies) will get mapped to four warps. The number 128 is specific to this example program! An NVIDIA GPU core can support interleaved execution of many warps at once. For example the GTX 680 can interleave up to 64 warps (2,048 total CUDA threads) on a single "SMX" core. See the details on slide 52 of this lecture. You can look up the details for other GPUs on NVIDIA's web site.
This comment was marked helpful 0 times.
Basically at each clock, 2 runnable warps (in total of 64 threads) can be executed once on the core's SIMD array of ALUs. And the 2 warps can be working on two different instruction streams which is also the reason why there are two fetch/decode units
This comment was marked helpful 0 times.

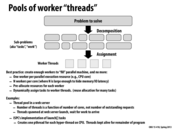
Pool of just two "worker" warps won't be a good choice as it won't provide any latency hiding capability.
This comment was marked helpful 0 times.
Correct Mayank. The GPU maintains execution context state for a far greater number of warps, and interleaves warp execution to hide warp stalls (The concept of hardware multi-threading was introduced in Lecture 2).
Question: Just to finish off the idea: How many warps can run concurrently on a GTX 480 GPU core? What about a GTX 680 GPU core?
This comment was marked helpful 0 times.

I'm not completely sure about this, but I think for a GTX 480 GPU 16 warps can run concurrently because there are only 16 ALUs. However since the ALUs run twice as fast as the rest of the chip, it looks like 32 warps can run concurrently.
This comment was marked helpful 0 times.
GTX 480 GPU is Fermi architecture while GTX 680 is Kepler. Based on the NVIDIA white paper about GTX 680, every single core in GTX 480 can run 2 warps simultaneously and every single core in GTX 680 can run 4 warps (check the item "Warp schedulers" in the sheet).
The white paper also said this about GTX 680:
To feed the execution resources of SMX, each unit contains four warp schedulers, and each warp scheduler is capable of dispatching two instructions per warp every clock.
So, on GTX 680, there would be at most 8 instructions in total be executed in every clock.
This comment was marked helpful 0 times.


As Kayvon explained during lecture, it's really important that you're guaranteed concurrent execution of threads in a CUDA block. A number of things could go horribly wrong if this wasn't the case. For example, if you tried to sync those threads (analogous to a barrier in ISPC) at some point in your code, and you only had some of the threads in a block running, they could potentially all reach the __syncthreads() call... only to wait on other threads that haven't even begun executing yet! So this CUDA constraint helps avoid nasty deadlocks like these.
This comment was marked helpful 1 times.
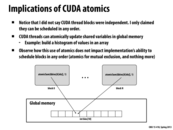


Communication via global memory through the use of a global memory atomic operation. Assume that the GPU can only run one thread block at a time. If CUDA thread blocks are not preempted (and they are not in current implementations), and block N is scheduled onto the chip first, then this program will deadlock since block 0 cannot be scheduled onto the chip, and thus myFlag is never set to 1.
This comment was marked helpful 0 times.

This slide shows that you cannot assume anything about how the GPU schedules blocks. If there is only one core, it is possible that block N will run first causing a deadlock.
However, if we change the example, and assume the gray boxes represent different CUDA threads in the same block, this program will be fine as all the threads in a block run concurrently. The core will be able to context switch these threads but, in the case above, I think there is no way for the chip to context switch the blocks.
This comment was marked helpful 0 times.
@Question: If there are two cores and there are two users running the code in this slide, if block N of two users occupy these two cores first, will there be deadlock?
This comment was marked helpful 0 times.
@TeBoring: I tried to run multiple CUDA programs on GHC machines and it works. So, the GPU can be shared by multiple processes. And we had learnt that GPU cores are so simple that they do not provide any mechanism for context switch. So, in the case you described, the blocking CUDA block will never stop nor be swapped out, and deadlock will happen.
But according to this, the WDDM 1.2 in Windows 8 will support preemption in GPU. With preemption, the blocking CUDA block would be interrupted and swapped out. I'm not sure how they achieved GPU preemption, but the much simpler model in WDDM 1.0 will work for this case, too.
With WDDM 1.0 Microsoft introduced the GPU Timeout and Detection Recovery (TDR) mechanism, which caught the GPU if it hung and reset it, thereby providing a basic framework to keep GPU hangs from bringing down the entire system.
So, the OS will notice the deadlock and reset the whole GPU. Hopefully, the scheduling order will be changed next time and the program can make progress.
This comment was marked helpful 0 times.

This solution does not seem ideal to me. Imagine one block gets stuck with several particularly lengthy threads, it will slow your entire program down. By having more blocks than cores, the cores that finish their blocks first can grab another one and work on it instead of waiting for the slow core to finish.
This comment was marked helpful 0 times.
@joe: In the code above, the user has essentially implemented a work queue. Notice how each thread block iterates in a while(1) loop, continually grabbing the next batch of work. Overall, there are N output elements to compute and each batch computes 128 elements. Once the threads in the thread block have cooperatively completed processing for this batch of 128 elements, the block then grabs a new batch. When the shared variable workCounter reaches N all work is done and the threads in the thread block terminate.
The difference between this implementation on the one shown on slide 033 hinges on who is responsible for assignment of work to threads. Here, the programmer has launched exactly as many blocks as can run concurrently on the GPU and assignment of work to these blocks is carried out manually through synchronized access/modification of the workCounter variable. As a result, this code makes very strong assumptions about the GPU it is run on, and about how the CUDA implementation schedules thread blocks onto GPU cores. In contrast, on slide 33, the programmer created many more blocks than could fit on the machine simultaneously and he/she is relying on the CUDA system to make the assignment of blocks to cores.
A similar question about who takes responsibility for assignment (the programmer or the system) was asked in the context of ISPC programming in the Parallel Programming Basics lecture on slides 002 and 003.
This comment was marked helpful 0 times.
Can someone clarify for me why BLOCKS_PER_CHIP for the GTX 480 GPU is ideally 15*12 here?
This comment was marked helpful 0 times.
@martin: The GTX 480 GPU has 15 SMs (cores) and each SM can interleave execution of up to 1536 CUDA threads (48 warps). Since the thread block size of the convolve program is 128 CUDA threads (mapping to 4 warps), 12 blocks per core can be run at a time. (This is because the core can interleave up to total of 1526 CUDA threads, and 128 * 12 = 1536.) Therefore, at most 15 * 12 CUDA thread blocks can be executed by the GPU concurrently.
The program above is written so that each thread block executes for the entire duration of the program. To achieve this behavior, the code makes specific assumptions about the number of cores in the GPU, the capabilities of those cores, and how thread blocks are scheduled onto the GPU. This program will only work as desired on a GTX 480 GPU. This is in contrast to most CUDA programs which are oblivious to most GPU implementation details: a more conventional way to write CUDA code is to create many more thread blocks than can be executed at once by the GPU and rely on the GPU scheduler to dynamically assign blocks to cores over time.
This comment was marked helpful 0 times.

Can you elaborate on the statement that "since the thread block size of the convolve program is ..." It's unclear to me why this allows the device to run 12 blocks per core. I thought that a core could only run one block at a time.
This comment was marked helpful 1 times.
Threads access workCounter via atomicInc:
int atomicInc(int *val, int amount)
where
x = atomicInc(& foo, y);
is conceptually equivalent to
atomically {
x = foo;
foo += y;
}
Here only one thread (thread 0) in each thread block calls atomicInc and increments the counter by the number of threads in the block.
Aside: It's interesting to think about what happens if each thread calls atomicInc, so each thread increments workCounter and gets a unique value from it. Remember that every thread in a warp calls each instruction at the same time. The CUDA spec says that when a warp calls atomicInc, the order that the threads "appear" to have called it in is undefined. That is, if workCounter is 0, and some warp calls x = atomicInc(& workCounter, 1), each thread in that warp will have a different value in x, ranging from 0 to 31, but we can't know ahead of time which thread has which value.
This comment was marked helpful 1 times.
@gbarboza. Multiple CUDA thread blocks can be scheduled onto a single GPU core and executed concurrently provided sufficient resources (e.g., thread execution contexts and shared memory space) exist on the core. A GTX 480 SM core can run up to 12 CUDA thread blocks at once, provided the total number of threads summed over all blocks on the core does not exceed 1536.
This comment was marked helpful 0 times.
There's some info on how CUDA allocates thread blocks here.
This comment was marked helpful 0 times.



This slide is out of date now :P GK110 is finally available to the everyday consumer
This comment was marked helpful 0 times.

Warp execution makes GPU possible to hide latency.
This comment was marked helpful 0 times.
@ypk: Could you clarify what you meant? Executing the same instruction for all CUDA threads in a warp on SIMD ALUs enables parallel execution, but does not hide latency. The processor however interleaves execution of many warps to hide large latency operations performed by any one warp.
This comment was marked helpful 0 times.

Question: We've talked about instruction-level parallelism, simultaneous hardware multi-threading, interleaved hardware multi-threading, and SIMD execution so for in the course. Examples of each of these techniques are present in how CUDA programs executes on a GTX 680 SMX core. Anyone care to explain how all these concepts pop up in the execution of a CUDA program on a GTX 680?
This comment was marked helpful 0 times.
From the GPU hardware's perspective:
- Cores running different warps in parallel provides simultaneous multithreading.
- Each core selecting and running runnable warps provides interleaved multithreading.
- Threads in each warp runs simultaneously in multiple SIMD lanes.
- Multiple fetch/decode units per core takes advantage of ILP and tries to run as many instructions in parallel as possible.
From the CUDA program's perspective:
- Multiple CUDA kernels allocated to different blocks could be running on different cores concurrently, or on the same core interleaved (both types of SMT). Different CUDA kernels could also be ran under this scheme.
- Multiple CUDA kernels allocated to the same block but to different thread indices will run concurrently on one warp on different SIMD lanes.
- ILP is "invisible" to the CUDA programmers. But code with good ILP will certainly run faster.
This comment was marked helpful 0 times.
@Xiao: Awesome! Here are a few corrections/clarifications though:
- There's also simultaneous multi-threading employed within a single SMX core by selecting up to four warps to run in a clock. Those four warps are four independent instruction streams running simultaneously.
- The multiple fetch/decode blocks serve to exploit thread-level parallelism (up to four warps per clock, as stated above) and also instruction-level parallelism (up to two independent instructions per clock per warp).
- For clarity let's use the term "CUDA thread" instead of "kernel". A CUDA kernel launch is a call of a device function that corresponds to a logical launch of many CUDA threads. The threads are organized into thread blocks. The thread-block abstraction is a strong locality hint to the GPU. The programmer is hinting to the system that threads in a block are likely to cooperate. GPU implementations use this hint as a signal that it is a good idea co-locate CUDA threads in a thread block on the same SMX core, enabling faster communication and synchronization.
This comment was marked helpful 4 times.

These days GDDR5 is the standard memory used on graphics cars, while DDR3 is the standard for system memory on the motherboard. DDR5 isn't actually a JEDEC standard ;) ... at least not yet. DDR4 is! http://eetimes.com/electronics-news/4219194/Jedec-readies-DDR4-memory-spec-
Open thread on the differences between DDR and GDDR anyone?
GDDR chips generally have a wider bus than DDR chips e.g. 32 vs 16 bits on GDDR5 and DDR3.
On GDDR5, reads and writes occur on a forwarded clock running at 4x the GPU base clock, while the data rate on DDR3 is only 2x the base clock. Essentially this means we get twice the data rate out of GDDR5 parts than we do out of DDR3 parts running at the same frequency.
Some references: http://en.wikipedia.org/wiki/GDDR5 http://en.wikipedia.org/wiki/Ddr3 http://www.elpida.com/pdfs/E1600E10.pdf
This comment was marked helpful 0 times.