Communication via global memory through the use of a global memory atomic operation. Assume that the GPU can only run one thread block at a time. If CUDA thread blocks are not preempted (and they are not in current implementations), and block N is scheduled onto the chip first, then this program will deadlock since block 0 cannot be scheduled onto the chip, and thus myFlag is never set to 1.
This comment was marked helpful 0 times.
toastifer
This slide shows that you cannot assume anything about how the GPU schedules blocks. If there is only one core, it is possible that block N will run first causing a deadlock.
However, if we change the example, and assume the gray boxes represent different CUDA threads in the same block, this program will be fine as all the threads in a block run concurrently. The core will be able to context switch these threads but, in the case above, I think there is no way for the chip to context switch the blocks.
This comment was marked helpful 0 times.
TeBoring
@Question: If there are two cores and there are two users running the code in this slide, if block
N of two users occupy these two cores first, will there be deadlock?
This comment was marked helpful 0 times.
lazyplus
@TeBoring: I tried to run multiple CUDA programs on GHC machines and it works. So, the GPU can be shared by multiple processes. And we had learnt that GPU cores are so simple that they do not provide any mechanism for context switch. So, in the case you described, the blocking CUDA block will never stop nor be swapped out, and deadlock will happen.
But according to this, the WDDM 1.2 in Windows 8 will support preemption in GPU. With preemption, the blocking CUDA block would be interrupted and swapped out. I'm not sure how they achieved GPU preemption, but the much simpler model in WDDM 1.0 will work for this case, too.
With WDDM 1.0 Microsoft introduced the GPU Timeout and Detection Recovery (TDR) mechanism, which caught the GPU if it hung and reset it, thereby providing a basic framework to keep GPU hangs from bringing down the entire system.
So, the OS will notice the deadlock and reset the whole GPU. Hopefully, the scheduling order will be changed next time and the program can make progress.
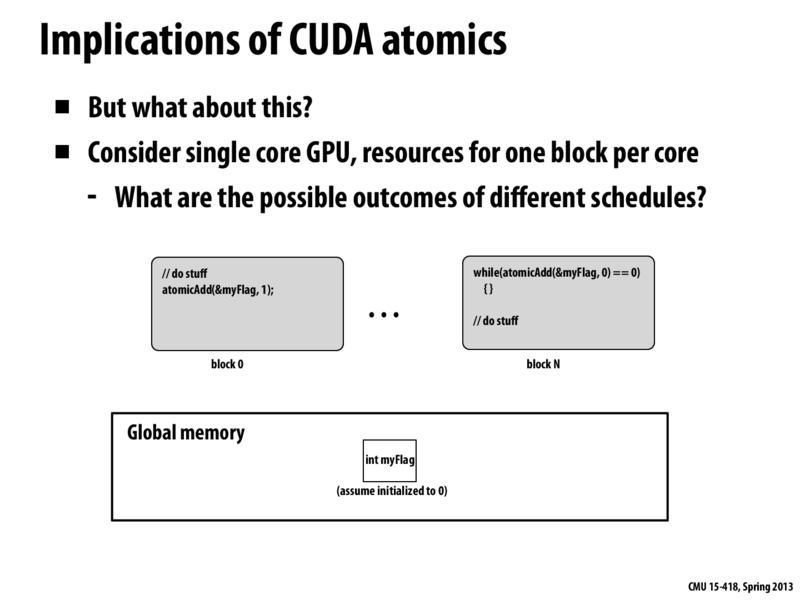
Communication via global memory through the use of a global memory atomic operation. Assume that the GPU can only run one thread block at a time. If CUDA thread blocks are not preempted (and they are not in current implementations), and block N is scheduled onto the chip first, then this program will deadlock since block 0 cannot be scheduled onto the chip, and thus
myFlagis never set to 1.This comment was marked helpful 0 times.
This slide shows that you cannot assume anything about how the GPU schedules blocks. If there is only one core, it is possible that block N will run first causing a deadlock.
However, if we change the example, and assume the gray boxes represent different CUDA threads in the same block, this program will be fine as all the threads in a block run concurrently. The core will be able to context switch these threads but, in the case above, I think there is no way for the chip to context switch the blocks.
This comment was marked helpful 0 times.
@Question: If there are two cores and there are two users running the code in this slide, if block N of two users occupy these two cores first, will there be deadlock?
This comment was marked helpful 0 times.
@TeBoring: I tried to run multiple CUDA programs on GHC machines and it works. So, the GPU can be shared by multiple processes. And we had learnt that GPU cores are so simple that they do not provide any mechanism for context switch. So, in the case you described, the blocking CUDA block will never stop nor be swapped out, and deadlock will happen.
But according to this, the WDDM 1.2 in Windows 8 will support preemption in GPU. With preemption, the blocking CUDA block would be interrupted and swapped out. I'm not sure how they achieved GPU preemption, but the much simpler model in WDDM 1.0 will work for this case, too.
So, the OS will notice the deadlock and reset the whole GPU. Hopefully, the scheduling order will be changed next time and the program can make progress.
This comment was marked helpful 0 times.