It's interesting that the fine-grained locking implementation for the linked list only performed better than coarse-grained locking when the number of threads was between 8 and 16. The paper attributed this to the overhead for the locks protecting the data structure, where $O(n)$ locks have to be acquired and released for fine-grained versus $O(1)$ locks for coarse.
This comment was marked helpful 1 times.
chaominy
Lock-free implementation can not eliminate contention, so the key point for performance improvement is getting rid of overhead in lock style implementation, such as extra acquire and release lock when there is no contention.
This comment was marked helpful 0 times.
yongzuaw
Although lock-free implementation avoid lock usage, it restricted the optimization by memory relaxation. Therefore it may not reduce latency as much as we expected.
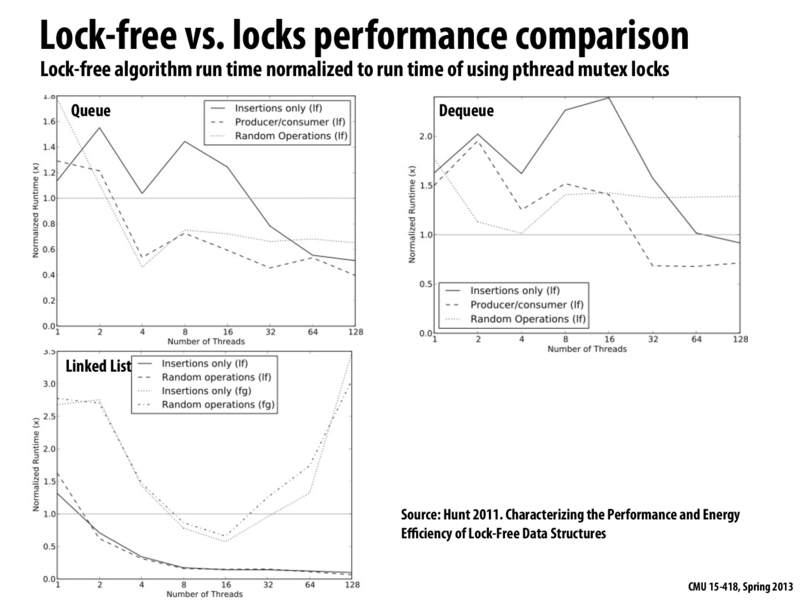
It's interesting that the fine-grained locking implementation for the linked list only performed better than coarse-grained locking when the number of threads was between 8 and 16. The paper attributed this to the overhead for the locks protecting the data structure, where $O(n)$ locks have to be acquired and released for fine-grained versus $O(1)$ locks for coarse.
This comment was marked helpful 1 times.
Lock-free implementation can not eliminate contention, so the key point for performance improvement is getting rid of overhead in lock style implementation, such as extra acquire and release lock when there is no contention.
This comment was marked helpful 0 times.
Although lock-free implementation avoid lock usage, it restricted the optimization by memory relaxation. Therefore it may not reduce latency as much as we expected.
This comment was marked helpful 0 times.