To review, the role of caches in CPUs and GPUs are slightly different. In a CPU, caches are used to minimize latency because there are no other mechanisms to handle it (except for prefetching). In GPUs, where we can handle latency with multi-threading, we still have caches to service requests to avoid going out to the lower-bandwidth memory system.
This comment was marked helpful 0 times.
kayvonf
Yes, the major motivation for caches in a throughput-oriented system such as a GPU is to increase the effective bandwidth to processing elements. If reuse exists, the caches act as a "filter" absorbing many requests before they go out to memory. As a result, the processors receive data at the rate that can be provided by the cache, rather than the rate that can be provided from DRAM.
Of course, a cache hit on a GPU also decreases memory latency as well, and perhaps could allow a program to use fewer threads and still run at full rate.
Here's an interesting thought experiment. Let's say you build a processor with high degree of multi-threading to hide memory latency. But then your processor runs a lot of threads at once, so each thread effective has only a fraction of the cache for its working set. As a result, the threads suffer more cache misses. Since more requires more loads/stores to go out to memory, more latency hiding is necessary to avoid stalls, so the chip designers add more threads... which further decreases cache hit rate. As you can see, there's an interesting feedback loop here.
Ideally, we'd like everything to be served out of caches, minimizing the energy cost of data transfer, and minimizing number of threads needed to avoid stalls (and hence the amount of parallelism required of the program). In practice, some workloads just don't cache well, and there will be long latency operations. Surface shading in 3D graphics is one of those, and that why GPUs evolved to have many threads.
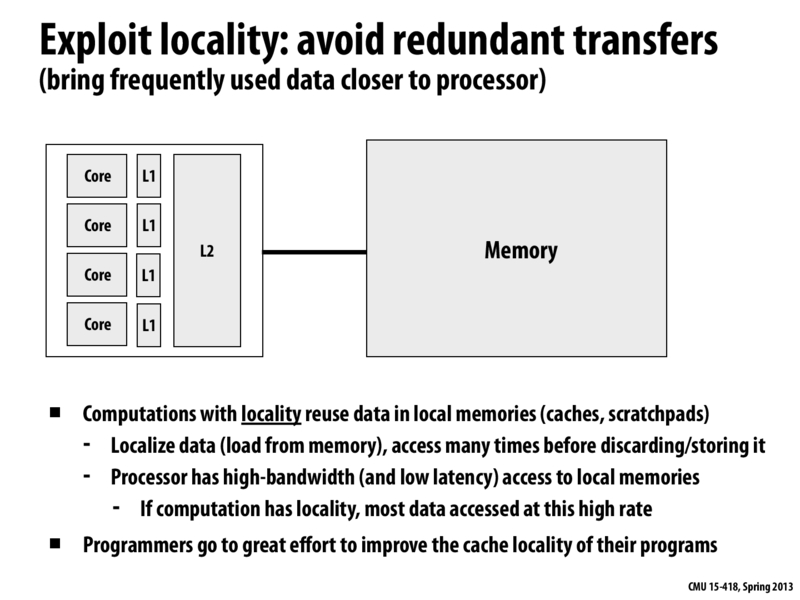
To review, the role of caches in CPUs and GPUs are slightly different. In a CPU, caches are used to minimize latency because there are no other mechanisms to handle it (except for prefetching). In GPUs, where we can handle latency with multi-threading, we still have caches to service requests to avoid going out to the lower-bandwidth memory system.
This comment was marked helpful 0 times.
Yes, the major motivation for caches in a throughput-oriented system such as a GPU is to increase the effective bandwidth to processing elements. If reuse exists, the caches act as a "filter" absorbing many requests before they go out to memory. As a result, the processors receive data at the rate that can be provided by the cache, rather than the rate that can be provided from DRAM.
Of course, a cache hit on a GPU also decreases memory latency as well, and perhaps could allow a program to use fewer threads and still run at full rate.
Here's an interesting thought experiment. Let's say you build a processor with high degree of multi-threading to hide memory latency. But then your processor runs a lot of threads at once, so each thread effective has only a fraction of the cache for its working set. As a result, the threads suffer more cache misses. Since more requires more loads/stores to go out to memory, more latency hiding is necessary to avoid stalls, so the chip designers add more threads... which further decreases cache hit rate. As you can see, there's an interesting feedback loop here.
Ideally, we'd like everything to be served out of caches, minimizing the energy cost of data transfer, and minimizing number of threads needed to avoid stalls (and hence the amount of parallelism required of the program). In practice, some workloads just don't cache well, and there will be long latency operations. Surface shading in 3D graphics is one of those, and that why GPUs evolved to have many threads.
This comment was marked helpful 1 times.