

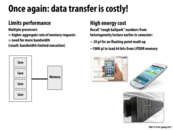

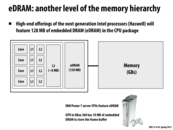

The concept of eDRAM sounds intuitive enough, but why haven't it seen much usage until recent years?
One major reason is the cost to integrate capacitors into the CPU chip. Unlike SRAMs, which are made out of purely transistors, DRAMs are made out of capacitors and transistors. Although small capacitors are cheap to produce and can be densely packed, they become more costly when we need to integrate them into transistor only fabrication processes. This is why until recently, DRAMs have been manufactured independently. However, the gain from a larger bandwidth has motivated this integration nowadays.
Bottom-line: expect eDRAM to be more expensive than DRAM, but provide better performance than conventional DRAM.
This comment was marked helpful 0 times.

Amusingly enough, the Xbox 360's 10 MB of eDRAM isn't enough to hold a full 1280x720 image. Here's a post that's rather critical of the 360's eDRAM.
Overall, this seems to reflect the issues we've seen related to the increasing use of heterogenous hardware. One of these concerns is that it makes software that takes full advantage of the hardware more difficult to write. Another is that balancing the hardware (in this case, the choice of 10 MB) is a very important decision. This is similar to the issues discussed in (lecture 22, slide 28).
This comment was marked helpful 0 times.


This move to start using all directions sort of reminds me of how Intel moved their transistors to be 3D with FinFET and that significantly helped reduce power usage and allowed space to be better utilized. Looking at the Micron website for the memory cube (http://www.micron.com/products/hybrid-memory-cube) something that really stood out to me was the whole "90% less physical space needed for RDIMMs" and "70% less energy per bit compared to DDR3". In a world where companies get excited for a 10% improvement in something, seeing that the hybrid memory cube is advertising this makes me wonder why it didn't get more hype and make it to market already.
This comment was marked helpful 0 times.
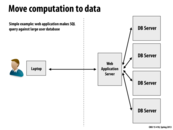

This (data locality) is one of the fundamental principles of Hadoop and its use in Big Data. Of course, as we learned in the previous lecture, forcing data locality (for example, by Hadoop moving all data into HDFS before processing) is not always efficient, especially for graph data. See Hadapt for more information.
This comment was marked helpful 0 times.
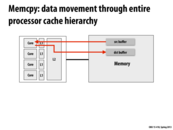


In order to access any data in a row in DRAM, that entire row must first be copied to the row buffer before being sent out on the memory bus. The time this takes is directly related to the CAS latency advertised by DRAM manufacturers. Since this is a critical operation, memory controllers try to optimize the fetching of rows by analyzing the pending memory accesses and reordering them.
This comment was marked helpful 0 times.

Here DRAM will save time that data would not move all around the total cache hierarchy. DRAM gives a better way for memory access than cache.
This comment was marked helpful 0 times.

DRAM are made out of capacitors which will naturally loose charge and need to be refreshed( rewritten). The entire row would be copied into the row buffer and rewritten back into the rows. We can exploit this by arrange the pending read/write out of order such that the request with the row currently inside the row buffer can be executed first.
This comment was marked helpful 0 times.


The reason for wanting to perform the copy of the row without the processor is that moving bits is expensive. The application should move less and the system should move more bits more quickly. The cache hierarchy suggests that we don't use these bits as often.
This comment was marked helpful 0 times.


Since there are fewer memory transactions, this scheme could be useful in systems which worry about power consumption. Less data transfer corresponds to less energy needed per data fetch.
This comment was marked helpful 0 times.

Compressing data may also be motivated by the fact that modern systems are constrained by memory bandwidth and not raw processing power. Since the memory system cannot keep up, it seems logical to burn the CPU time and compress data, since we cannot do much else while waiting for many memory accesses anyway, and potentially get more cache hits.
This comment was marked helpful 0 times.

This reminds me the question 2 in the final exam that the bottleneck of memory transfer is quite an issue when there are several stages of computation. If data transferring is too slow, the next stage cannot do anything except for waiting.
There are two obvious ways to handle this. one is to pipelining the computation in the next stage with the memory access, which hides the latency. But if the computation time is smaller than memory access time, it would not work. The other way is data compression, which actually reduces transfer time, and seems more effective in general cases.
This comment was marked helpful 0 times.

Though you could do a min, max over all entries in the cache line, the extra overhead to do any evaluation to find a good base is not necessarily worth it. Using the first addresses base address in the cache often works just fine, and does not require any additional complex logic.
This comment was marked helpful 0 times.

This pattern is problematic because there is no one base that would result in efficient compression for a significant majority of the values.
This comment was marked helpful 0 times.



The compression ratio decreases after a certain amount of bases(2 or 3) because as more bases are stored, the amount of compression that can be done decreases.
This comment was marked helpful 0 times.

From frame to frame, some part of the images does not change or only change a little. For example, the white sky background in the top picture is not likely to change often. Therefore, one way to lower energy consumption is to not render these frames is the portion of the images is similar enough compared to previous frame.
This comment was marked helpful 0 times.

In order to reduce the number of writes the GPU does, between frames the GPU checks if a frame tile has changed or not. If it has changed, it writes to it. Otherwise, it doesn't need to write and can skip that costly operation. The pictures in the slide show which frame tiles were written to (changed from the previous frame) by highlighting them in red. As the slide points out, even when the camera moves quickly, about half the writes can be avoided as they don't actually change.
This comment was marked helpful 0 times.

The idea here is that in many video applications, most of the screen doesn't change. The trick we use is to simply not do a write if we know that the tile isn't going to change. We can determine this by comparing the hash of the tile in the first frame vs the hash of the tile in the second frame. This saves us a huge percentage of writes, even where the video appears to be changing a lot (second image) which in turn saves bandwidth. In exchange, we need to do a little bit of extra computation (compare hashes), just as with the cache compression we looked at earlier.
This comment was marked helpful 0 times.









To review, the role of caches in CPUs and GPUs are slightly different. In a CPU, caches are used to minimize latency because there are no other mechanisms to handle it (except for prefetching). In GPUs, where we can handle latency with multi-threading, we still have caches to service requests to avoid going out to the lower-bandwidth memory system.
This comment was marked helpful 0 times.
Yes, the major motivation for caches in a throughput-oriented system such as a GPU is to increase the effective bandwidth to processing elements. If reuse exists, the caches act as a "filter" absorbing many requests before they go out to memory. As a result, the processors receive data at the rate that can be provided by the cache, rather than the rate that can be provided from DRAM.
Of course, a cache hit on a GPU also decreases memory latency as well, and perhaps could allow a program to use fewer threads and still run at full rate.
Here's an interesting thought experiment. Let's say you build a processor with high degree of multi-threading to hide memory latency. But then your processor runs a lot of threads at once, so each thread effective has only a fraction of the cache for its working set. As a result, the threads suffer more cache misses. Since more requires more loads/stores to go out to memory, more latency hiding is necessary to avoid stalls, so the chip designers add more threads... which further decreases cache hit rate. As you can see, there's an interesting feedback loop here.
Ideally, we'd like everything to be served out of caches, minimizing the energy cost of data transfer, and minimizing number of threads needed to avoid stalls (and hence the amount of parallelism required of the program). In practice, some workloads just don't cache well, and there will be long latency operations. Surface shading in 3D graphics is one of those, and that why GPUs evolved to have many threads.
This comment was marked helpful 1 times.