The ideal speedup has a slope of 1. Every time we add a processor, we expect the best time we can accomplish is the number of processors we currently have, multiplied by the best time we can achieve in single core execution. This isn't always the case, however, which leads to a speedup that is better than the ideal, called super-linear speedup. Contributing factors that can lead to a super-linear speedup involve utilization of the cache. Every time we add a processor (assuming each new core comes with its own L1 cache), the amount of aggregate L1 cache present in the system increases. The program's working set might be too large to fit in a single core's cache. However, when splitting the work up among many processors, the working set can be split up into chunks that can potentially be small enough to fit into each core's cache. As a result, execution of each core involves fewer cache misses than execution on a single core.
In the graph, we can see that between 8 and 16 processors, the working sets are likely split up enough that the data can be cached, thus causing the graph to become non-linear.
This comment was marked helpful 0 times.
Incanam
There was a question in class about what the "ideal" line measures, and is it "ideal enough" because it doesn't make sense the speedup to be more than ideal. Basically, the ideal speedup line assumes that everything else about the machine will scale as we increase the number of processors. As @max mentioned, the number of cache misses doesn't necessarily do that (it actually goes down).
In general, I understand what the line is trying to communicate, but I think ideal is a bad name for it. Theoretical speedup might be a better name. Sort of analagous to inherent communication and artifactual communication, the line doesn't take into account the interaction between the application and the system.
This comment was marked helpful 0 times.
kayvonf
@Incanam: Good comment, but I'm not sure what you meant by "everything else about the machine will scale as we increase the number of processors". How I'd say is this: The "ideal" line on the graph corresponds to an intuitive notion of the speedup you'd expect to observe if the application was perfectly parallelized onto N processors. That is, in theory (not considering any low-level details of the system's implementation) if you took a program and perfectly distributed its work to N cores (perfect workload balance, no overhead of communication, synchronization, etc.), it is logical to expect to speed up execution by a factor of N.
This graph shows that in practice, sometimes you might observe a greater than N speedup. In this case, the reason is the caching behavior that @max and @Incanam have nicely explained above. Of course, there might be other reasons for a super-linear speedup as well.
Question: Many of you have observed a superlinear speedup for certain configurations on Assignment 3. This superlinear speedup is not due to caching behavior. What might it be?
This comment was marked helpful 0 times.
xiaowend
One possible reason is pruning. While doing DFS for WSP, shorter path found may cause more pruning and less calculation in later searching. For example, in shared memory model, if there exists a shortest path beginning with 2, and we do the two branches beginning with 1 and 2 simultaneously? the shortest path may reduce workload in the first branch, thus reduce total workload.
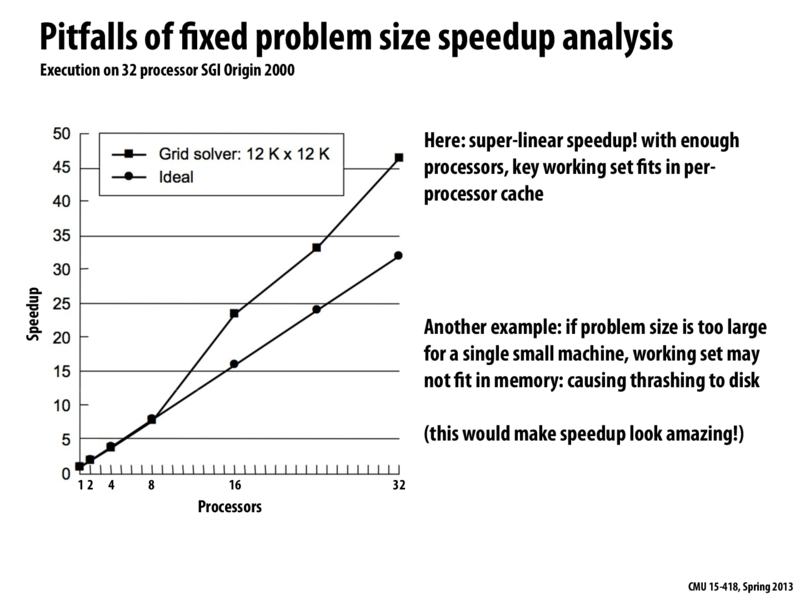
The ideal speedup has a slope of 1. Every time we add a processor, we expect the best time we can accomplish is the number of processors we currently have, multiplied by the best time we can achieve in single core execution. This isn't always the case, however, which leads to a speedup that is better than the ideal, called super-linear speedup. Contributing factors that can lead to a super-linear speedup involve utilization of the cache. Every time we add a processor (assuming each new core comes with its own L1 cache), the amount of aggregate L1 cache present in the system increases. The program's working set might be too large to fit in a single core's cache. However, when splitting the work up among many processors, the working set can be split up into chunks that can potentially be small enough to fit into each core's cache. As a result, execution of each core involves fewer cache misses than execution on a single core.
In the graph, we can see that between 8 and 16 processors, the working sets are likely split up enough that the data can be cached, thus causing the graph to become non-linear.
This comment was marked helpful 0 times.
There was a question in class about what the "ideal" line measures, and is it "ideal enough" because it doesn't make sense the speedup to be more than ideal. Basically, the ideal speedup line assumes that everything else about the machine will scale as we increase the number of processors. As @max mentioned, the number of cache misses doesn't necessarily do that (it actually goes down).
In general, I understand what the line is trying to communicate, but I think ideal is a bad name for it. Theoretical speedup might be a better name. Sort of analagous to inherent communication and artifactual communication, the line doesn't take into account the interaction between the application and the system.
This comment was marked helpful 0 times.
@Incanam: Good comment, but I'm not sure what you meant by "everything else about the machine will scale as we increase the number of processors". How I'd say is this: The "ideal" line on the graph corresponds to an intuitive notion of the speedup you'd expect to observe if the application was perfectly parallelized onto N processors. That is, in theory (not considering any low-level details of the system's implementation) if you took a program and perfectly distributed its work to N cores (perfect workload balance, no overhead of communication, synchronization, etc.), it is logical to expect to speed up execution by a factor of N.
This graph shows that in practice, sometimes you might observe a greater than N speedup. In this case, the reason is the caching behavior that @max and @Incanam have nicely explained above. Of course, there might be other reasons for a super-linear speedup as well.
Question: Many of you have observed a superlinear speedup for certain configurations on Assignment 3. This superlinear speedup is not due to caching behavior. What might it be?
This comment was marked helpful 0 times.
One possible reason is pruning. While doing DFS for WSP, shorter path found may cause more pruning and less calculation in later searching. For example, in shared memory model, if there exists a shortest path beginning with 2, and we do the two branches beginning with 1 and 2 simultaneously? the shortest path may reduce workload in the first branch, thus reduce total workload.
This comment was marked helpful 2 times.