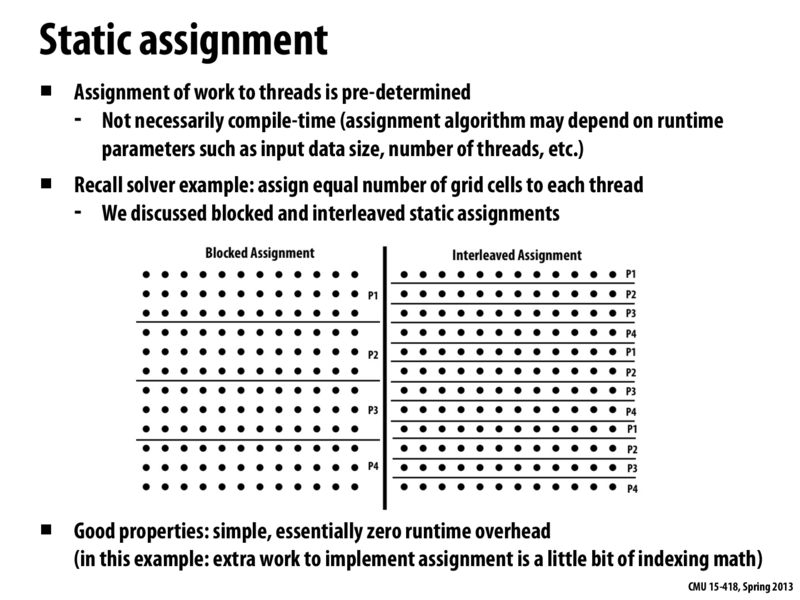
As mentioned in lecture, static assignment is perfect when workloads have predictable cost. There is certainty before the work actually starts, that the work loads will remain balanced. The cores that are assigned work will all finish about the same time without any work needing to be reallocated after the work starts.
Note: Predictable doesn't mean that you know exactly how long each sub-problem will take. For example, for the square-root problem in homework 1, it was random how long finding the square root of a number would take. But in expectation, the work was split up evenly so static assignment was appropriate.
This comment was marked helpful 0 times.
kayvonf
Question: Here I claim that the static assignment has "essentially zero" runtime overhead. What did it mean by this? When I say overhead, what is the baseline that I am comparing to? In slide 26 introduce the idea of dynamic assignment. What is the "overhead" of performing a dynamic assignment of work to worker threads in that example?
This comment was marked helpful 0 times.
bosher
I believe that the baseline we are comparing to here is the sequential version of the algorithm. In the sequential version, every task is picked up when the previous one is done, and hence the processor is always doing useful works. In the static assignment version, each processor are assigned a static amount of work. In other words, for each processor, it is essentially performing the sequential algorithm, which, as we just mentioned, has (nearly) no overhead. And therefore, the only overhead involved in the static assignment version is the work spent for setting up a multi-thread environment to run the code and the time spent for exchanging information between threads. And this overhead can be ignored if the tasks assigned to each thread are large enough. In the dynamic assignment version, the overhead could be two things: (1) the time spent for the function calls to $lock$ and $unlock$; (2) the time spent for waiting the lock. For the first kind of overhead, it depends on implementation of the lock. If the lock contains several system calls, we may need to trap into kernel mode multiple times, which is costly. For the second kind of overhead, since at any given time, there can be only one thread inside the critical section, other threads that want to increment the counter can do nothing but wait for the lock, which is also costly.
As mentioned in lecture, static assignment is perfect when workloads have predictable cost. There is certainty before the work actually starts, that the work loads will remain balanced. The cores that are assigned work will all finish about the same time without any work needing to be reallocated after the work starts.
Note: Predictable doesn't mean that you know exactly how long each sub-problem will take. For example, for the square-root problem in homework 1, it was random how long finding the square root of a number would take. But in expectation, the work was split up evenly so static assignment was appropriate.
This comment was marked helpful 0 times.
Question: Here I claim that the static assignment has "essentially zero" runtime overhead. What did it mean by this? When I say overhead, what is the baseline that I am comparing to? In slide 26 introduce the idea of dynamic assignment. What is the "overhead" of performing a dynamic assignment of work to worker threads in that example?
This comment was marked helpful 0 times.
I believe that the baseline we are comparing to here is the sequential version of the algorithm. In the sequential version, every task is picked up when the previous one is done, and hence the processor is always doing useful works. In the static assignment version, each processor are assigned a static amount of work. In other words, for each processor, it is essentially performing the sequential algorithm, which, as we just mentioned, has (nearly) no overhead. And therefore, the only overhead involved in the static assignment version is the work spent for setting up a multi-thread environment to run the code and the time spent for exchanging information between threads. And this overhead can be ignored if the tasks assigned to each thread are large enough. In the dynamic assignment version, the overhead could be two things: (1) the time spent for the function calls to $lock$ and $unlock$; (2) the time spent for waiting the lock. For the first kind of overhead, it depends on implementation of the lock. If the lock contains several system calls, we may need to trap into kernel mode multiple times, which is costly. For the second kind of overhead, since at any given time, there can be only one thread inside the critical section, other threads that want to increment the counter can do nothing but wait for the lock, which is also costly.
This comment was marked helpful 2 times.
In a reasonable implementation, a mutex lock/unlock takes ~17ns. From Latency Numbers Every Programmer Should Know.
This comment was marked helpful 2 times.