I think a way to reduce the overhead of synchronization could be to use the idea of "try_lock". We can keep a global number of how many tasks, in average, are left in each of the processor's work queue. Then, when a processor finds out that the tasks left in its work queue are less than the average, it will try to steal some tasks from other processors. However, as the idea of "try_lock" suggests, this processor will just attempt to acquire the lock of other processor's work queue once. If it succeeds, it will steal some tasks. If the lock is currently acquired by other processors, it will give up immediately and back to do its own task - and try to steal tasks later. For those processors that have more tasks to do than average, they will not even try to steal but focus on finishing their own tasks.
This design can answer the question of "how much tasks to steal" - just steal up to average. Also, we can do useful work when we need to wait for the lock, which, in some sense, reduce the overhead of synchronization (think increasing granularity). However, this design also have problems. We need extra work to update the average tasks. And we need even more work to determine who to steal from. And most importantly, processor may be starved because there is no guarantee that it will eventually get the lock.
This comment was marked helpful 1 times.
kailuo
I think the distributed work queues approach shares the same problem with the smart task scheduling approach mentioned in the next slide. In order to determine how much to steal in the distributed work queues approach, the processor need some notion of how much workload each task provides, and steal only enough work to keep itself busy. If we record a global average task count as suggested by @bosher, and keep stealing to keep an average number of tasks to do, we will find ourselves over-stealing/under-stealing in terms of workload, and the result would be tossing tasks back and forth between processors, which is expensive given the synchronization overheads. Similarly, the crucial component of implementing a smart task scheduler is to know the workload of each task beforehand (or at least come up with a fairly good prediction), and schedule the heavy tasks first.
This comment was marked helpful 0 times.
kfc9001
@bosher The problem with only using try_lock is that you might end up with starvation: a processor that consistently has a lot less work than others can keep trying to steal work, but keep failing because try_lock doesn't ensure bounded waiting (i.e. there is no guarantee that the processor will ever succeed in getting more work). If you take this to the extreme, you could have many processors sitting around doing nothing, repeatedly trying to use try_lock, and consistently failing (perhaps due to how the lock is implemented). Then you aren't make good use of those processors at all, and it might have been worth using normal locks and incurring the cost of communication overhead, because at least you won't be letting processors sit idle (and thus decreasing total execution time).
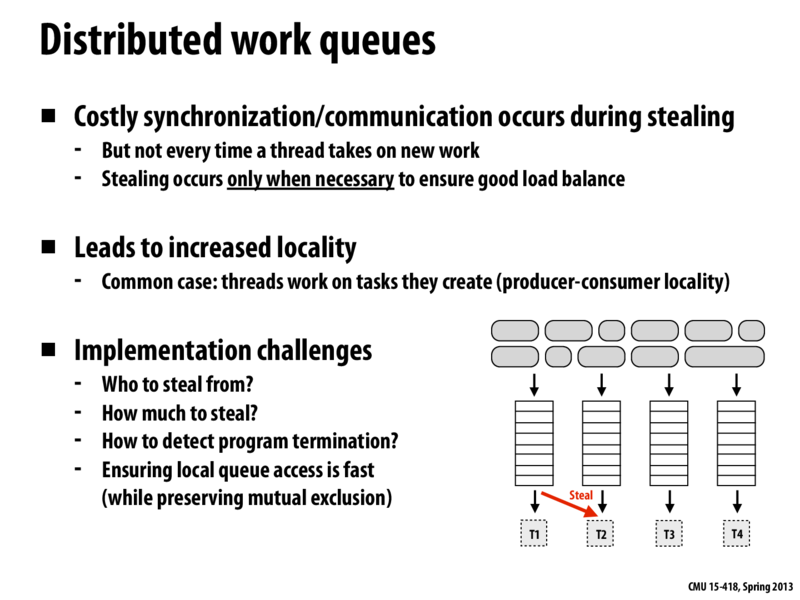
I think a way to reduce the overhead of synchronization could be to use the idea of "try_lock". We can keep a global number of how many tasks, in average, are left in each of the processor's work queue. Then, when a processor finds out that the tasks left in its work queue are less than the average, it will try to steal some tasks from other processors. However, as the idea of "try_lock" suggests, this processor will just attempt to acquire the lock of other processor's work queue once. If it succeeds, it will steal some tasks. If the lock is currently acquired by other processors, it will give up immediately and back to do its own task - and try to steal tasks later. For those processors that have more tasks to do than average, they will not even try to steal but focus on finishing their own tasks. This design can answer the question of "how much tasks to steal" - just steal up to average. Also, we can do useful work when we need to wait for the lock, which, in some sense, reduce the overhead of synchronization (think increasing granularity). However, this design also have problems. We need extra work to update the average tasks. And we need even more work to determine who to steal from. And most importantly, processor may be starved because there is no guarantee that it will eventually get the lock.
This comment was marked helpful 1 times.
I think the distributed work queues approach shares the same problem with the smart task scheduling approach mentioned in the next slide. In order to determine how much to steal in the distributed work queues approach, the processor need some notion of how much workload each task provides, and steal only enough work to keep itself busy. If we record a global average task count as suggested by @bosher, and keep stealing to keep an average number of tasks to do, we will find ourselves over-stealing/under-stealing in terms of workload, and the result would be tossing tasks back and forth between processors, which is expensive given the synchronization overheads. Similarly, the crucial component of implementing a smart task scheduler is to know the workload of each task beforehand (or at least come up with a fairly good prediction), and schedule the heavy tasks first.
This comment was marked helpful 0 times.
@bosher The problem with only using try_lock is that you might end up with starvation: a processor that consistently has a lot less work than others can keep trying to steal work, but keep failing because try_lock doesn't ensure bounded waiting (i.e. there is no guarantee that the processor will ever succeed in getting more work). If you take this to the extreme, you could have many processors sitting around doing nothing, repeatedly trying to use try_lock, and consistently failing (perhaps due to how the lock is implemented). Then you aren't make good use of those processors at all, and it might have been worth using normal locks and incurring the cost of communication overhead, because at least you won't be letting processors sit idle (and thus decreasing total execution time).
This comment was marked helpful 0 times.